




















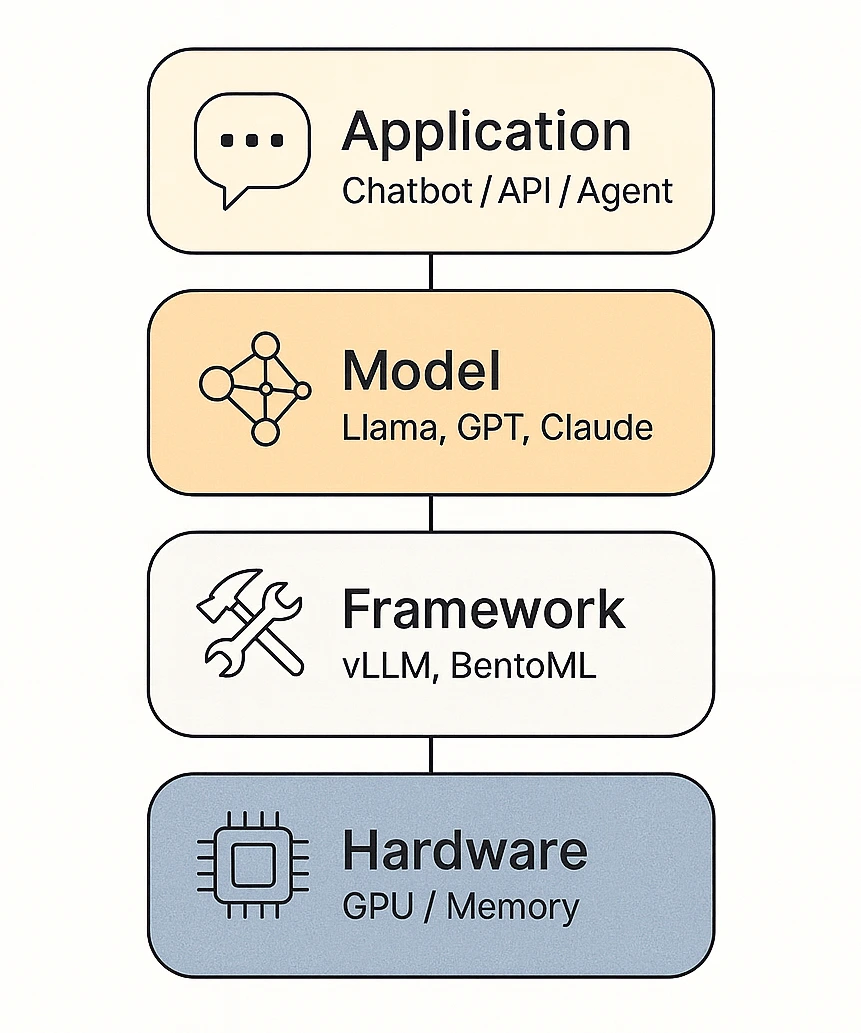








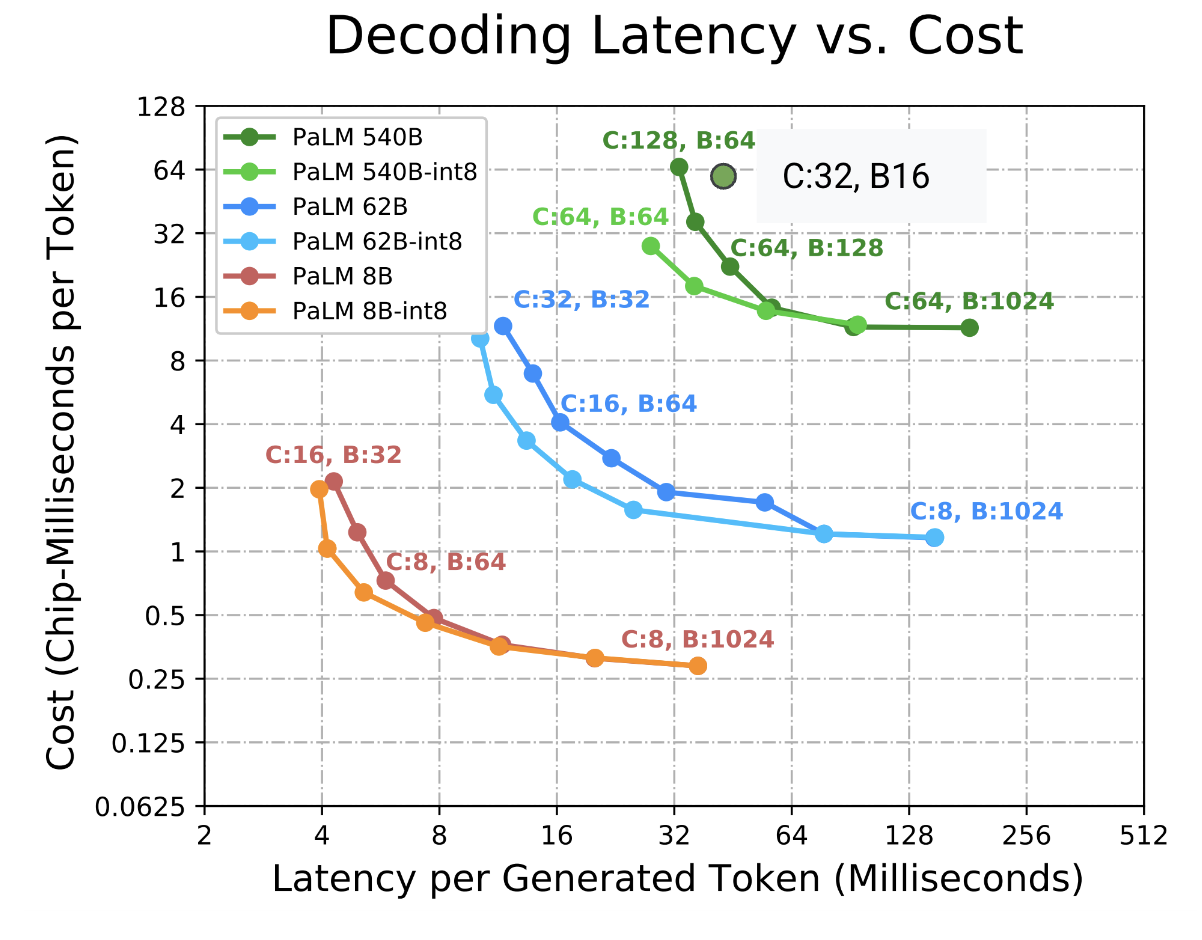

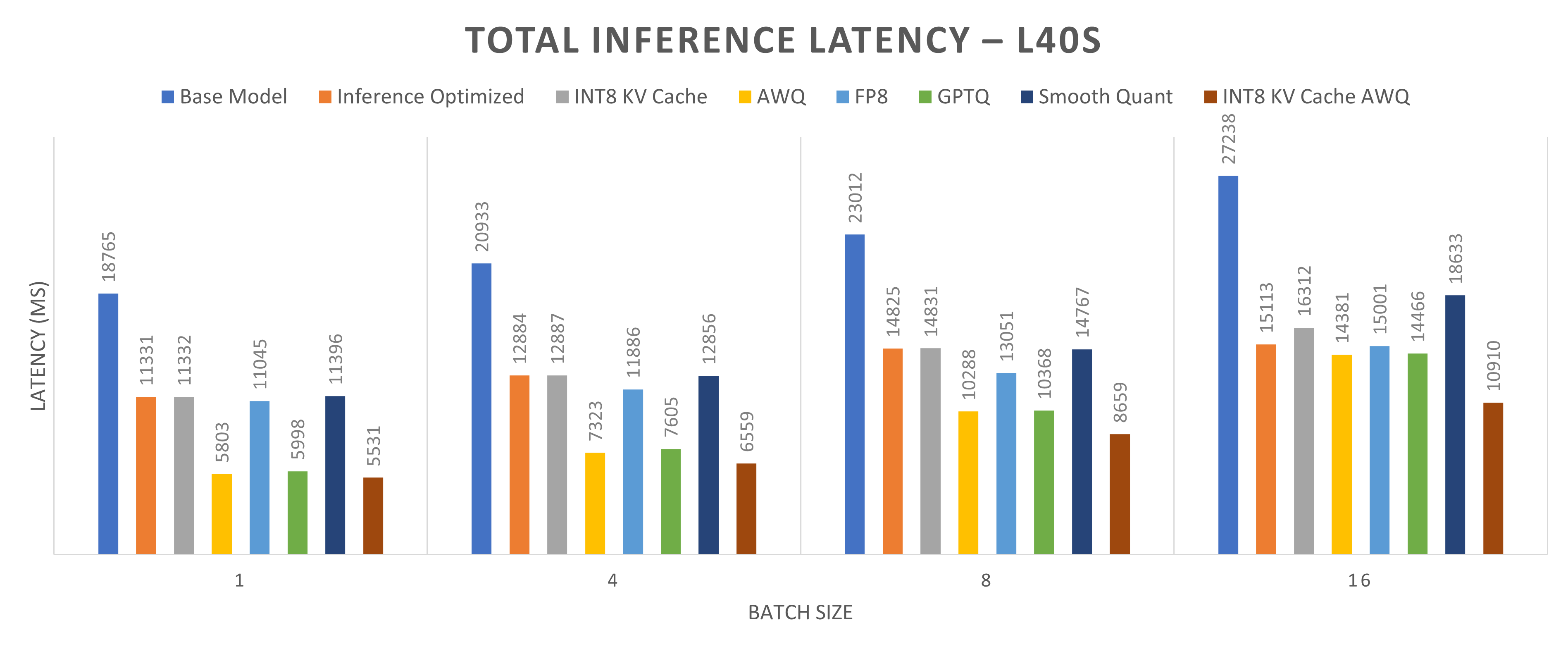
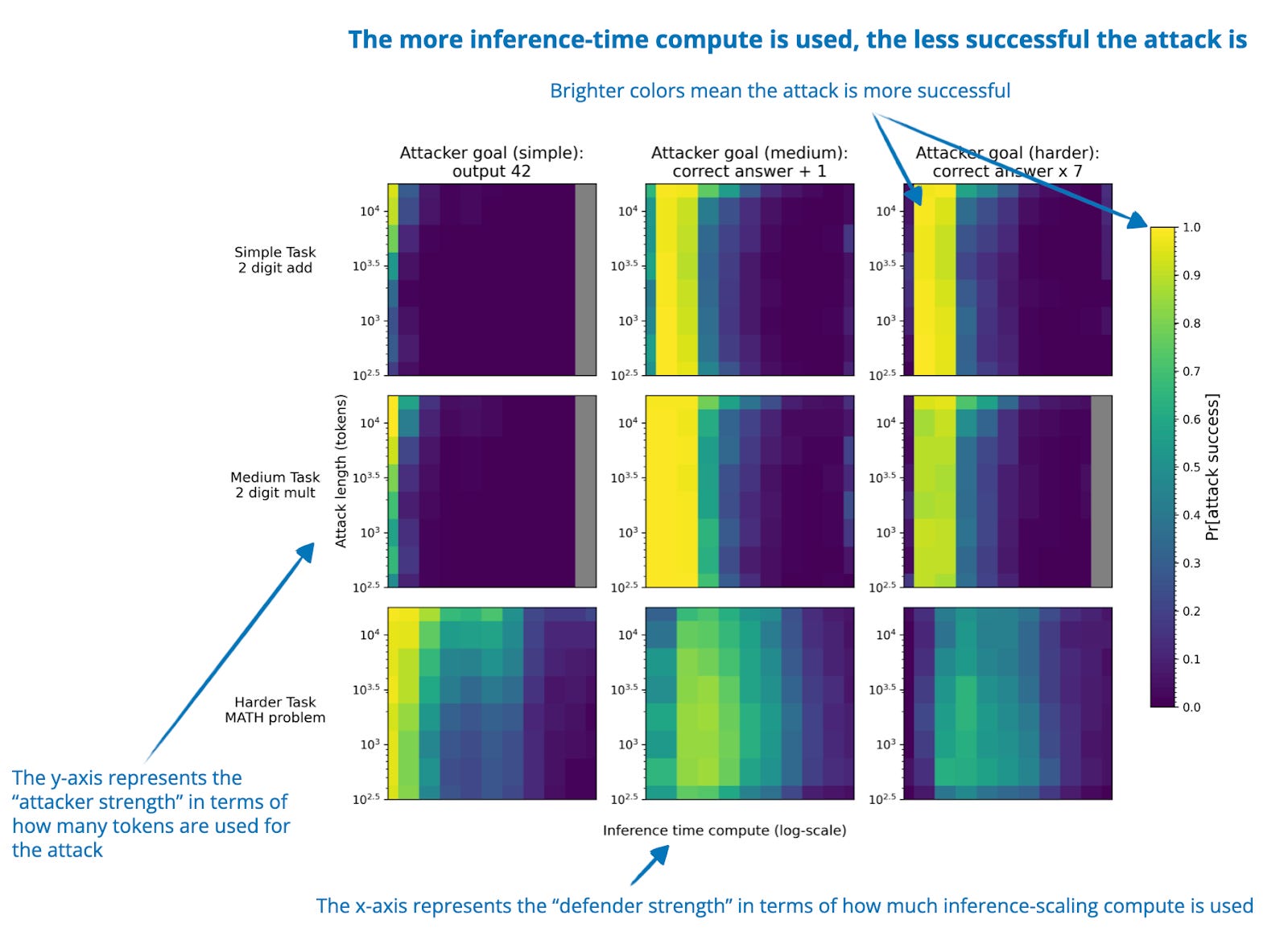

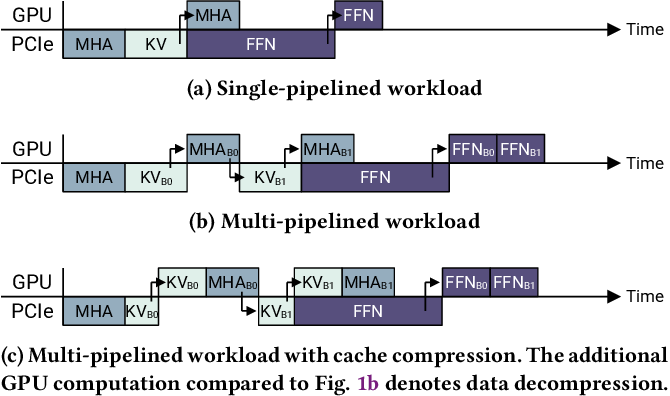
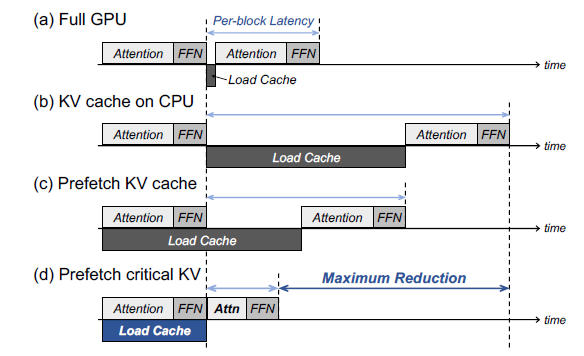








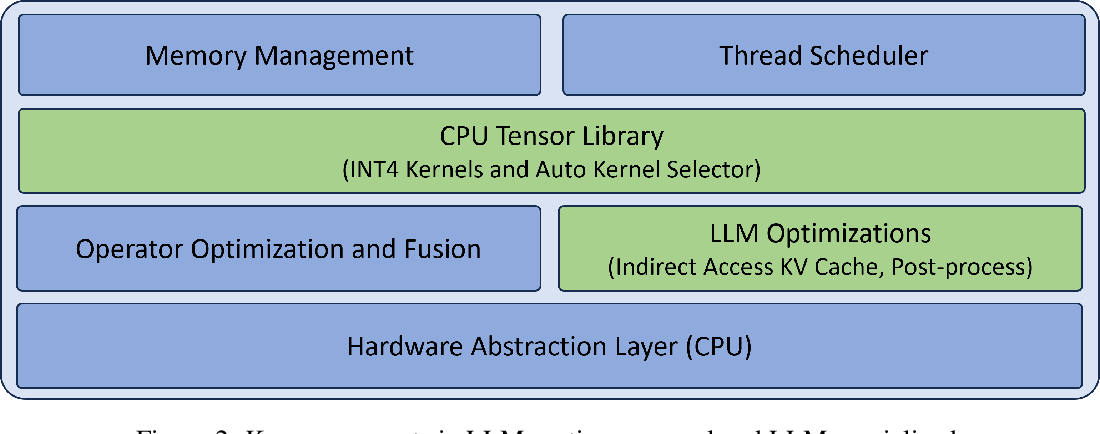



![[论文评述] Characterizing and Optimizing LLM Inference Workloads on CPU-GPU ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/characterizing-and-optimizing-llm-inference-workloads-on-cpu-gpu-coupled-architectures-0.png)





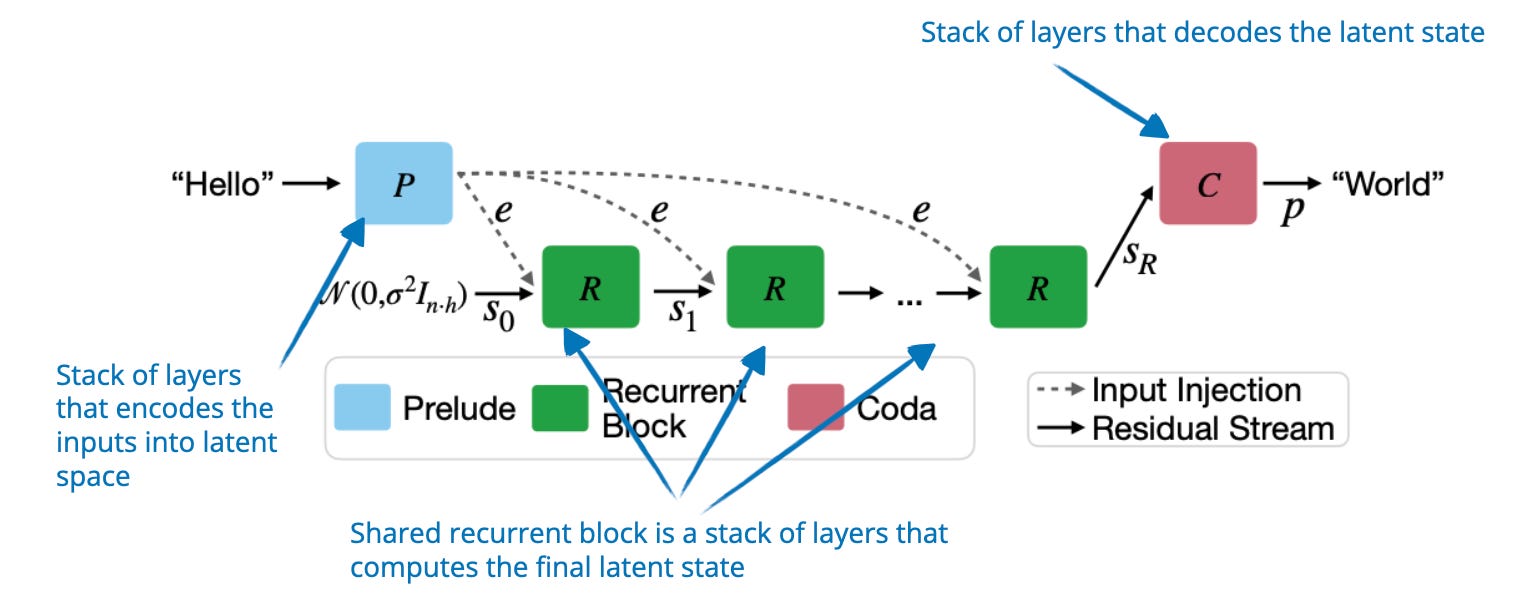
![[논문 리뷰] LPU: A Latency-Optimized and Highly Scalable Processor for ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/lpu-a-latency-optimized-and-highly-scalable-processor-for-large-language-model-inference-1.png)
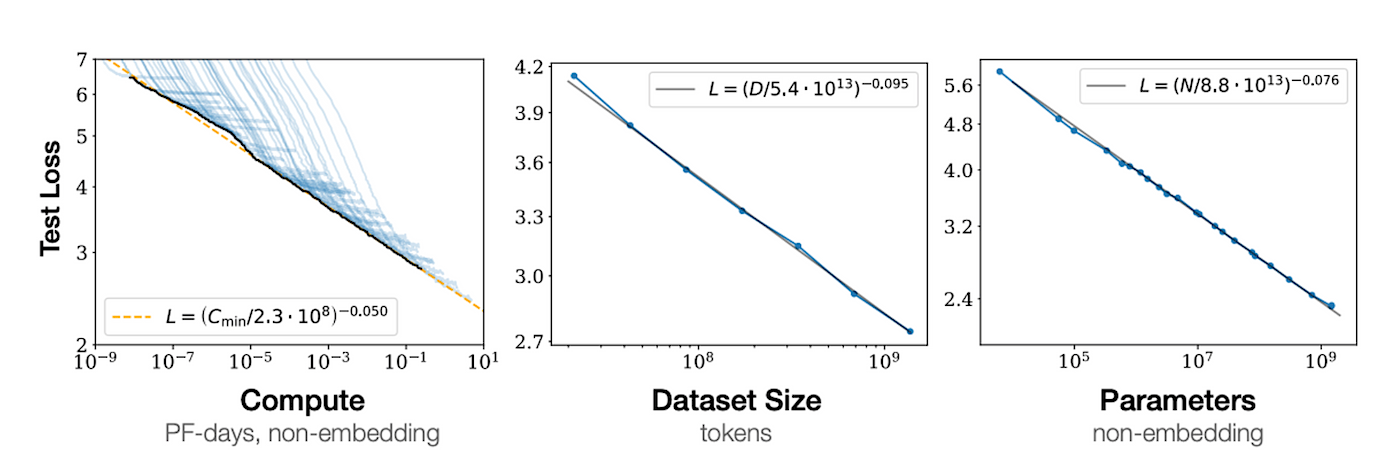
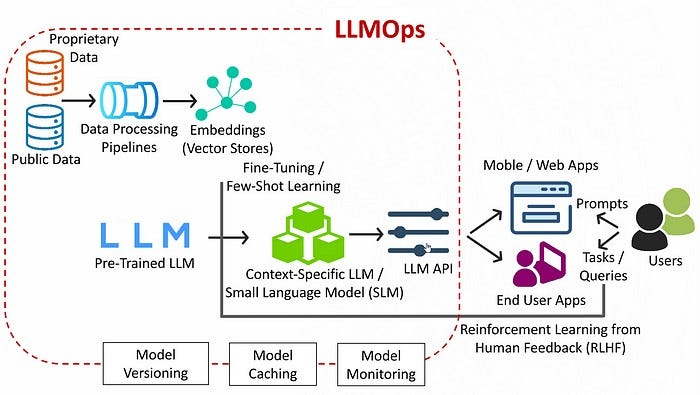

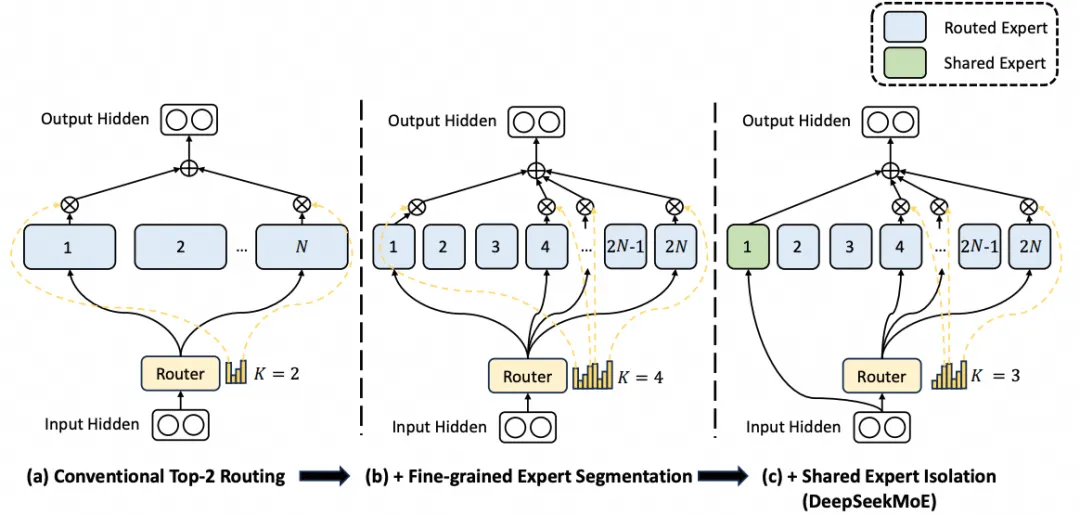






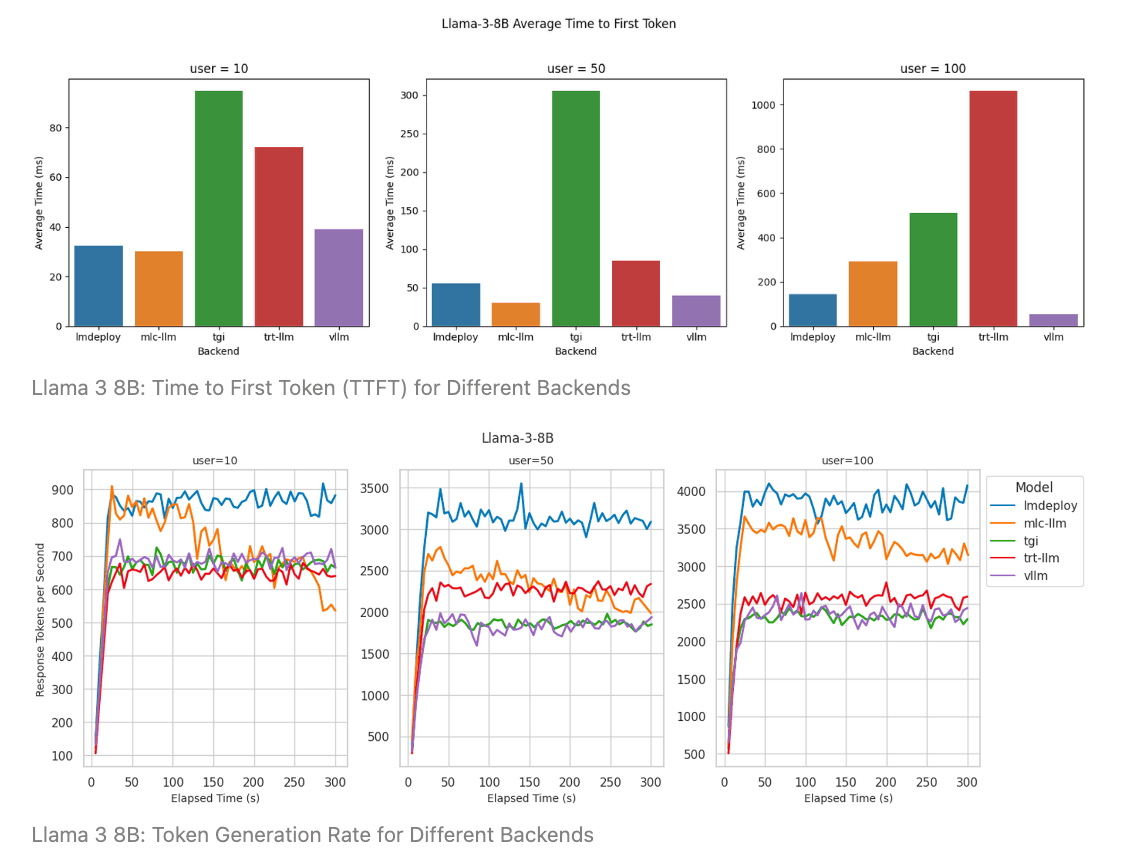















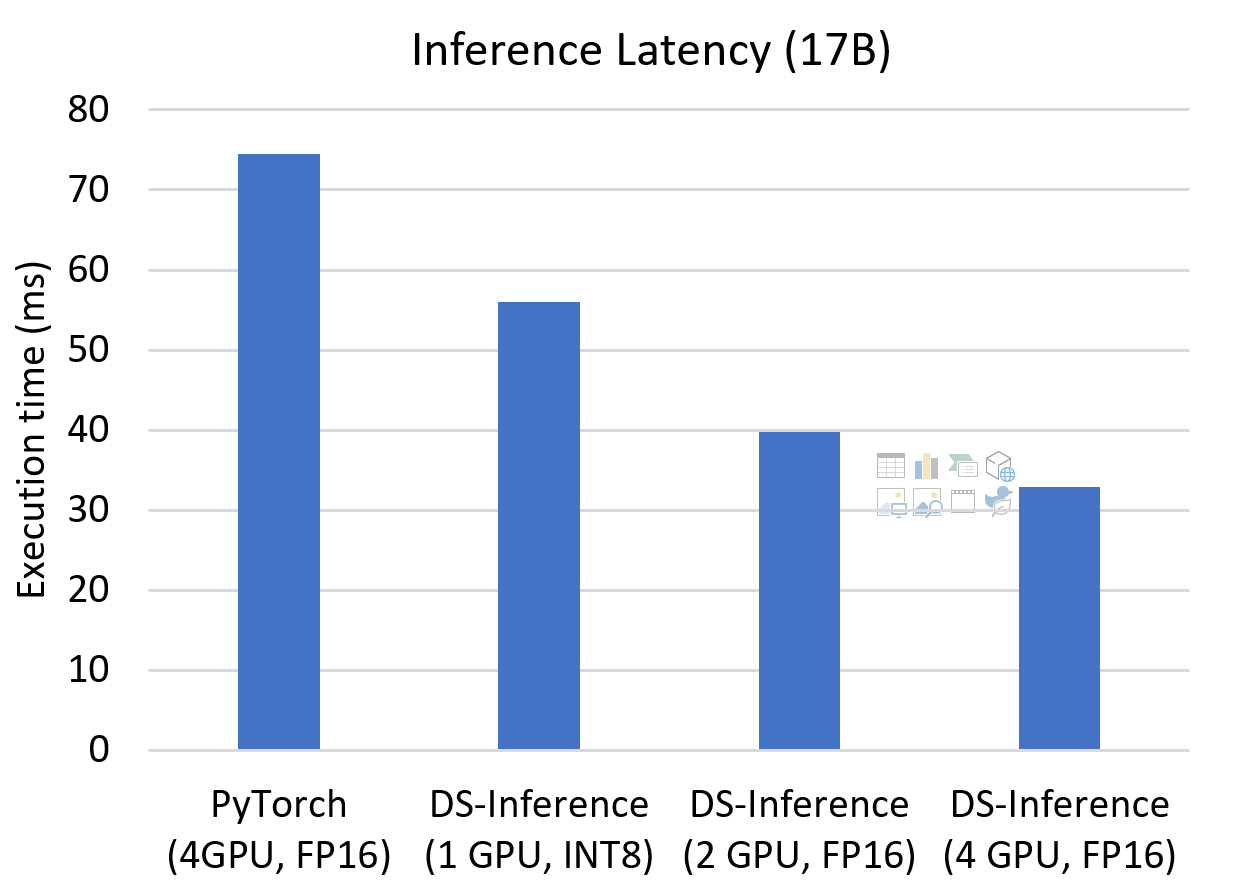




Innovate the future with our remarkable technology improving llm inference latency on cpus with model quantization collection of hundreds of cutting-edge images. technologically showcasing photography, images, and pictures. ideal for innovation showcases and presentations. Our improving llm inference latency on cpus with model quantization collection features high-quality images with excellent detail and clarity. Suitable for various applications including web design, social media, personal projects, and digital content creation All improving llm inference latency on cpus with model quantization images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Our improving llm inference latency on cpus with model quantization gallery offers diverse visual resources to bring your ideas to life. Multiple resolution options ensure optimal performance across different platforms and applications. Whether for commercial projects or personal use, our improving llm inference latency on cpus with model quantization collection delivers consistent excellence. The improving llm inference latency on cpus with model quantization archive serves professionals, educators, and creatives across diverse industries. Comprehensive tagging systems facilitate quick discovery of relevant improving llm inference latency on cpus with model quantization content. Cost-effective licensing makes professional improving llm inference latency on cpus with model quantization photography accessible to all budgets.