Please enter url.
Login
Logout
Please enter url.
Understanding Visual Question Answering - VQA - viso.ai
viso.ai
source
Comments
Figure 1 from Multi-Modal Correlated Network with Emotional Reasoning ...
GitHub - Gary-code/KETG-paper-reading: 😎 基于知识的文本生成相关文章总结与个人笔记
Figure 1 from Open-Vocabulary Object Detection via Scene Graph ...
Example of MTLE-based video captioning. Ground truth captions are ...
Characterization of domain shift and comparison of supervised domain ...
Figure 1 from Cross-Modal Label Contrastive Learning for Unsupervised ...
Zehan Wang - Homepage
(PDF) Cross-modal Moment Localization in Videos
Genre prediction and Transition detection pipeline. | Download ...
A Low Cost Vehicle Localization System based on HD Map | by Yu Huang ...
[2009.00893] PCPL: Predicate-Correlation Perception Learning for ...
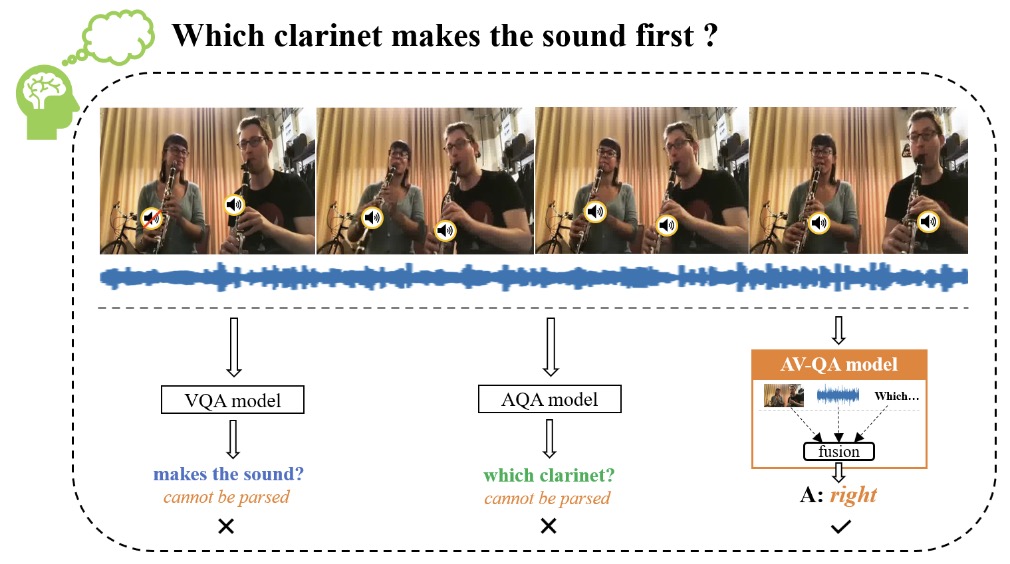
[PDF] A Multi-Modal Context Reasoning Approach for Conditional ...
Ziwei Liu - Publications
Multi-stage research process to preserve the Ladin language. This paper ...
(PDF) Speech Gesture Generation from the Trimodal Context of Text ...
Examples on the R-VQA dataset. For each imagequestion-answer pair, the ...
Figure 2 from Towards Lexical Analysis of Dog Vocalizations via Online ...
An overview of the Feature Reuse and Fusion for real-time semantic ...
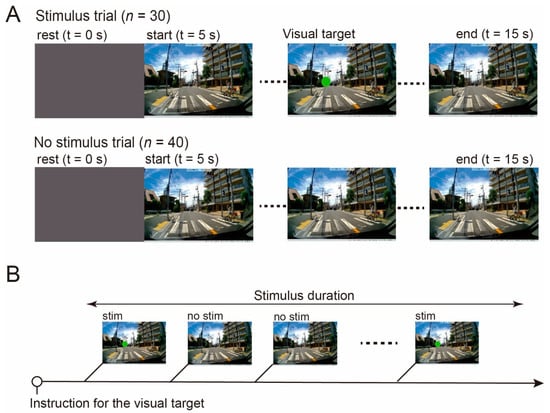
Indirect visual memory modulation experimental design (A) Participants ...
IJERPH | Free Full-Text | The Effects of Driving Experience on the P300 ...
Illustration of missing modality in testing when applying the trained ...
Figure 1 from Learning to Dehaze From Realistic Scene with A Fast ...
Automated system teaches users when to collaborate with an AI assistant
Publications
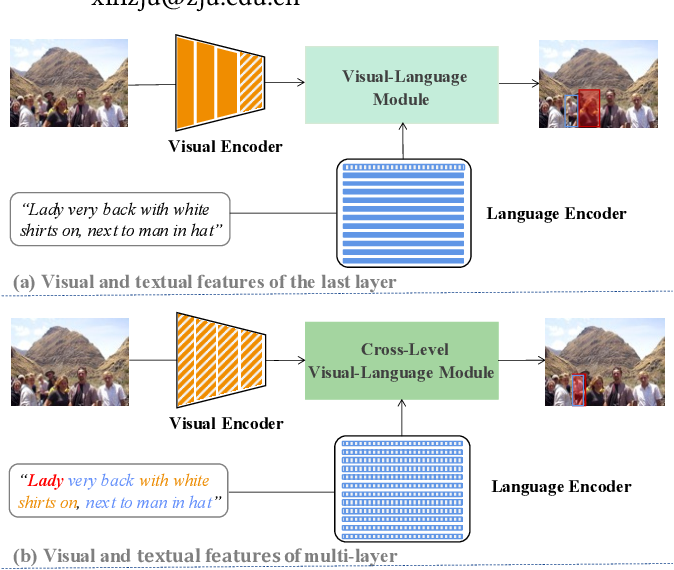
Figure 1 from Referring Expression Comprehension via Cross-Level Multi ...
Sheng Jin's Homepage
Word2vector Principles of Sina Weibo Text. | Download Scientific Diagram
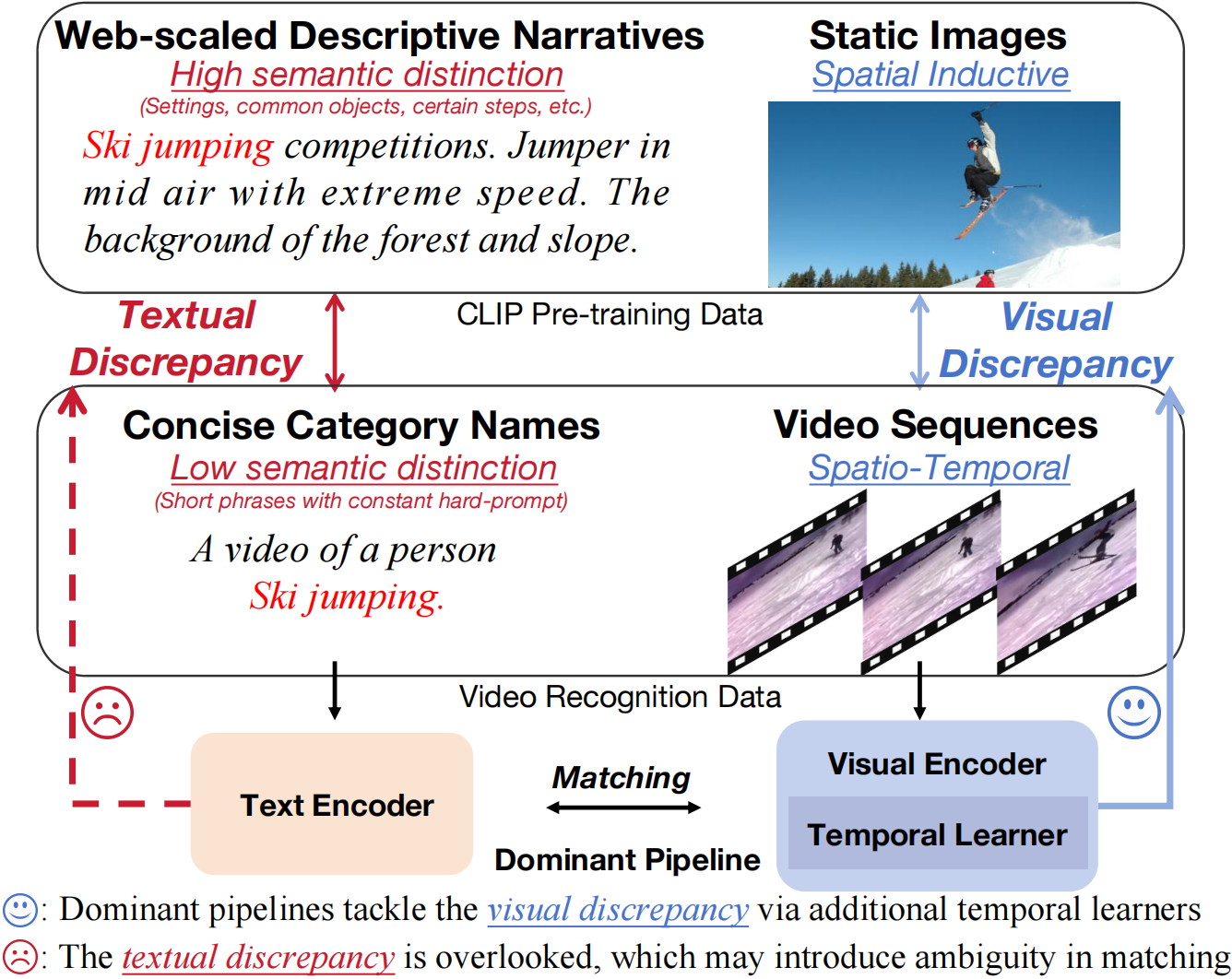
OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor ...
Difference between one-pass decoding process in the existing methods ...
Mohammad M. Derakhshani
Jianmin Bao - Homepage
Introduction to the representation task | Download Scientific Diagram
Network diagram of GAMa-Net proposed for clip-level geo-localization ...
The flowchart of LGBM forecast model with Bayesian optimization ...
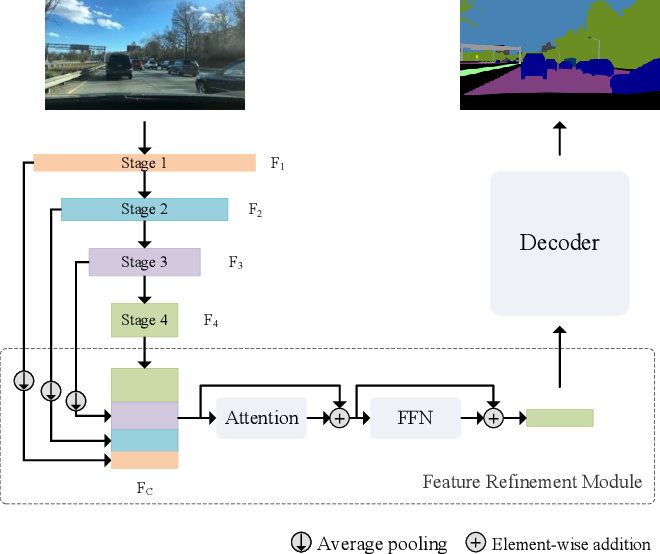
Figure 1 from A Feature Refinement Module for Light-Weight Semantic ...


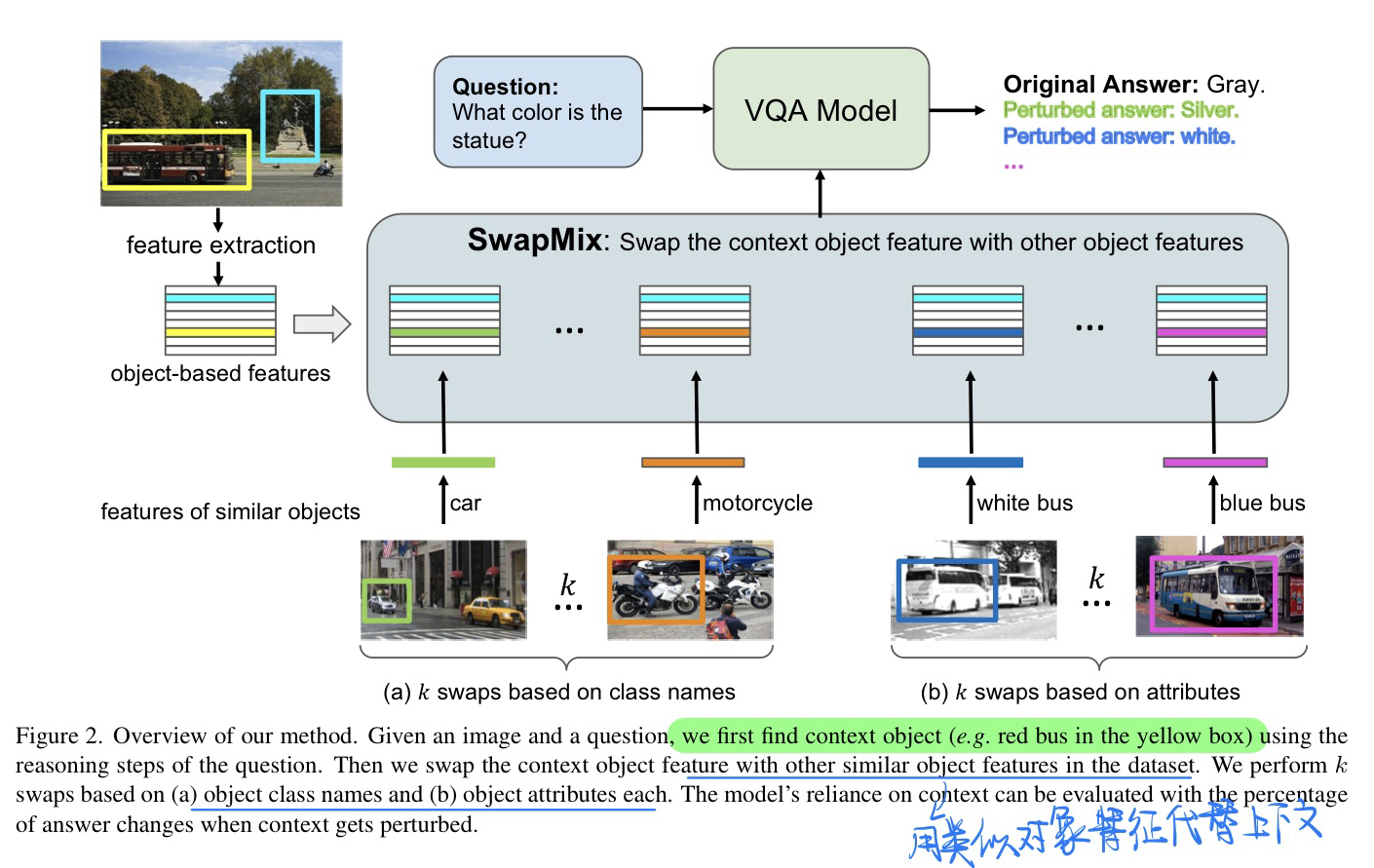






![[2009.00893] PCPL: Predicate-Correlation Perception Learning for ...](https://ar5iv.labs.arxiv.org/html/2009.00893/assets/figure/figure1/figure1.png)
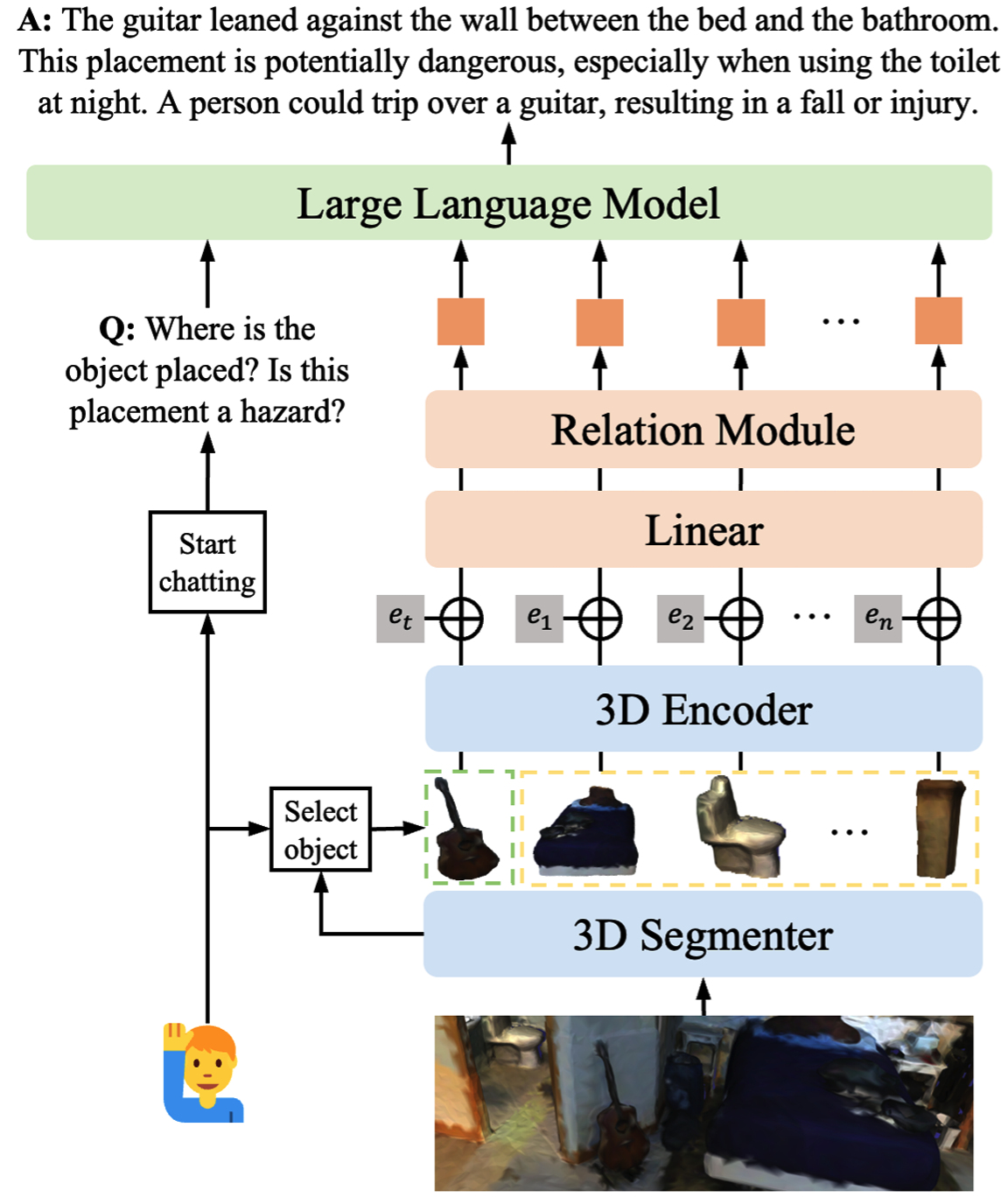
![[PDF] A Multi-Modal Context Reasoning Approach for Conditional ...](https://d3i71xaburhd42.cloudfront.net/cd633e08340e13ca25e9b663ef0b5366b3e032be/1-Figure1-1.png)