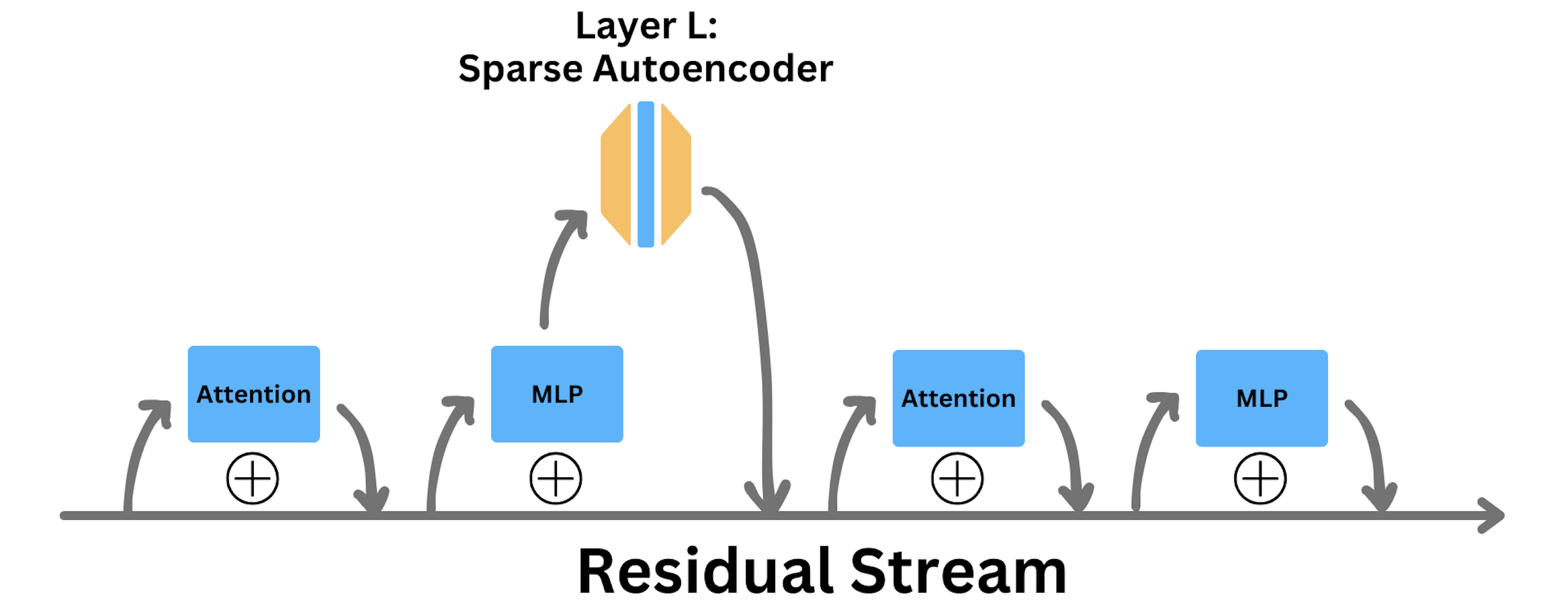



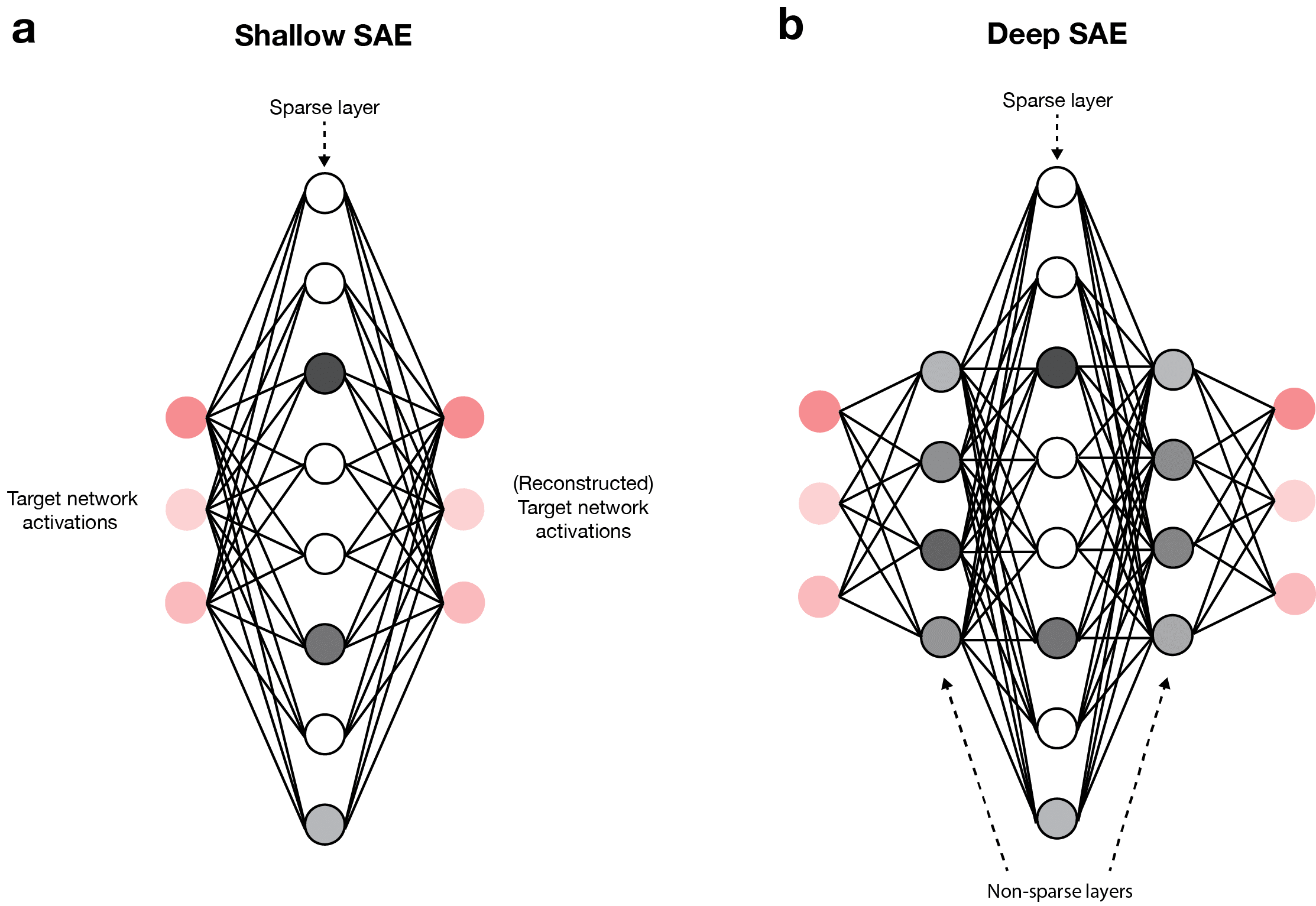


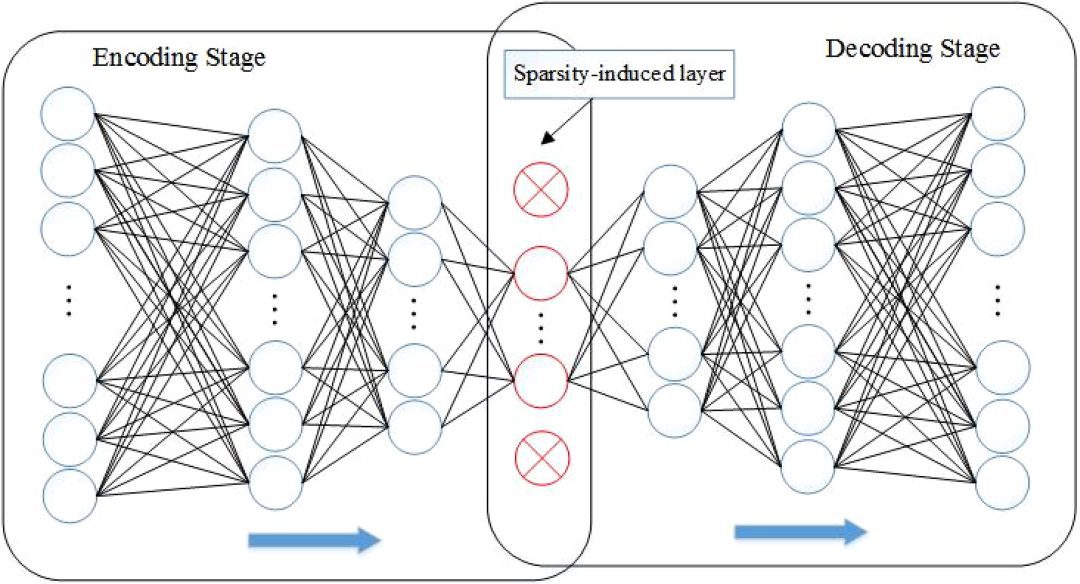













![[논문 리뷰] A Survey on Sparse Autoencoders: Interpreting the Internal ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/a-survey-on-sparse-autoencoders-interpreting-the-internal-mechanisms-of-large-language-models-1.png)

















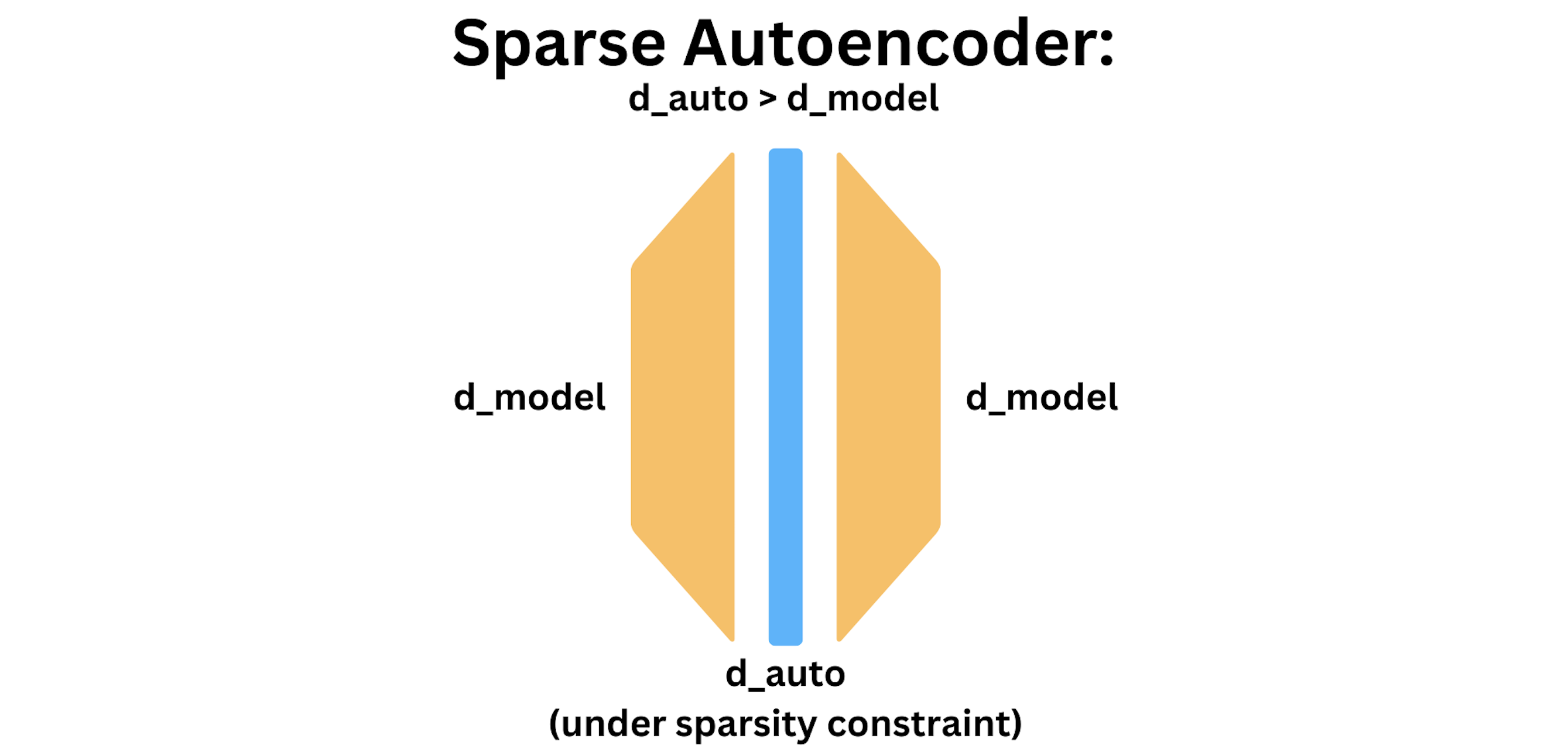
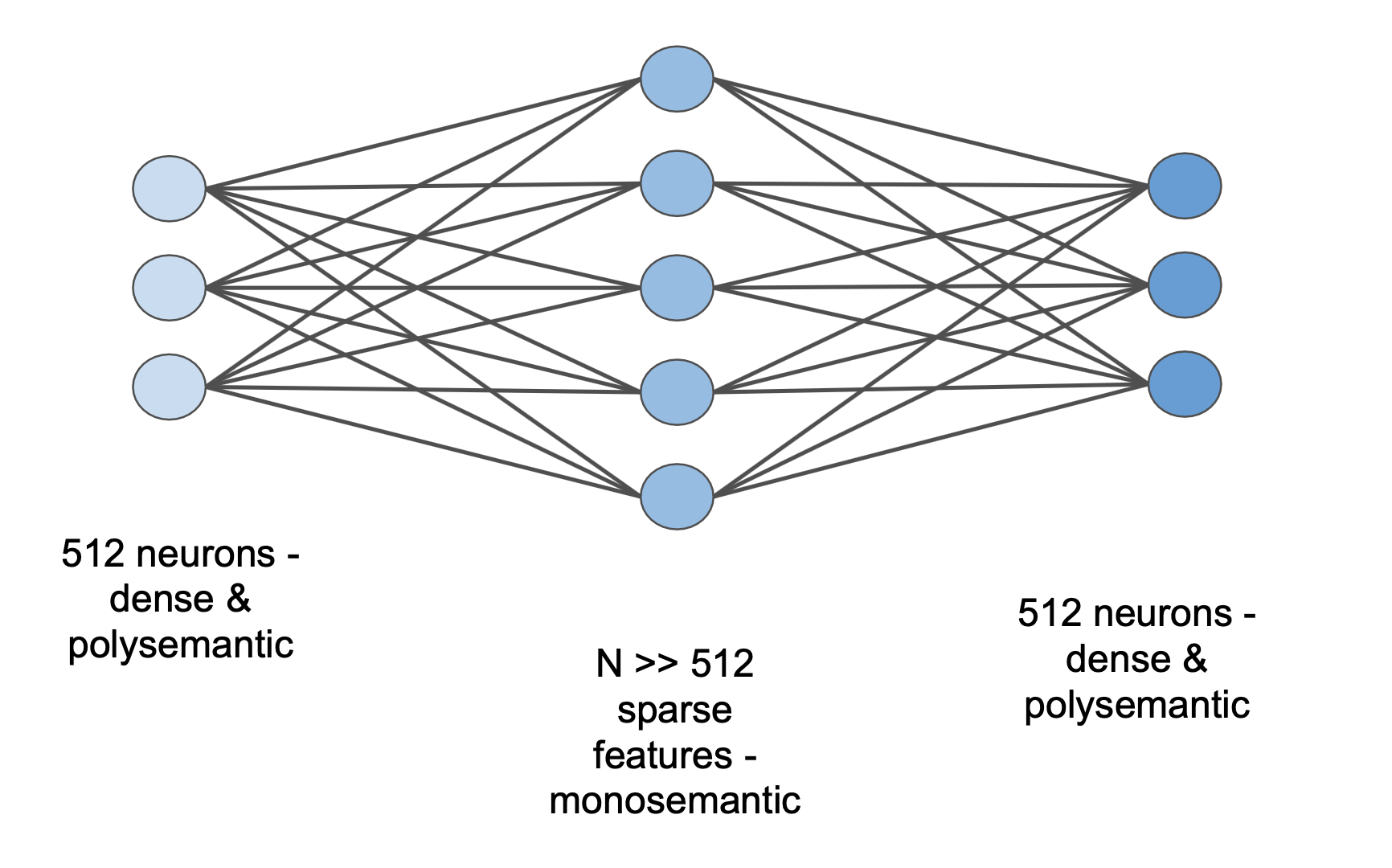
![[논문 리뷰] Transcoders Beat Sparse Autoencoders for Interpretability](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/transcoders-beat-sparse-autoencoders-for-interpretability-1.png)



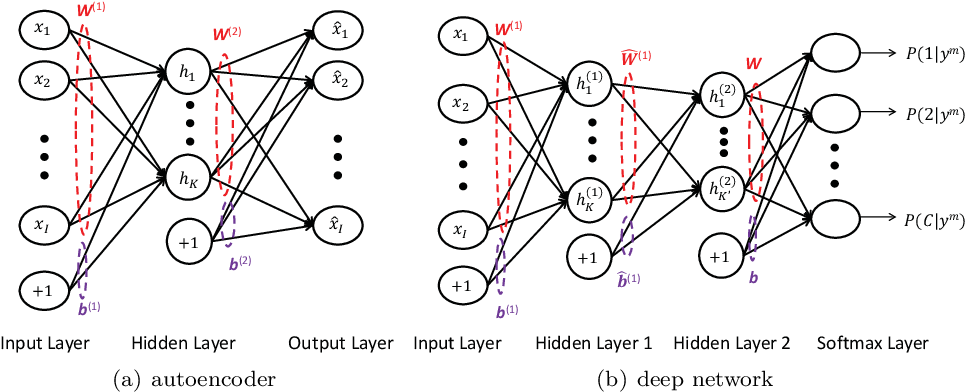
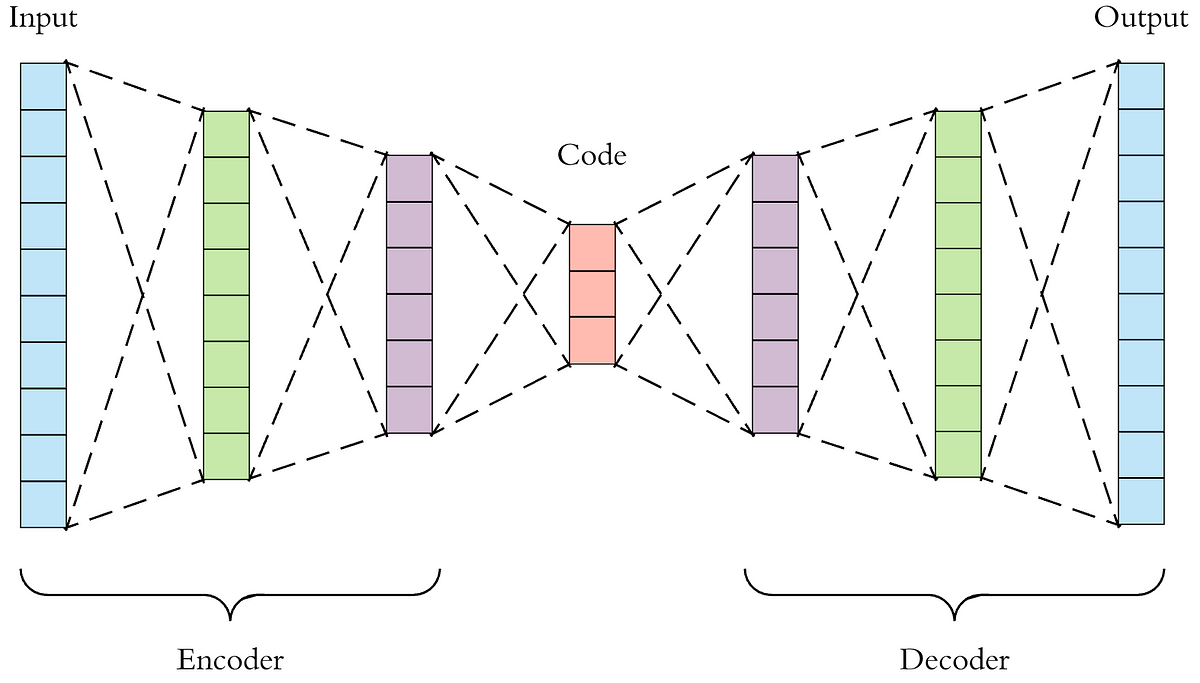
%20were%20fathomable%20and%20contained%20human-understandable%20concepts.%20Yet%2C%20these%20methods%20are%20seldom%20contextualised%20and%20are%20often%20based%20on%20a%20single%20hidden%20state%2C%20which%20makes%20them%20unable%20to%20interpret%20multi-step%20reasoning%2C%20e.g.%20planning.%20In%20this%20respect%2C%20we%20propose%20contrastive%20sparse%20autoencoders%20(CSAE)%2C%20a%20novel%20framework%20for%20studying%20pairs%20of%20game%20trajectories.%20Using%20CSAE%2C%20we%20are%20able%20to%20extract%20and%20interpret%20concepts%20that%20are%20meaningful%20to%20the%20chess-agent%20plans.%20We%20primarily%20focused%20on%20a%20qualitative%20analysis%20of%20the%20CSAE%20features%20before%20proposing%20an%20automated%20feature%20taxonomy.%20Furthermore%2C%20to%20evaluate%20the%20quality%20of%20our%20trained%20CSAE%2C%20we%20devise%20sanity%20checks%20to%20wave%20spurious%20correlations%20in%20our%20results.)
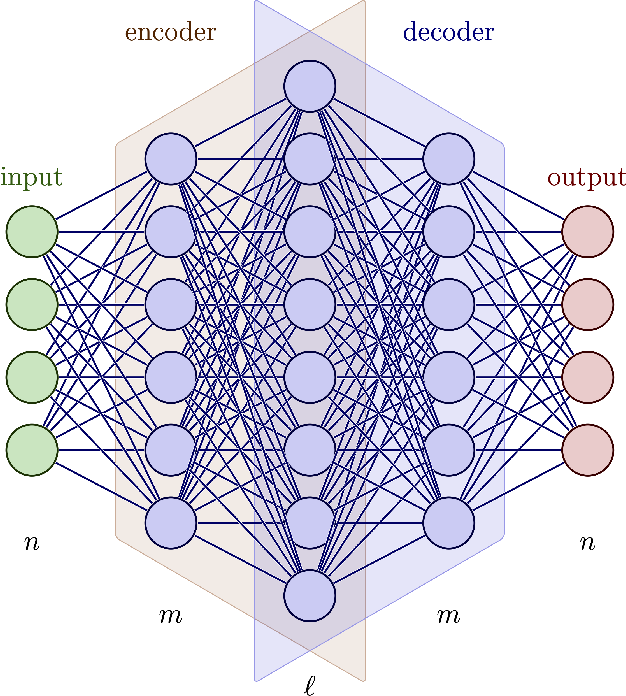





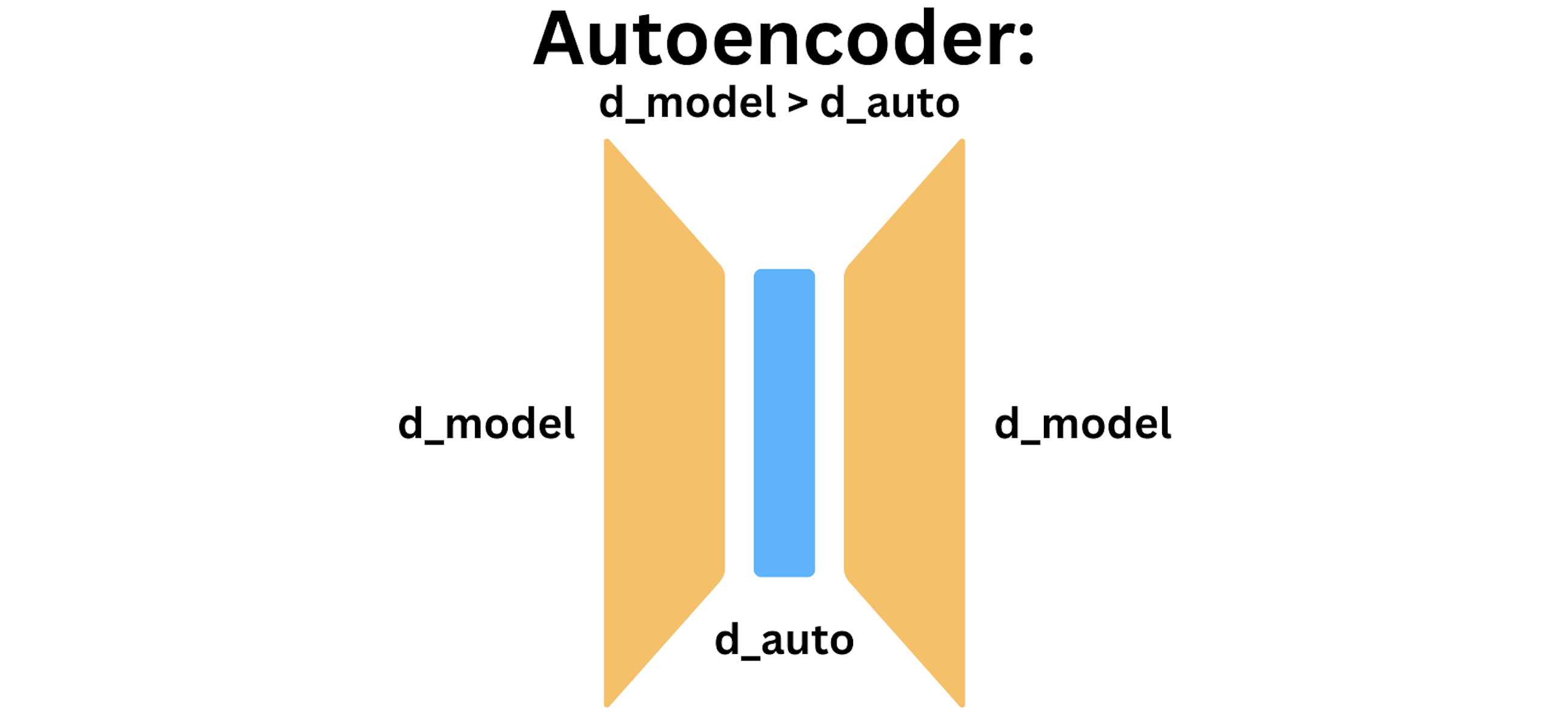
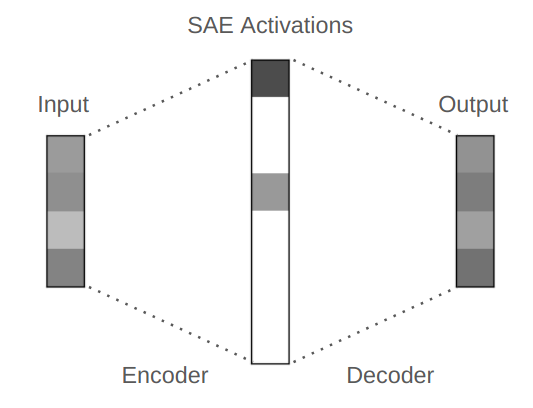
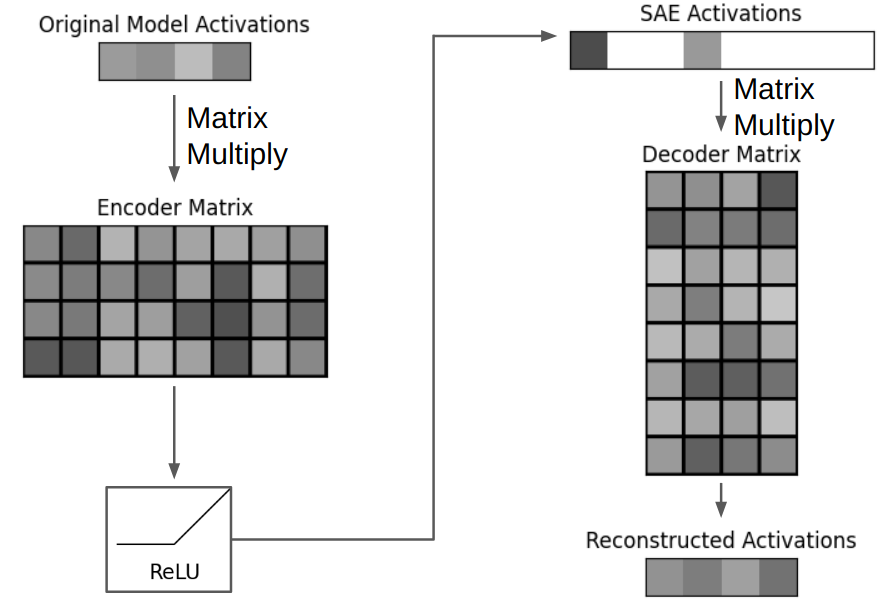
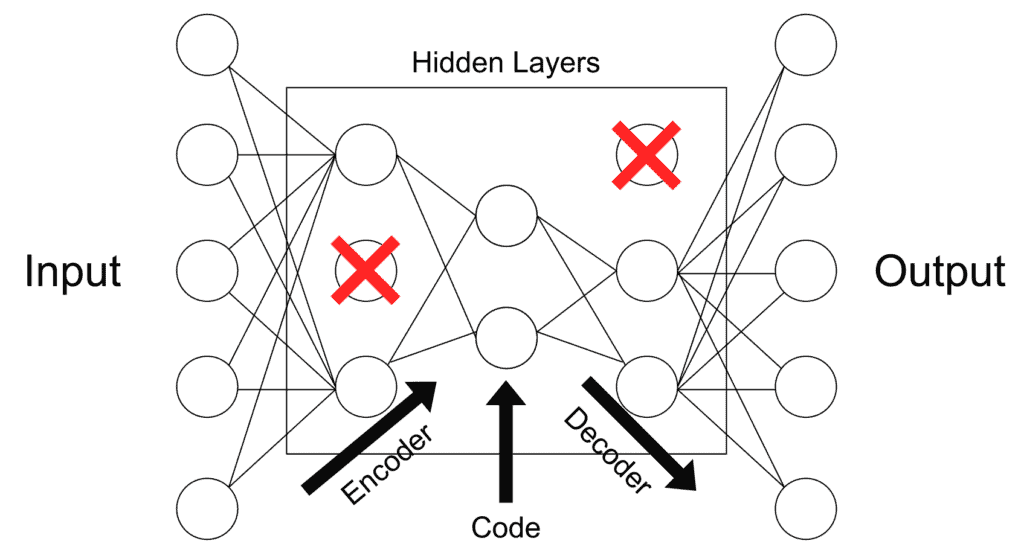
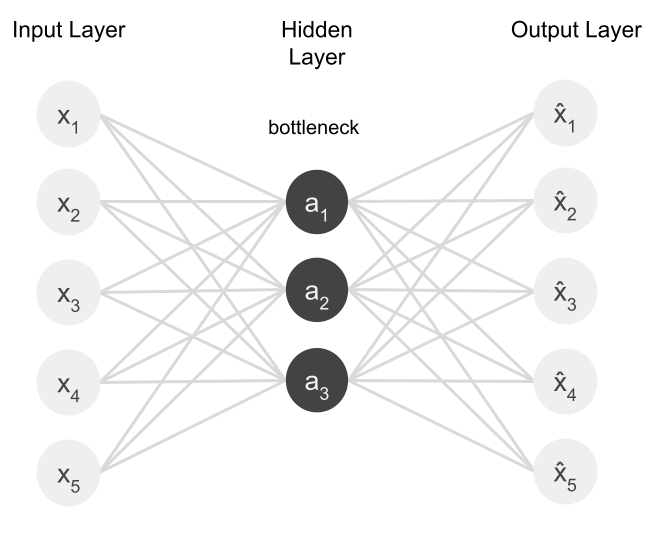
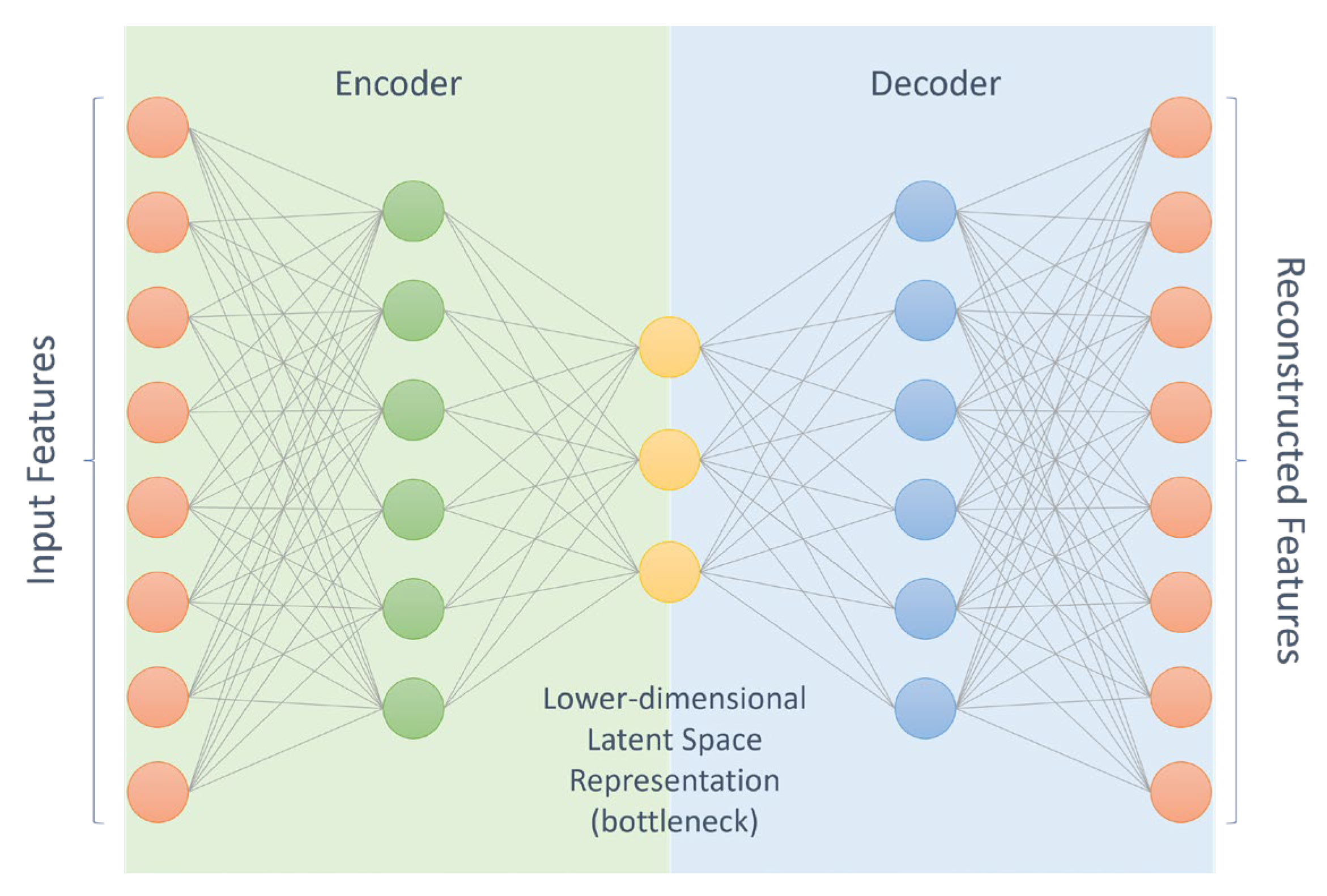
![Autoencoders in Deep Learning: Tutorial & Use Cases [2024]](https://cdn.prod.website-files.com/5d7b77b063a9066d83e1209c/60e424e6f33c5b477e856285_input-hidden-output-layers.png)




![[논문 리뷰] PrivacyScalpel: Enhancing LLM Privacy via Interpretable Feature ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/privacyscalpel-enhancing-llm-privacy-via-interpretable-feature-intervention-with-sparse-autoencoders-3.png)

![[논문 리뷰] SAeUron: Interpretable Concept Unlearning in Diffusion Models ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/saeuron-interpretable-concept-unlearning-in-diffusion-models-with-sparse-autoencoders-0.png)







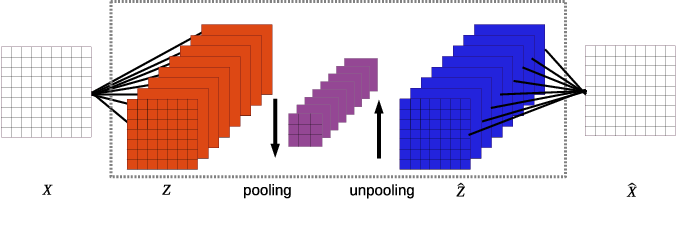
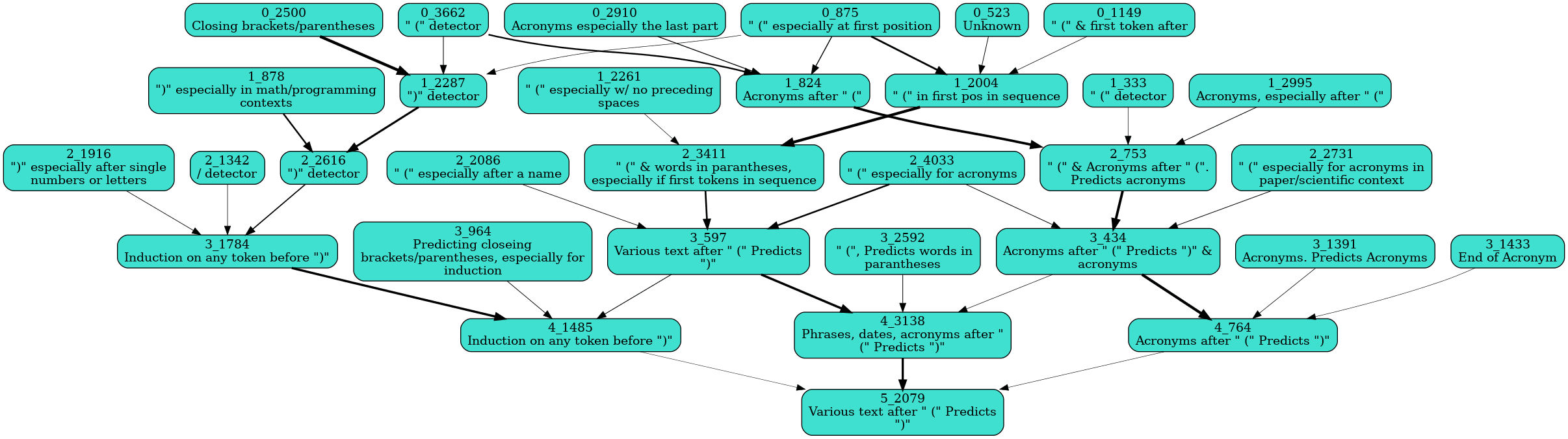
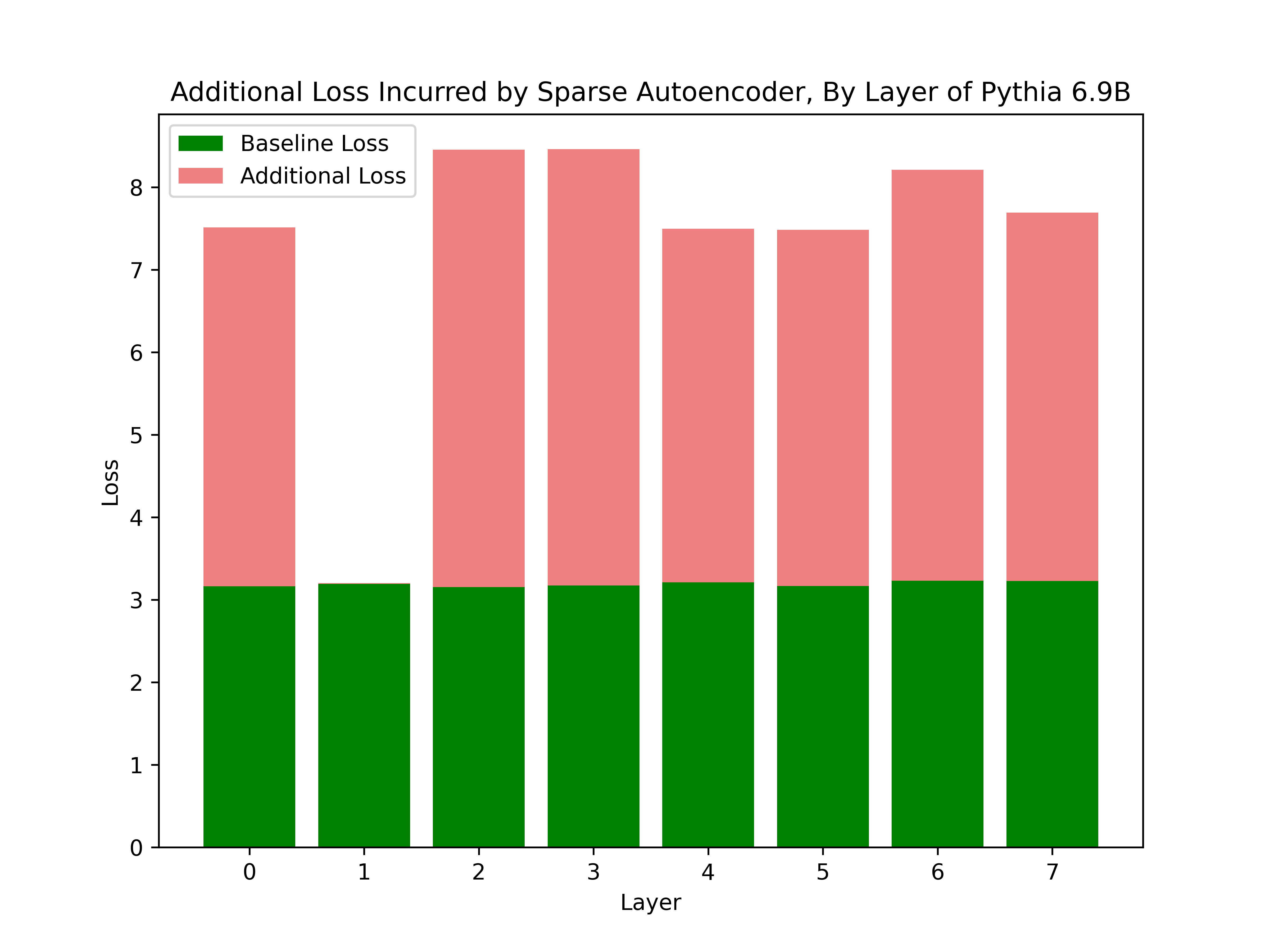
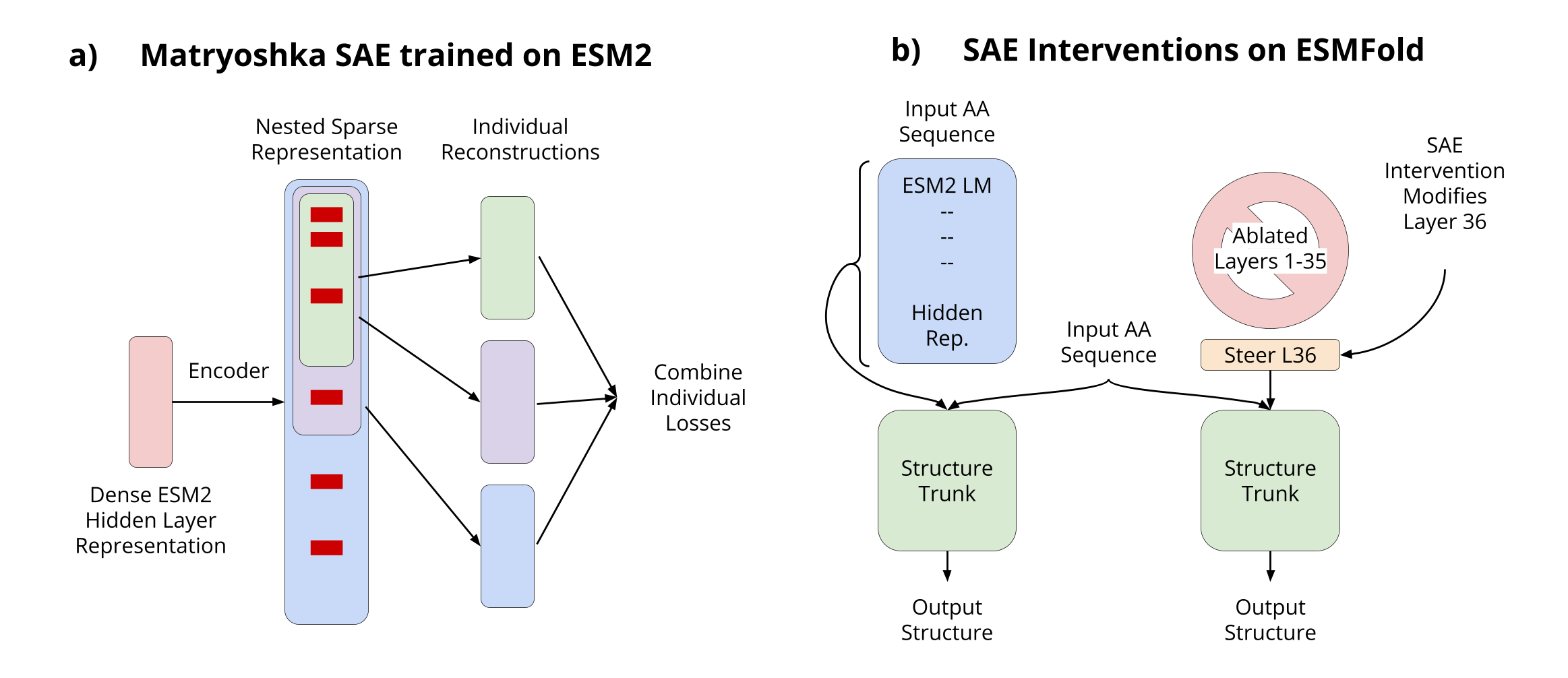
![[论文审查] Efficient Training of Sparse Autoencoders for Large Language ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/efficient-training-of-sparse-autoencoders-for-large-language-models-via-layer-groups-1.png)


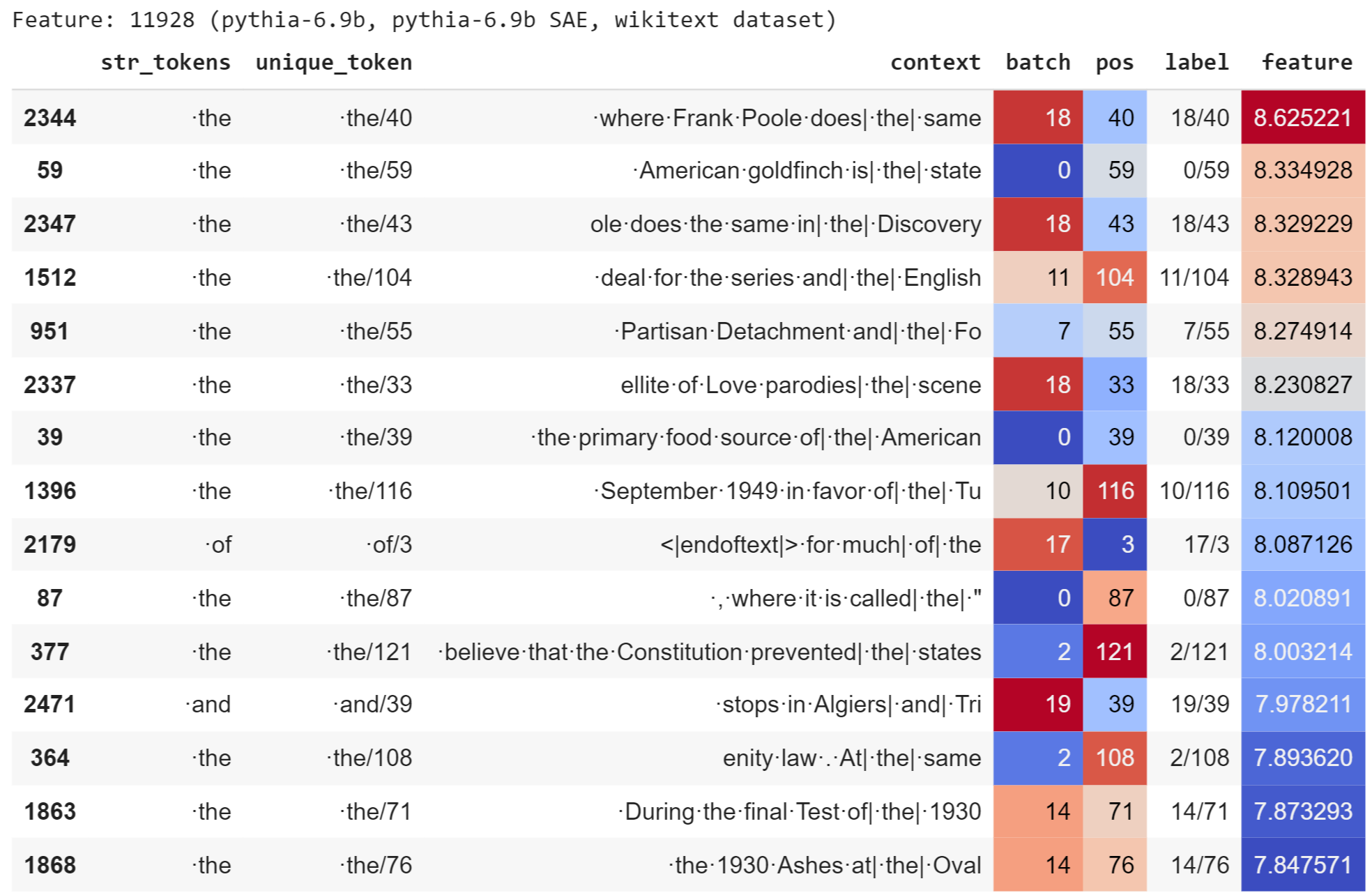
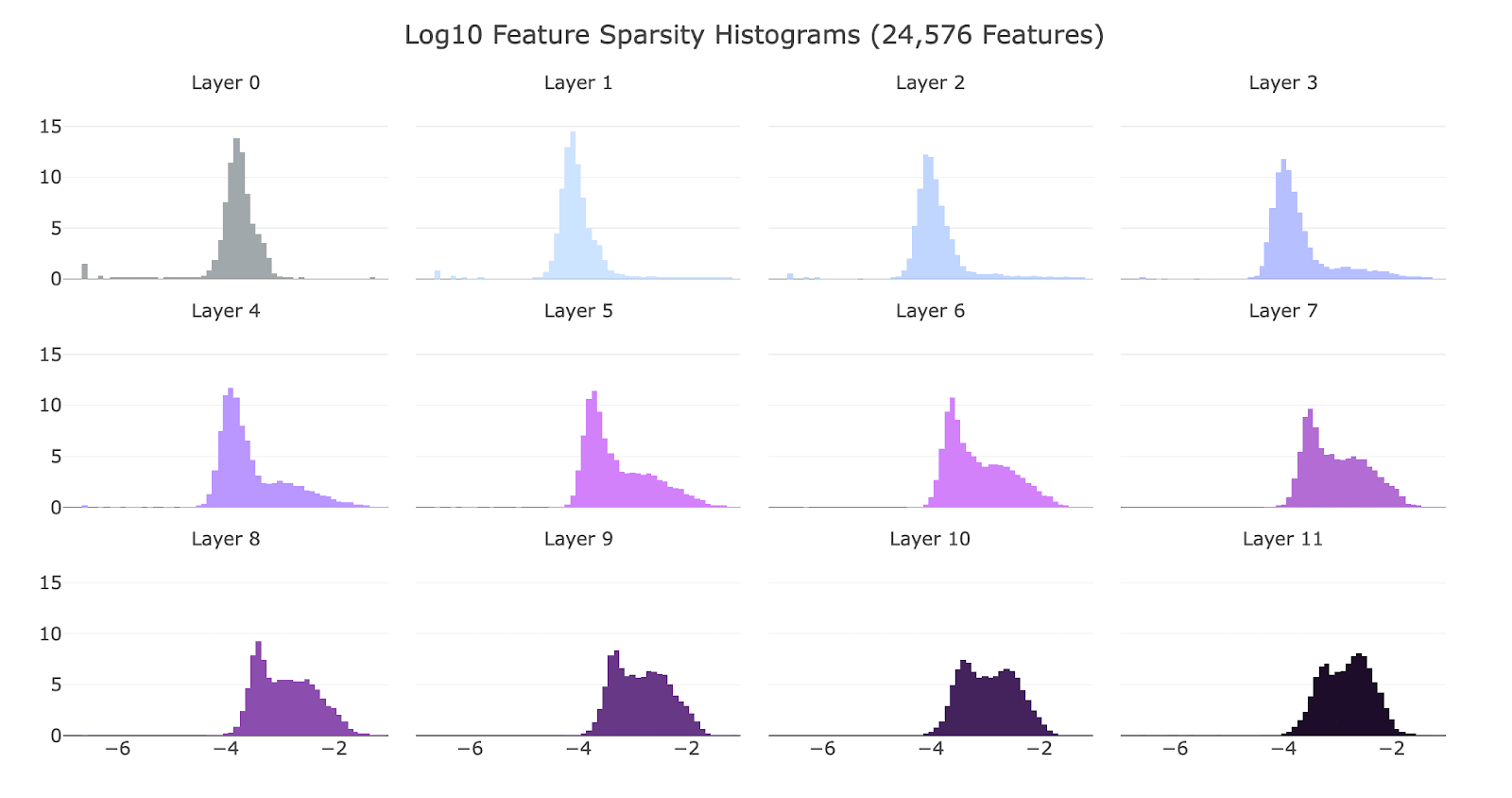
![[논문 리뷰] Sparse Autoencoders Can Interpret Randomly Initialized Transformers](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/sparse-autoencoders-can-interpret-randomly-initialized-transformers-3.png)


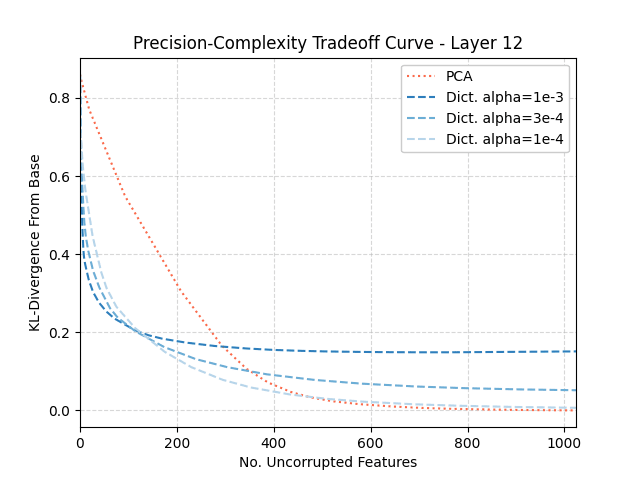
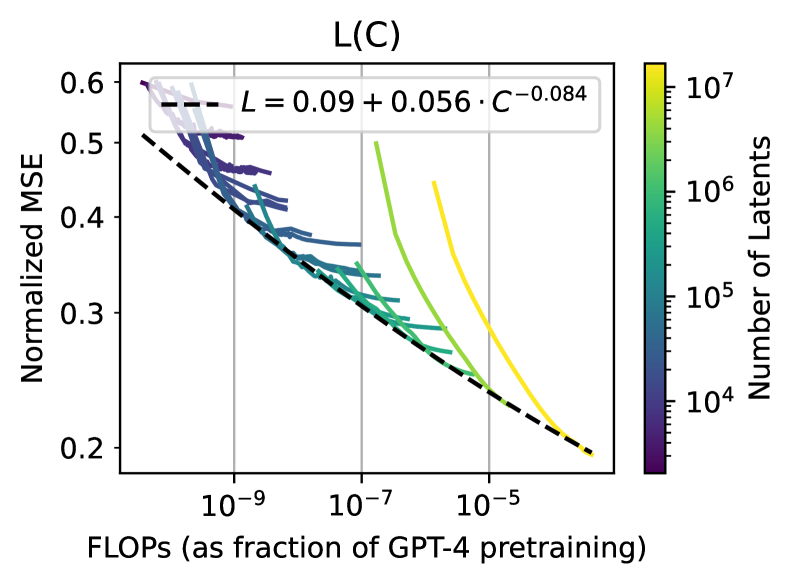



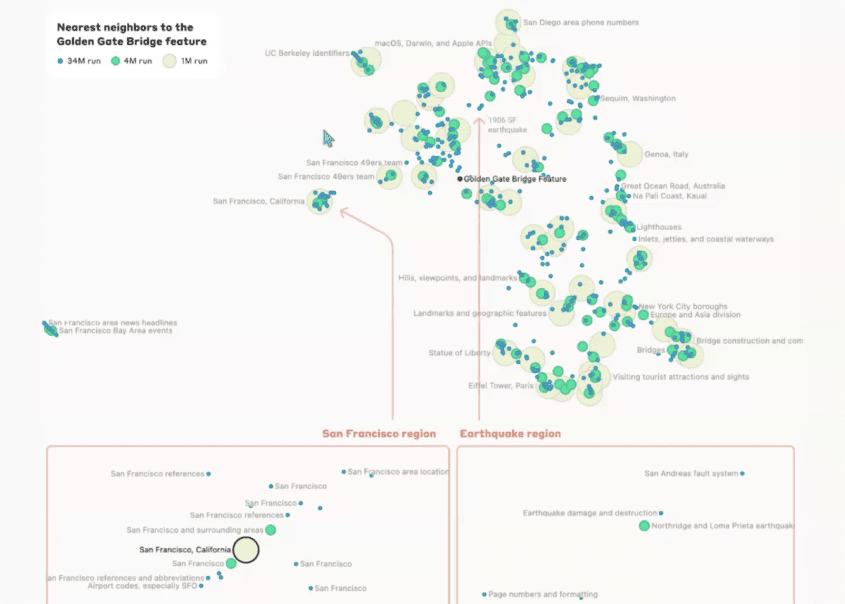


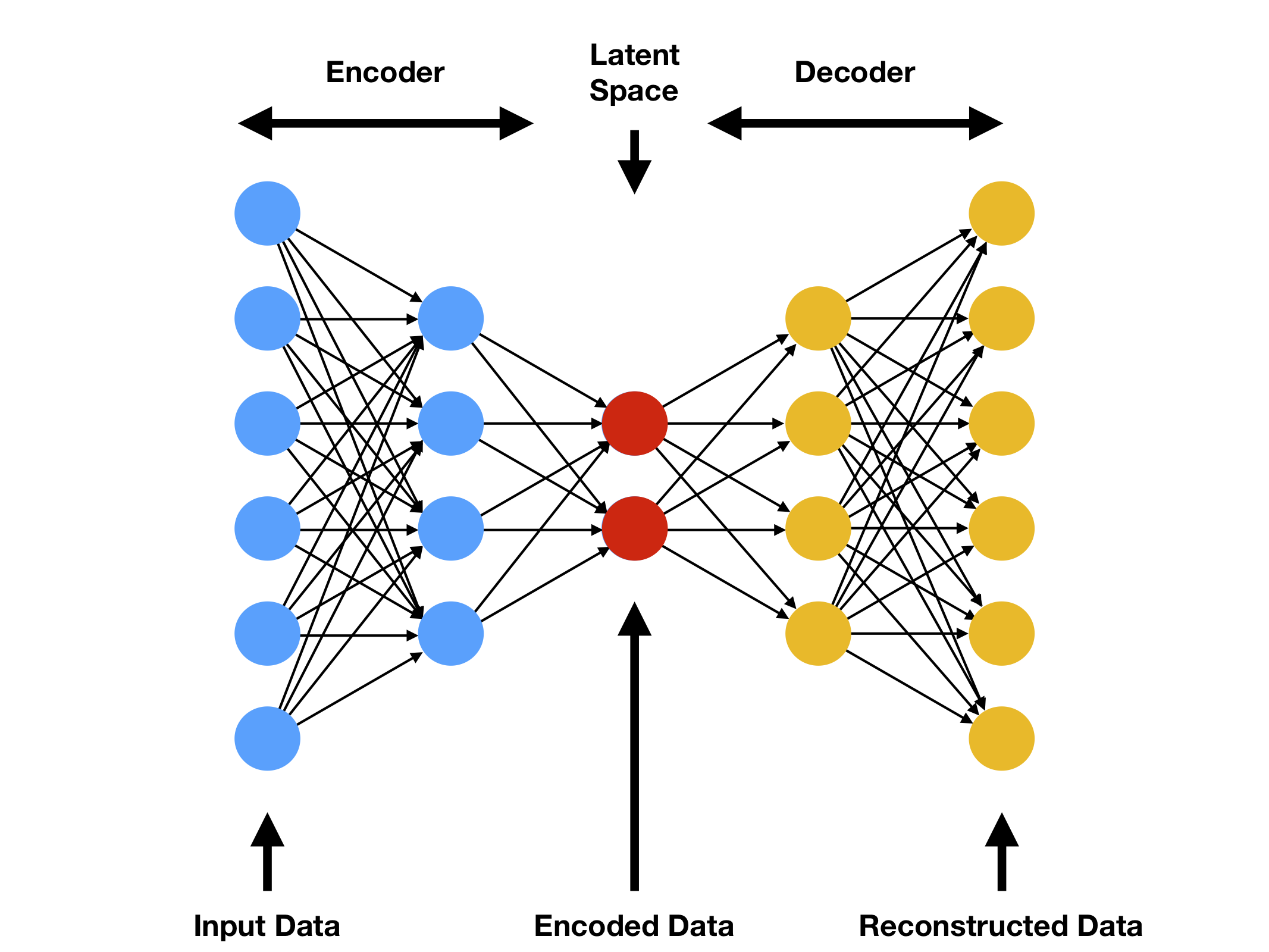
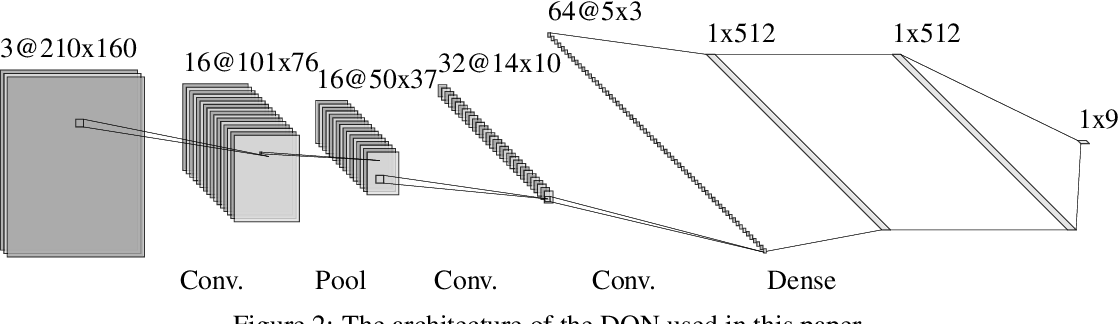
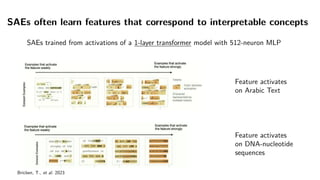
Drive innovation with our technology sparse autoencoders for more interpretable rlhf - laker newhouse gallery of numerous digital images. technologically showcasing photography, images, and pictures. perfect for tech marketing and documentation. The sparse autoencoders for more interpretable rlhf - laker newhouse collection maintains consistent quality standards across all images. Suitable for various applications including web design, social media, personal projects, and digital content creation All sparse autoencoders for more interpretable rlhf - laker newhouse images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Our sparse autoencoders for more interpretable rlhf - laker newhouse gallery offers diverse visual resources to bring your ideas to life. Time-saving browsing features help users locate ideal sparse autoencoders for more interpretable rlhf - laker newhouse images quickly. Professional licensing options accommodate both commercial and educational usage requirements. Advanced search capabilities make finding the perfect sparse autoencoders for more interpretable rlhf - laker newhouse image effortless and efficient. Whether for commercial projects or personal use, our sparse autoencoders for more interpretable rlhf - laker newhouse collection delivers consistent excellence. Each image in our sparse autoencoders for more interpretable rlhf - laker newhouse gallery undergoes rigorous quality assessment before inclusion.