
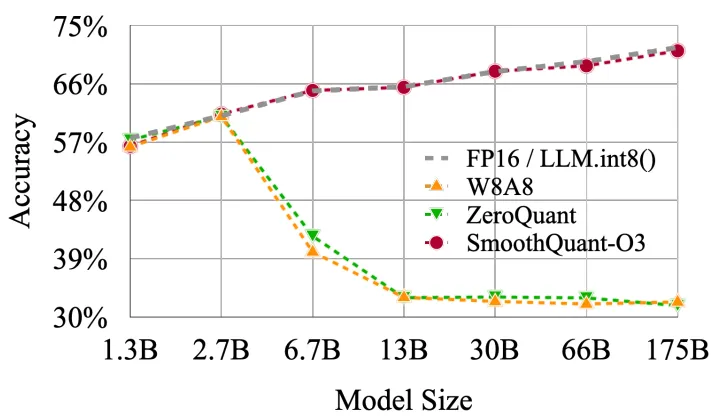
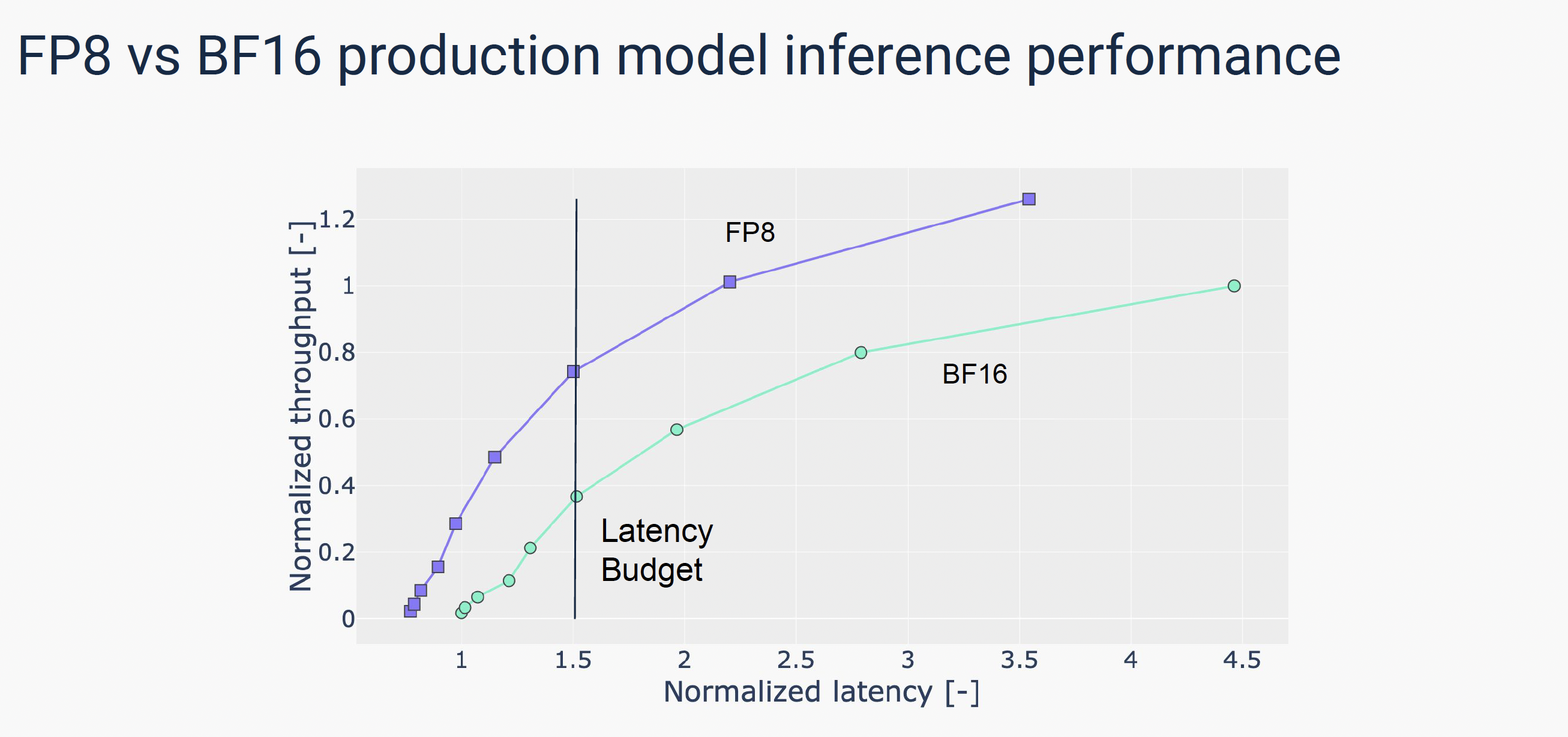






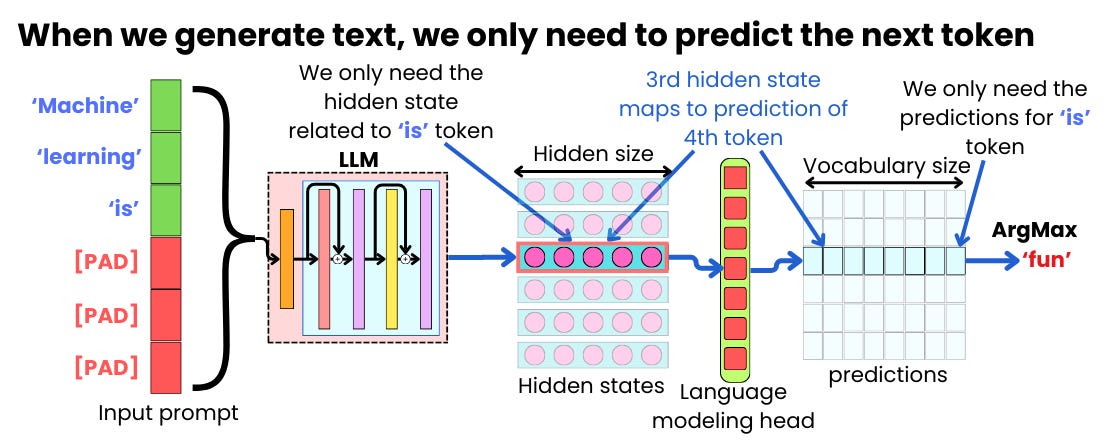
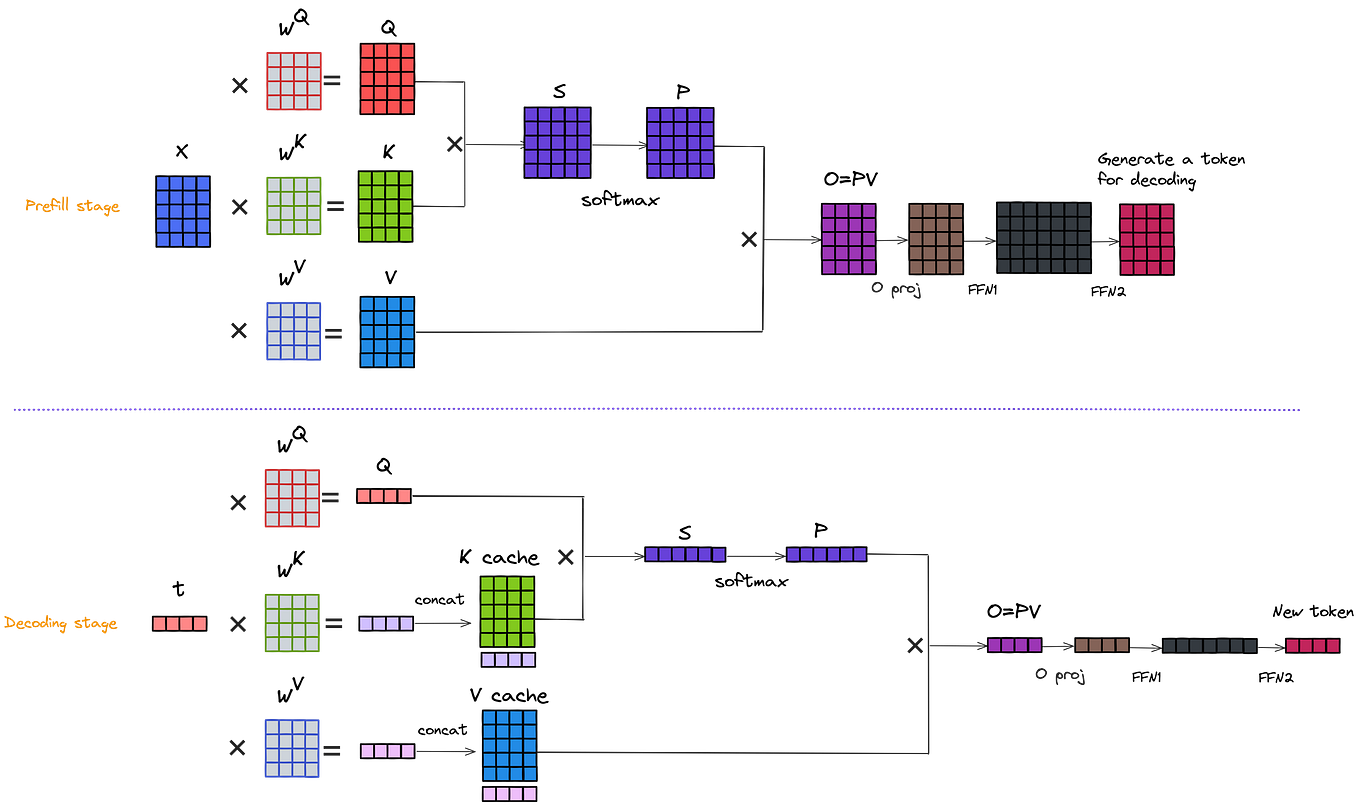





















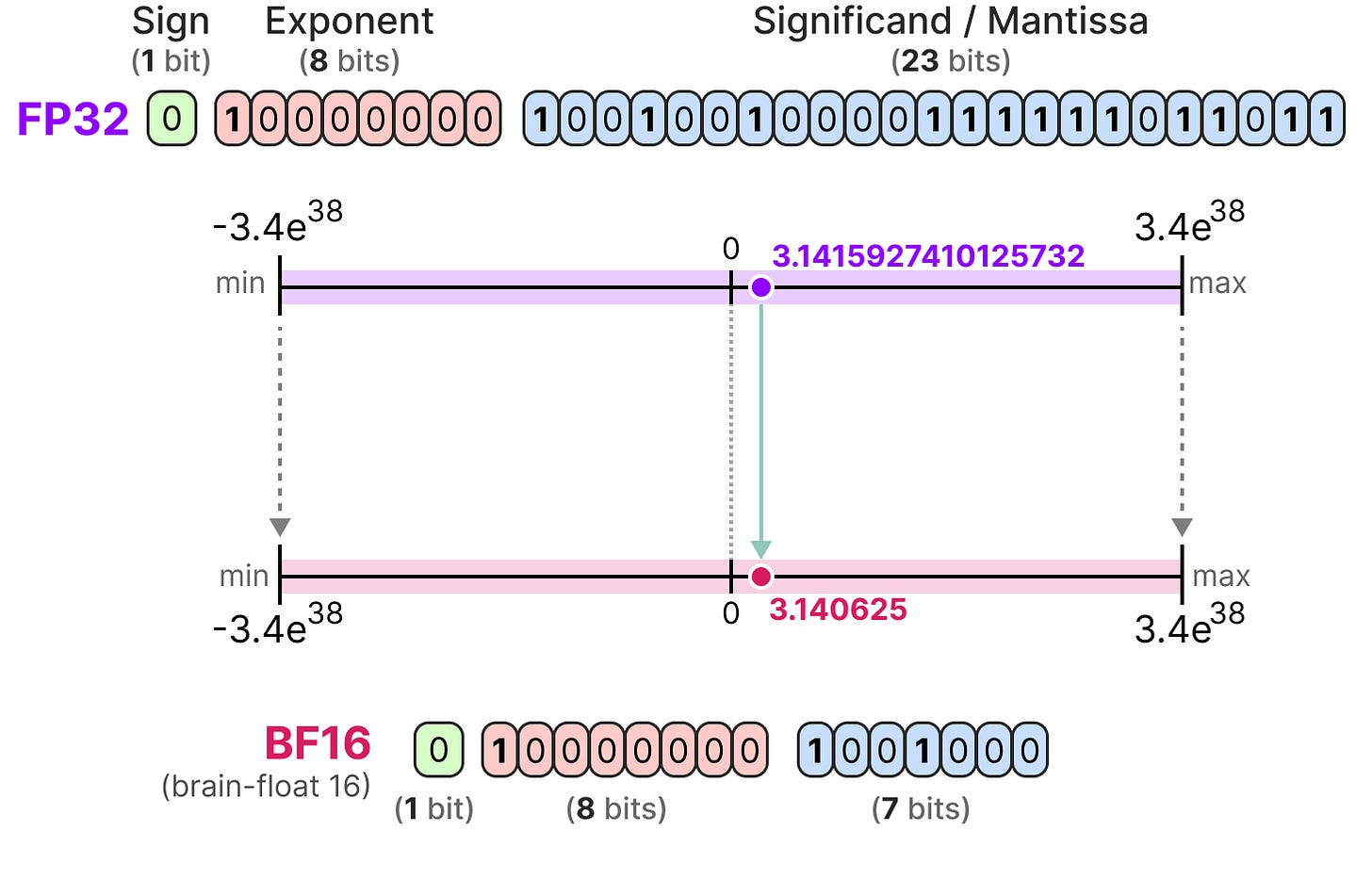
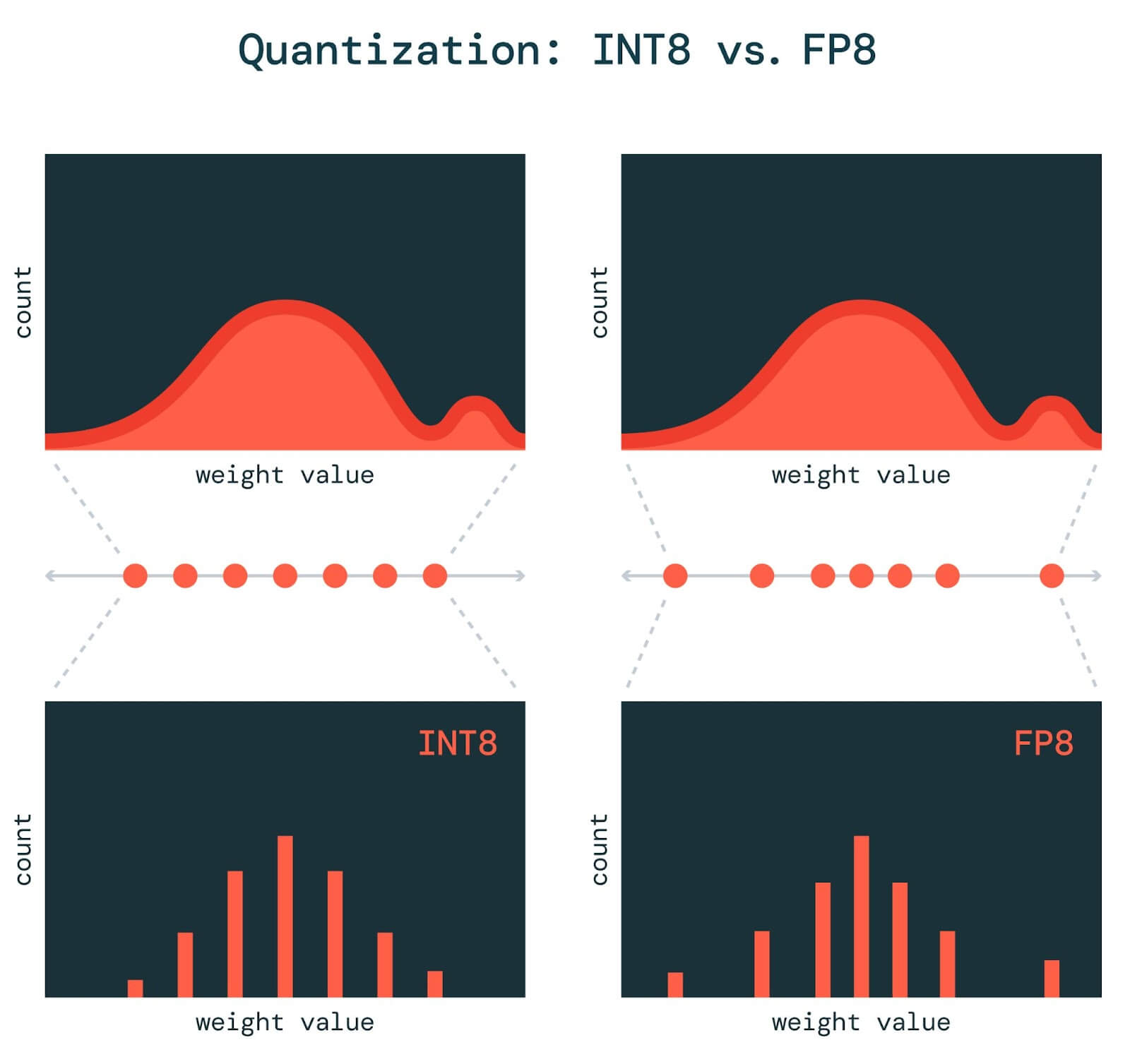
![[LLM]FP8计算在模型训练中的应用 - 知乎](https://pic2.zhimg.com/v2-638c85e2b66b3138aeaed5ea14aadf17_r.jpg)







![[2309.14592] Efficient Post-training Quantization with FP8 Formats](https://ar5iv.labs.arxiv.org/html/2309.14592/assets/pics/quant_flow_new.png)






![[LLM]FP8计算在模型训练中的应用 - 知乎](https://pic2.zhimg.com/v2-2e62ee61175b7dc8fb771102a75be831_r.jpg)




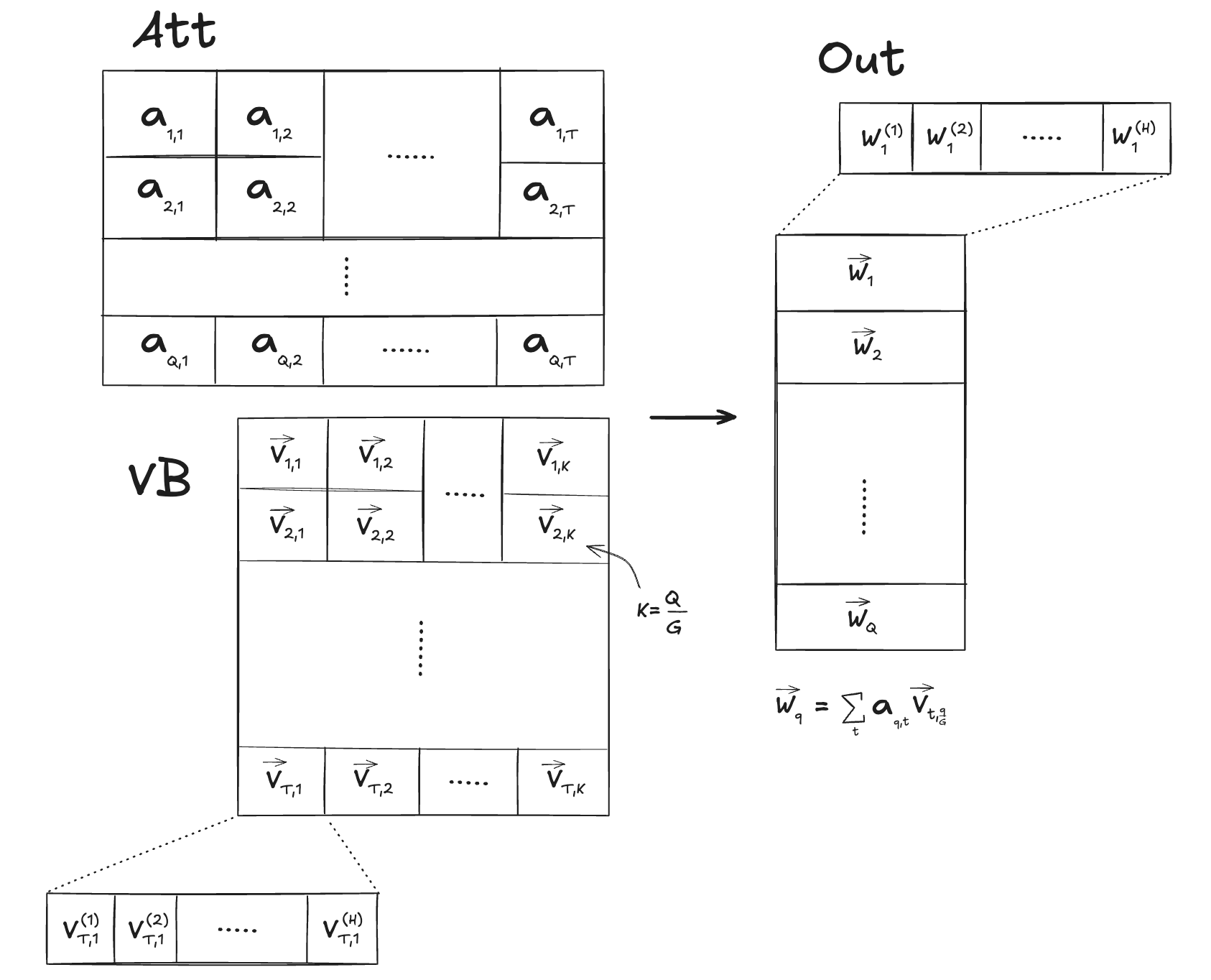
![[논문 리뷰] Faster MoE LLM Inference for Extremely Large Models](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/faster-moe-llm-inference-for-extremely-large-models-1.png)


![[2303.17951] FP8 versus INT8 for efficient deep learning inference](https://ar5iv.labs.arxiv.org/html/2303.17951/assets/x11.png)
![[LLM]FP8计算在模型训练中的应用 - 知乎](https://picx.zhimg.com/v2-64e4e74e6d69a52afe4c22e87a3df841_r.jpg)
![[2309.14592] Efficient Post-training Quantization with FP8 Formats](https://ar5iv.labs.arxiv.org/html/2309.14592/assets/pics/fp8_format_dist.png)

![[LLM]FP8计算在模型训练中的应用 - 知乎](https://pica.zhimg.com/v2-281b3d58f5fa0a292a48e455930f0dfc_r.jpg)







![[LLM]FP8计算在模型训练中的应用 - 知乎](https://pic1.zhimg.com/v2-4fc0e7f994585e8d1ba3c7076af1161c_1440w.jpg)
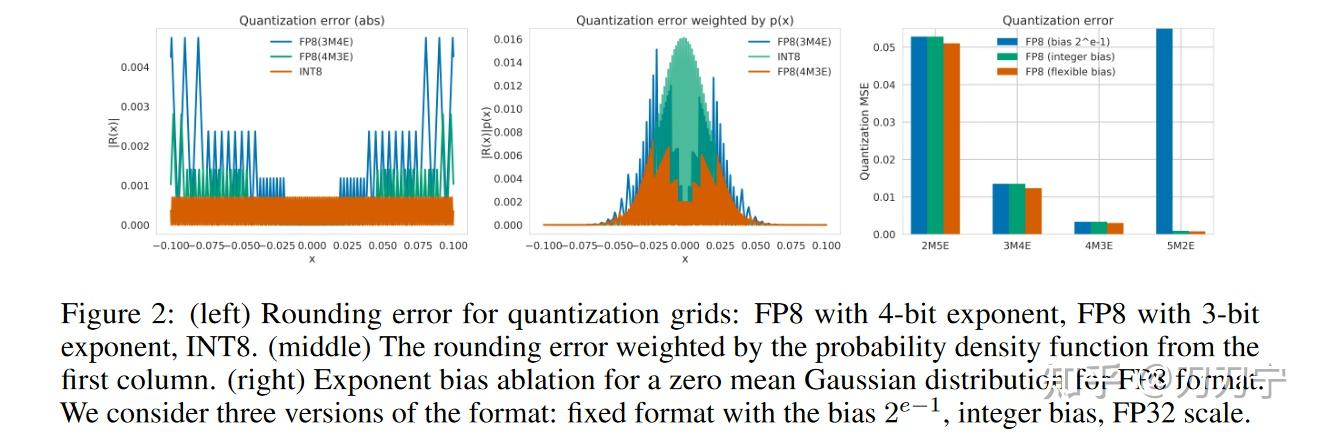
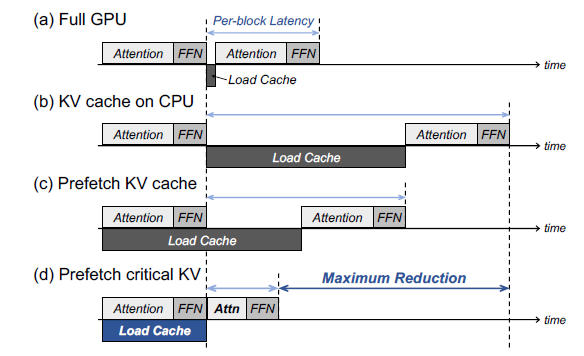
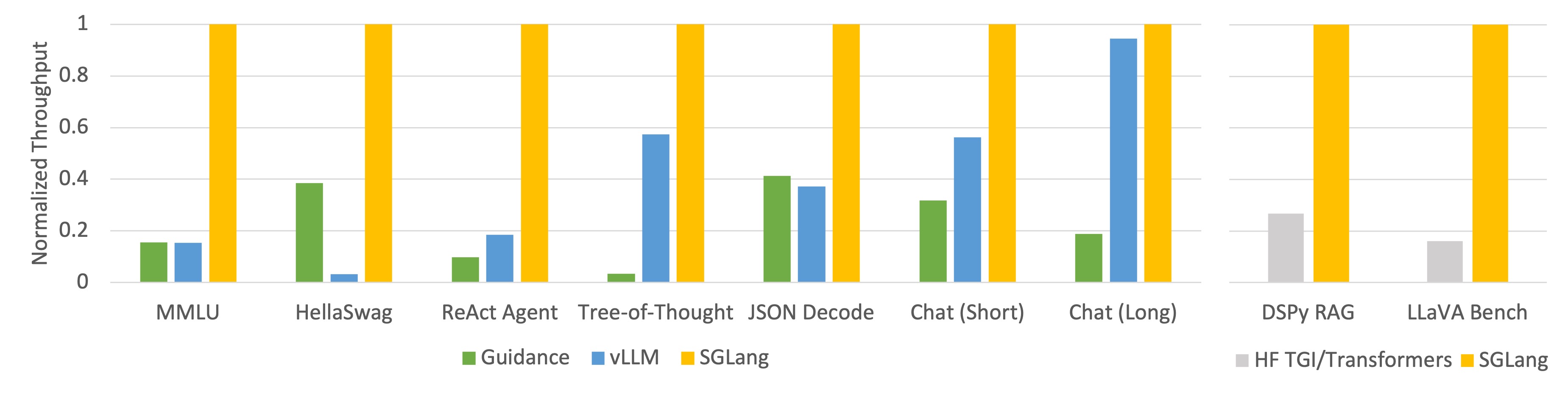


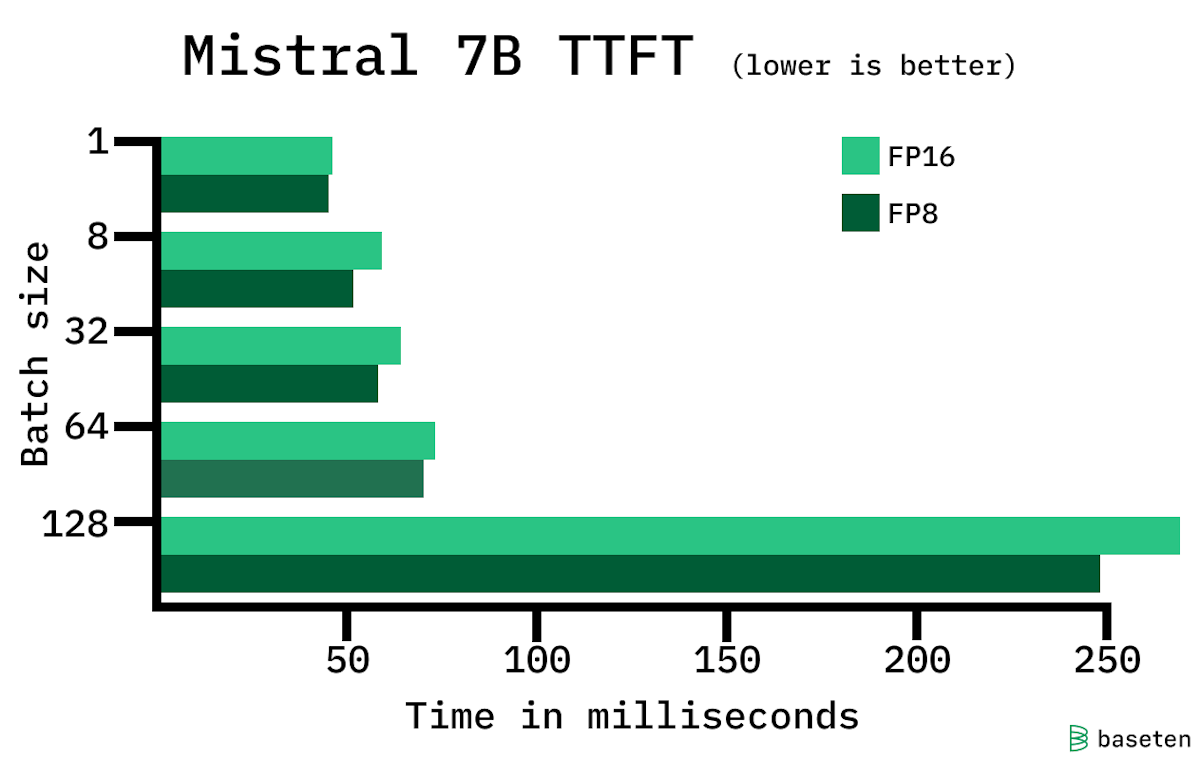
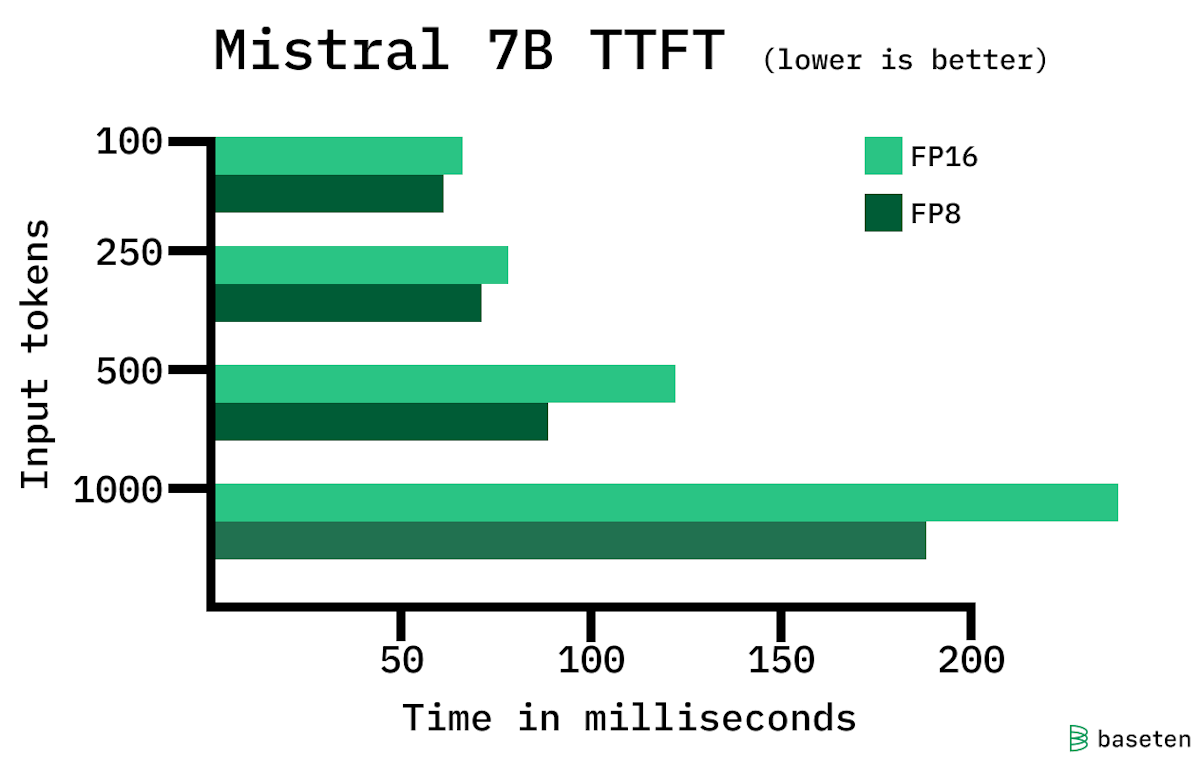
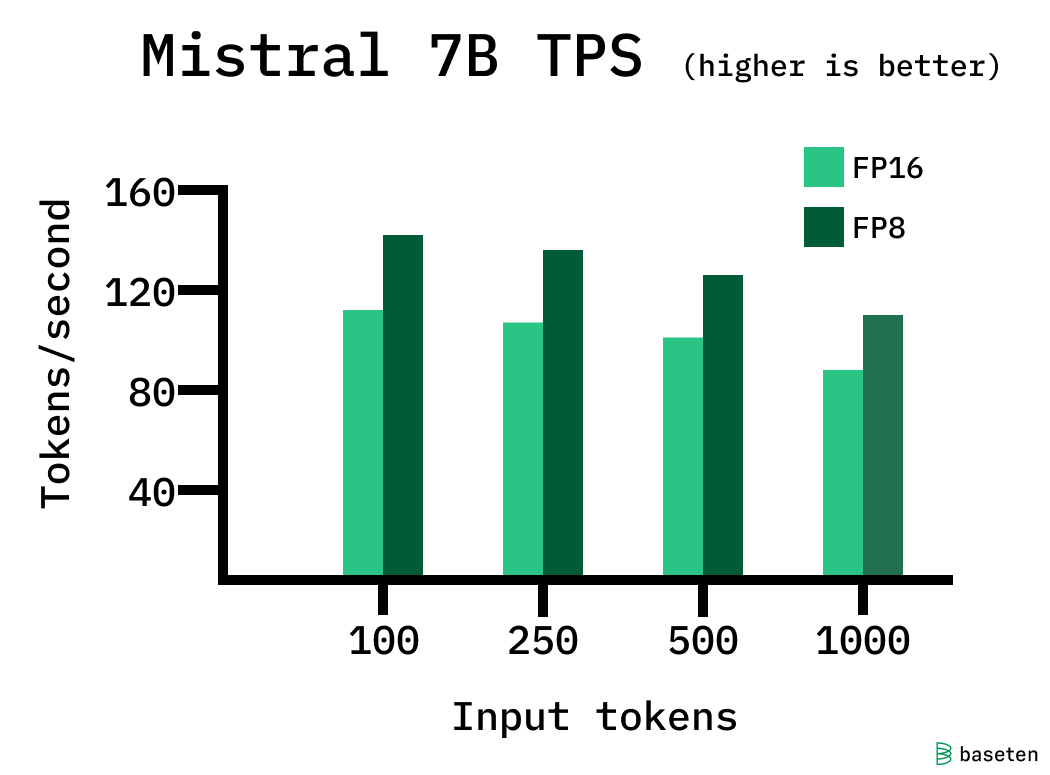
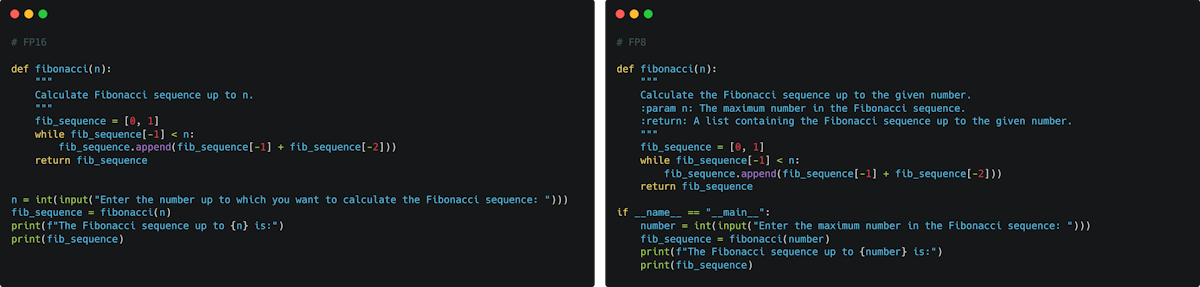
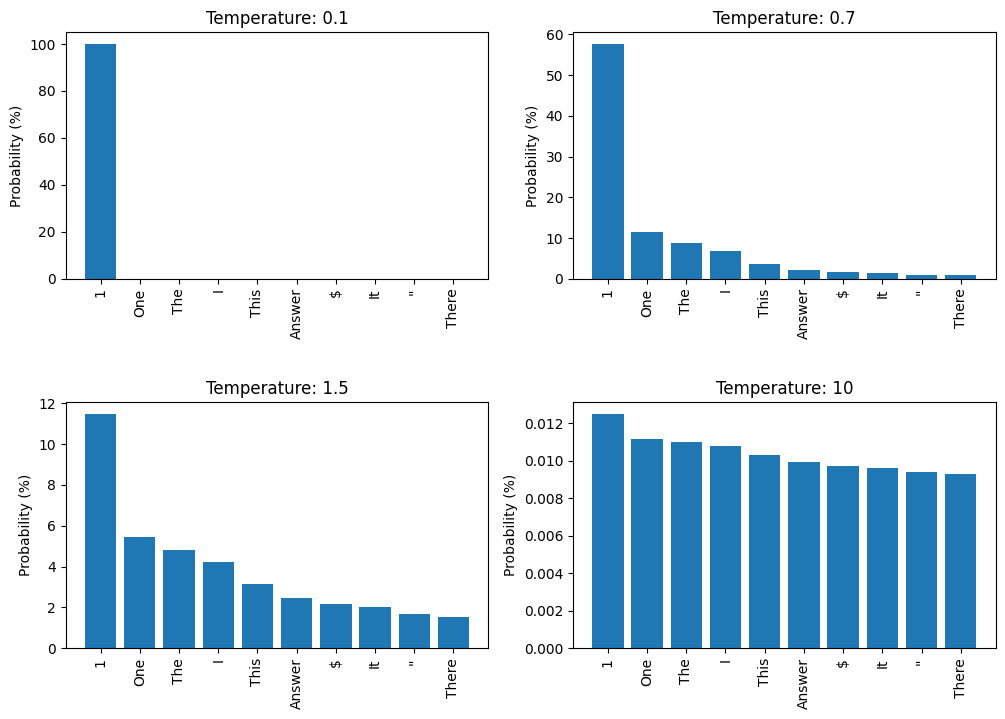
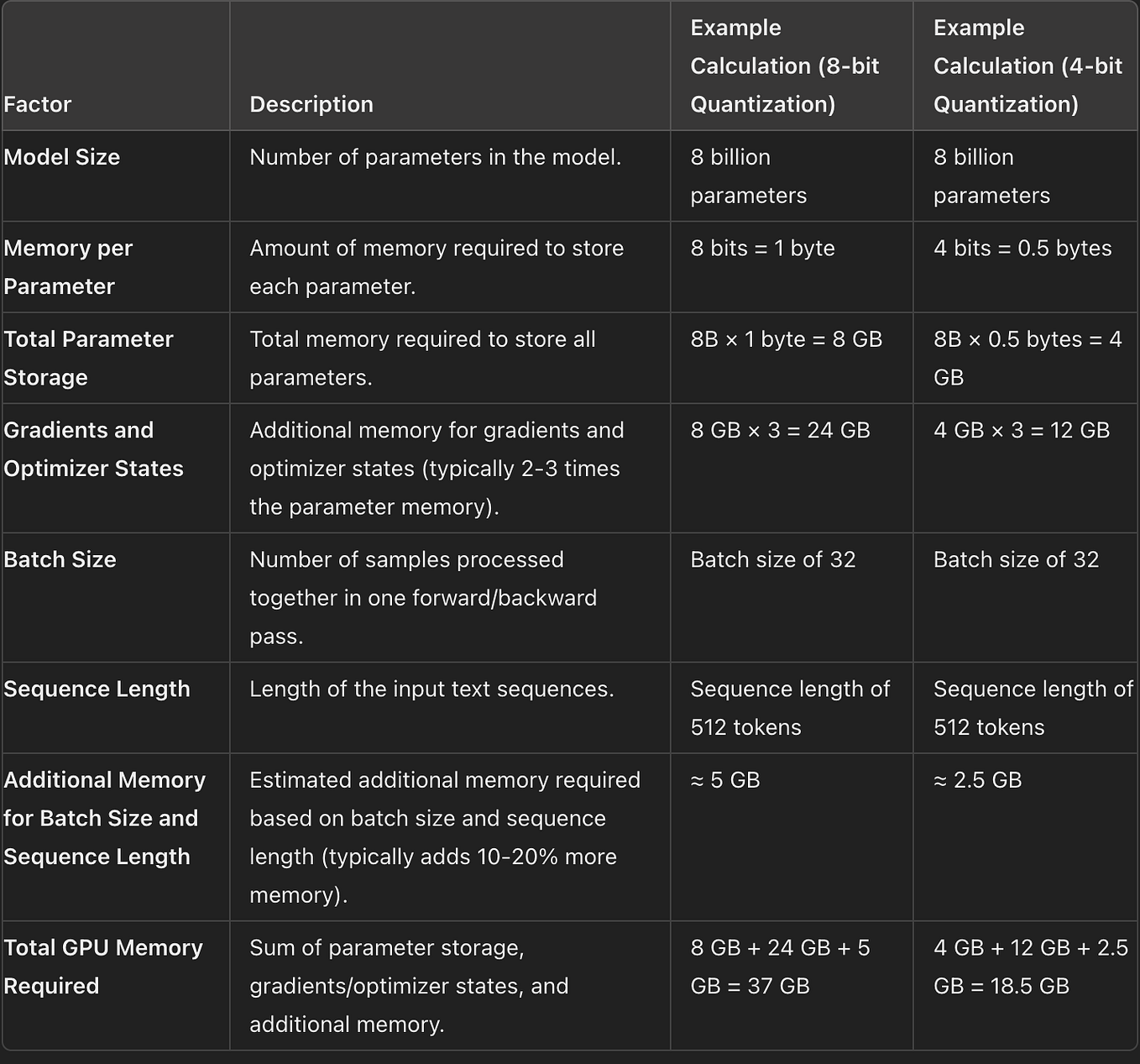
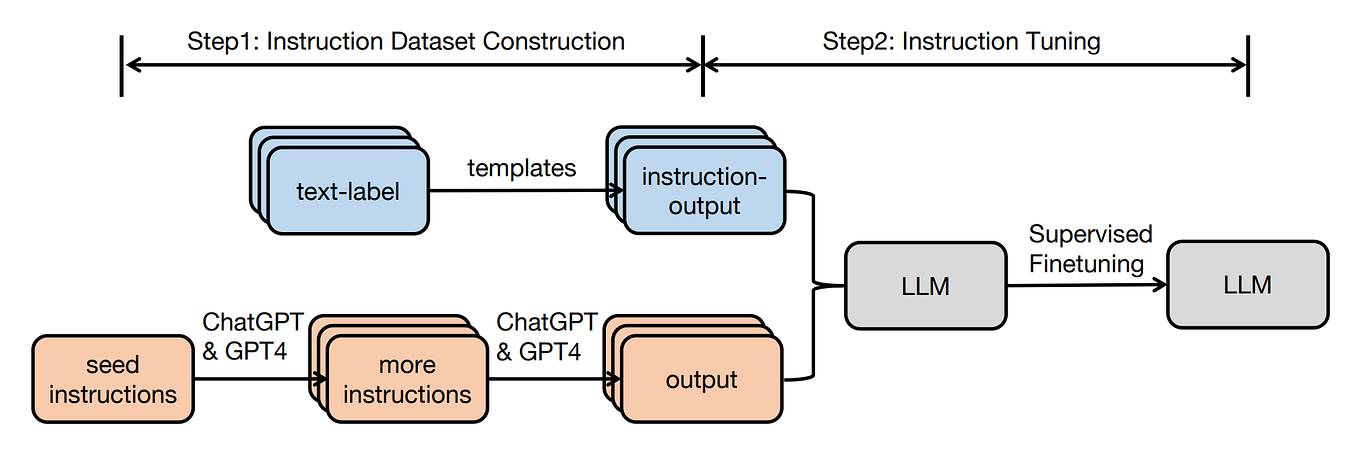
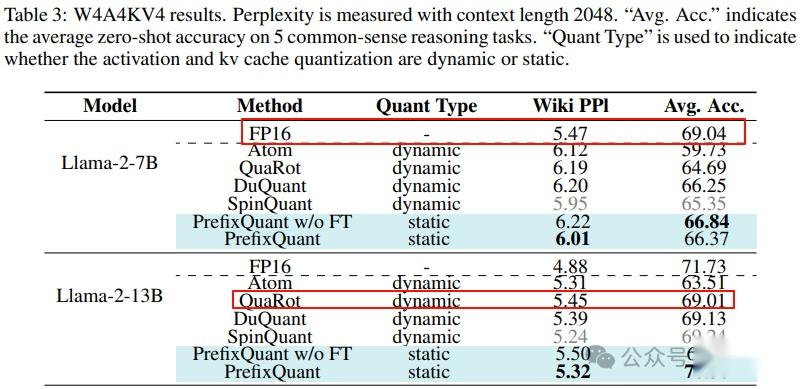
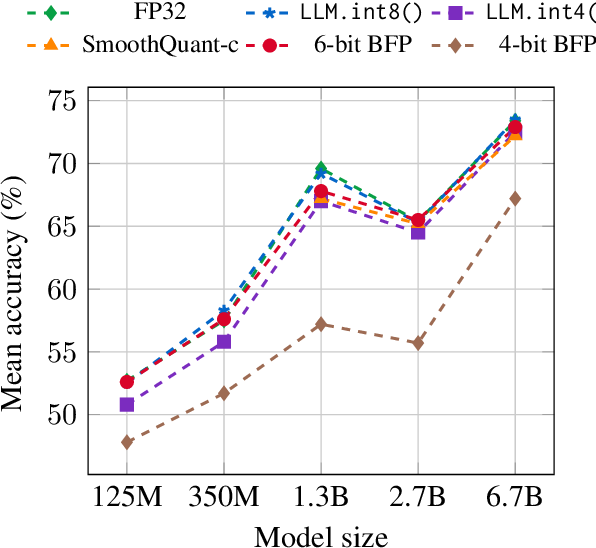
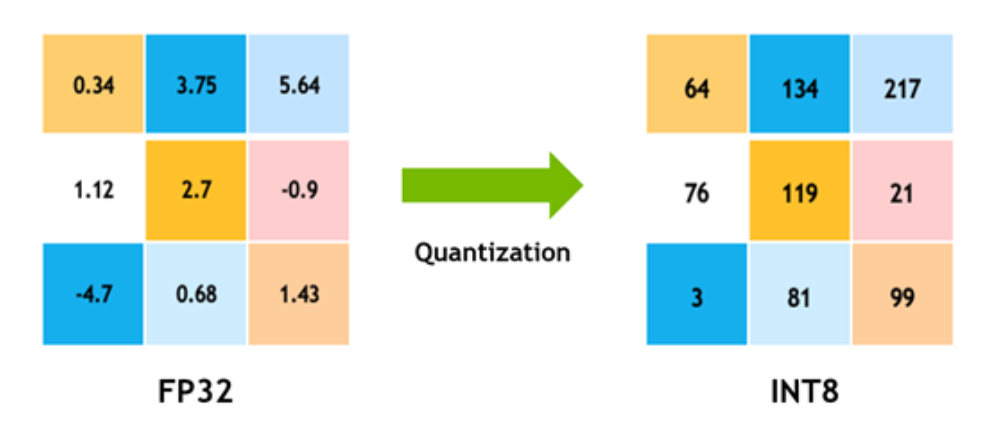
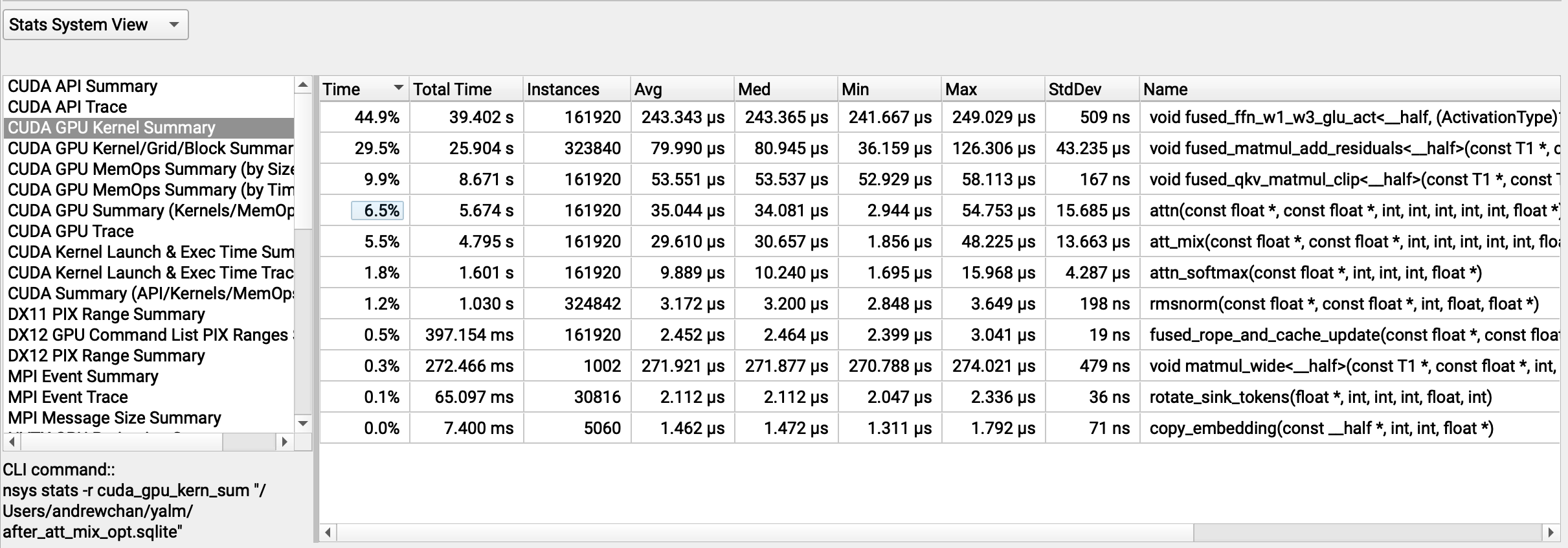
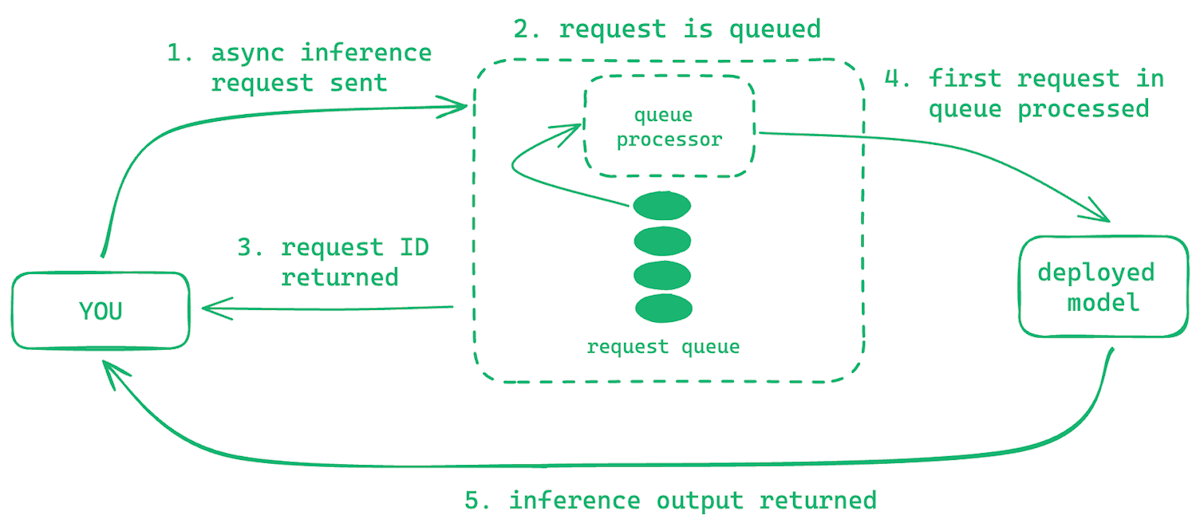
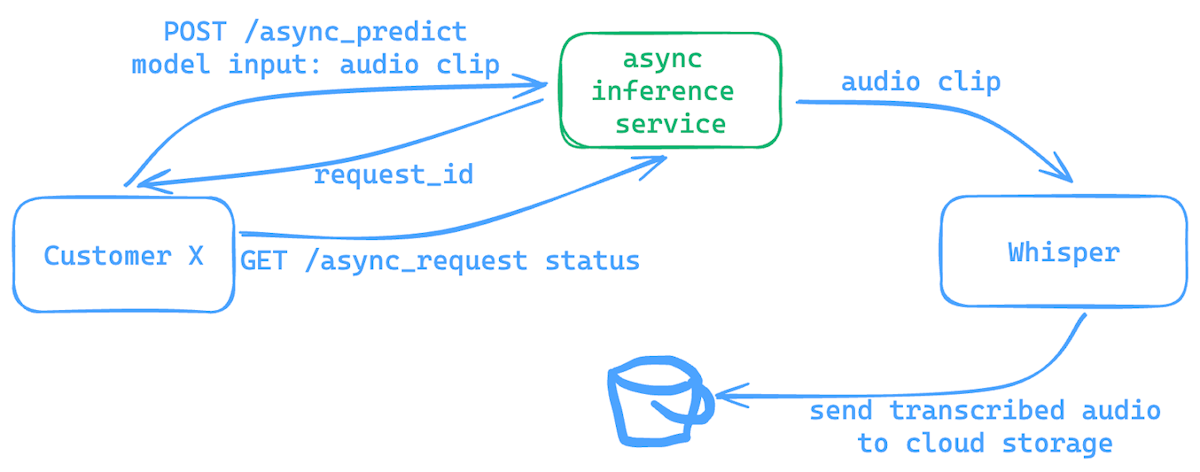
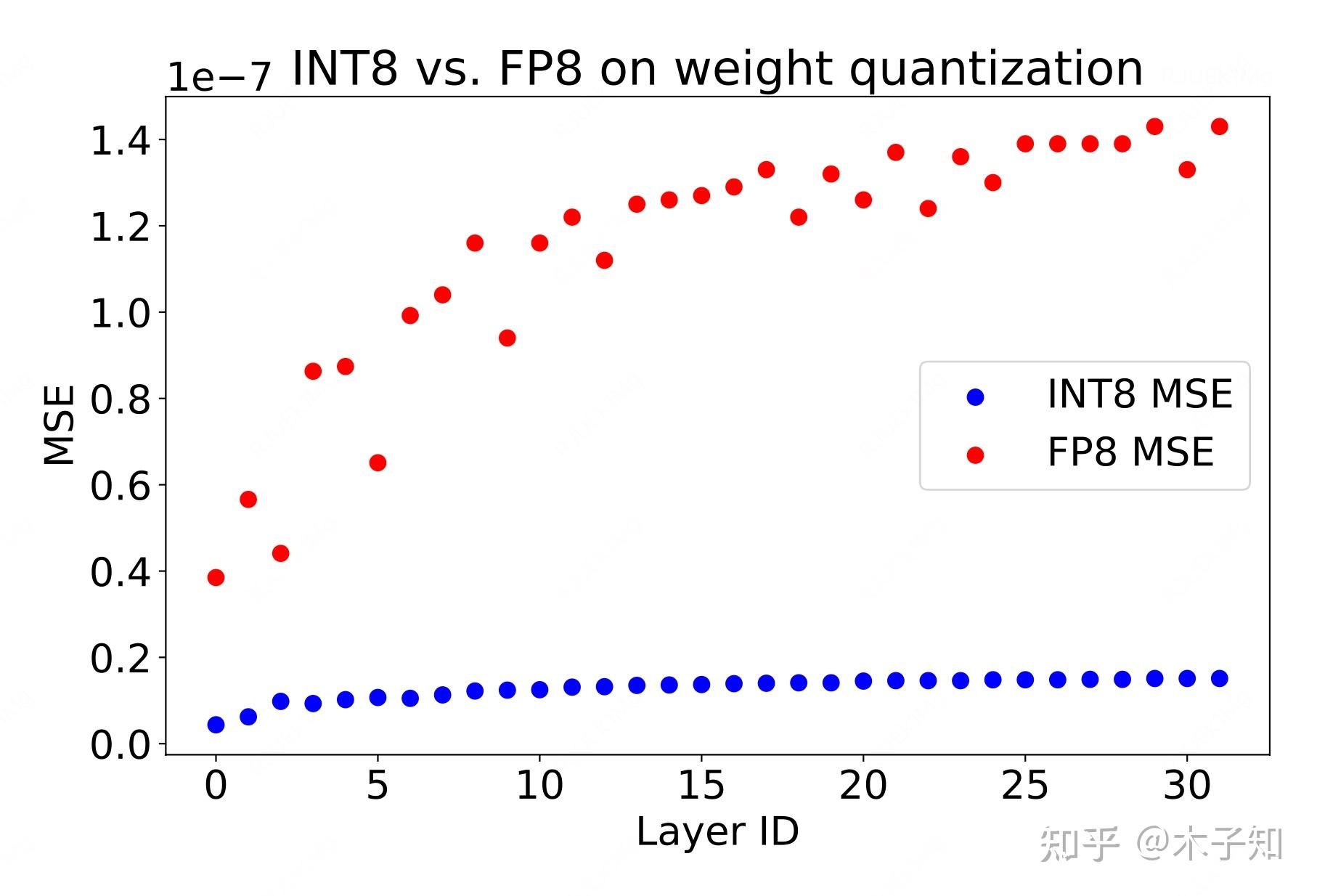
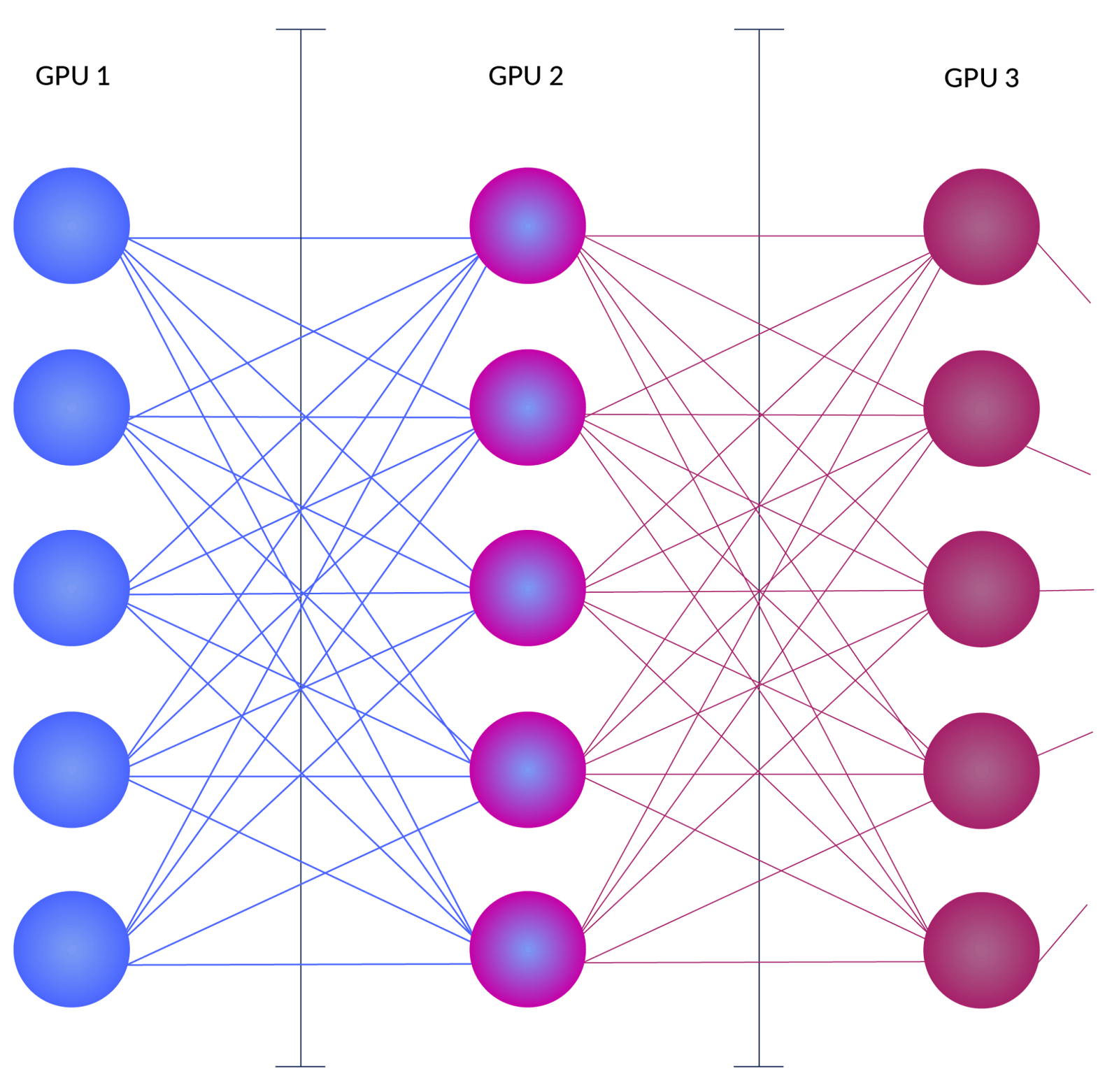
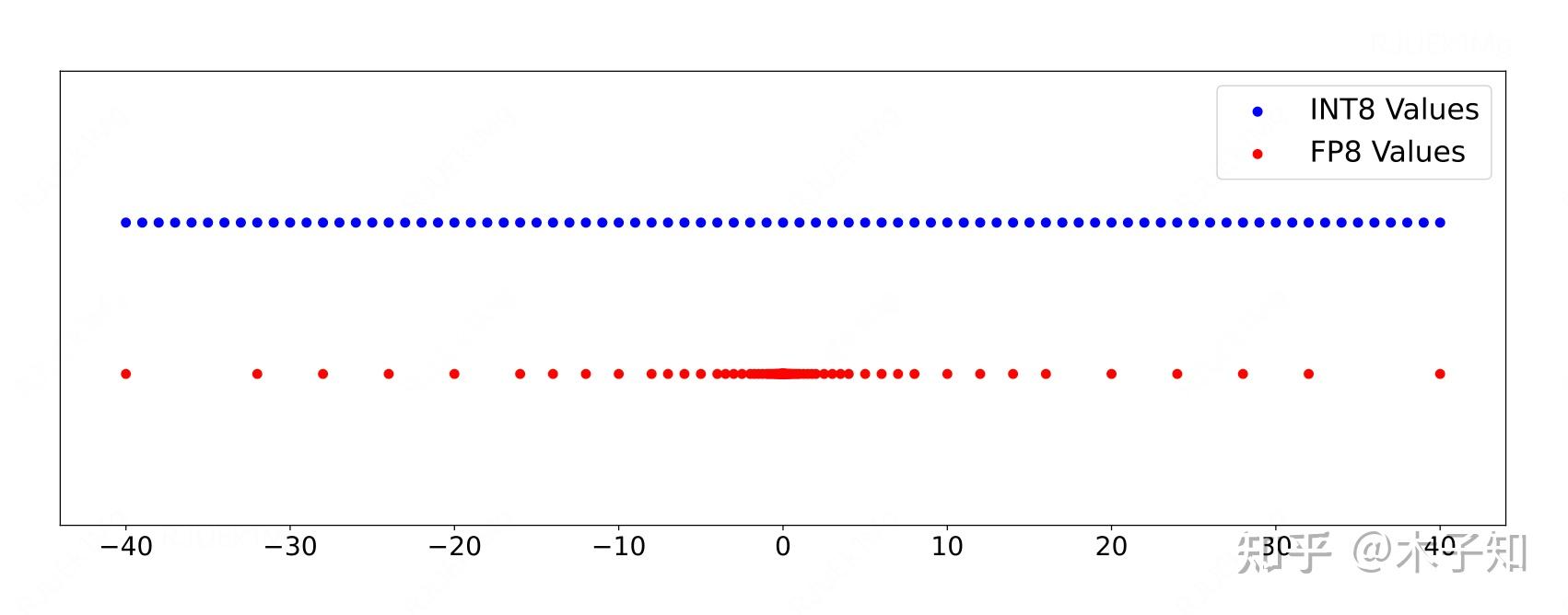
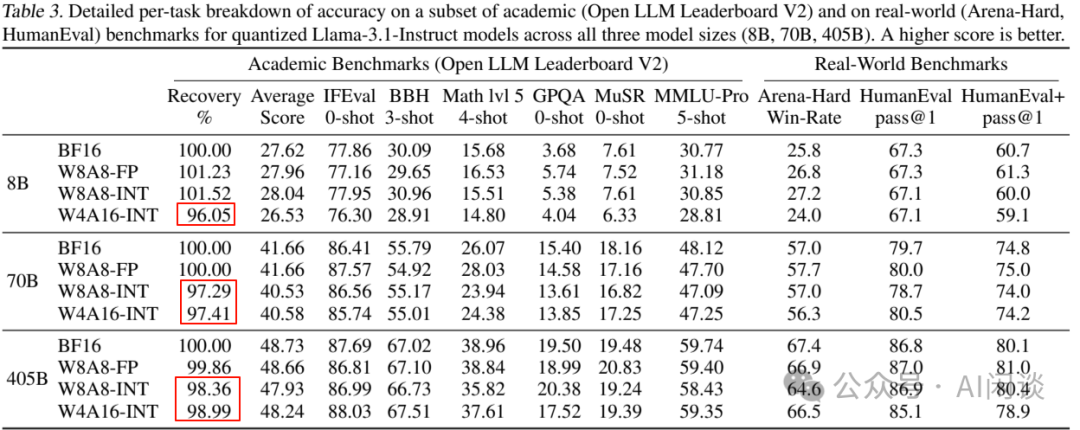
Preserve history with our remarkable historical 33% faster llm inference with fp8 quantization | baseten blog collection of vast arrays of heritage images. legacy-honoring highlighting photography, images, and pictures. designed to preserve historical significance. Our 33% faster llm inference with fp8 quantization | baseten blog collection features high-quality images with excellent detail and clarity. Suitable for various applications including web design, social media, personal projects, and digital content creation All 33% faster llm inference with fp8 quantization | baseten blog images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Explore the versatility of our 33% faster llm inference with fp8 quantization | baseten blog collection for various creative and professional projects. Our 33% faster llm inference with fp8 quantization | baseten blog database continuously expands with fresh, relevant content from skilled photographers. Each image in our 33% faster llm inference with fp8 quantization | baseten blog gallery undergoes rigorous quality assessment before inclusion. The 33% faster llm inference with fp8 quantization | baseten blog archive serves professionals, educators, and creatives across diverse industries. The 33% faster llm inference with fp8 quantization | baseten blog collection represents years of careful curation and professional standards. Advanced search capabilities make finding the perfect 33% faster llm inference with fp8 quantization | baseten blog image effortless and efficient.