









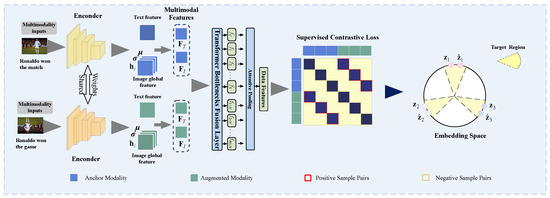
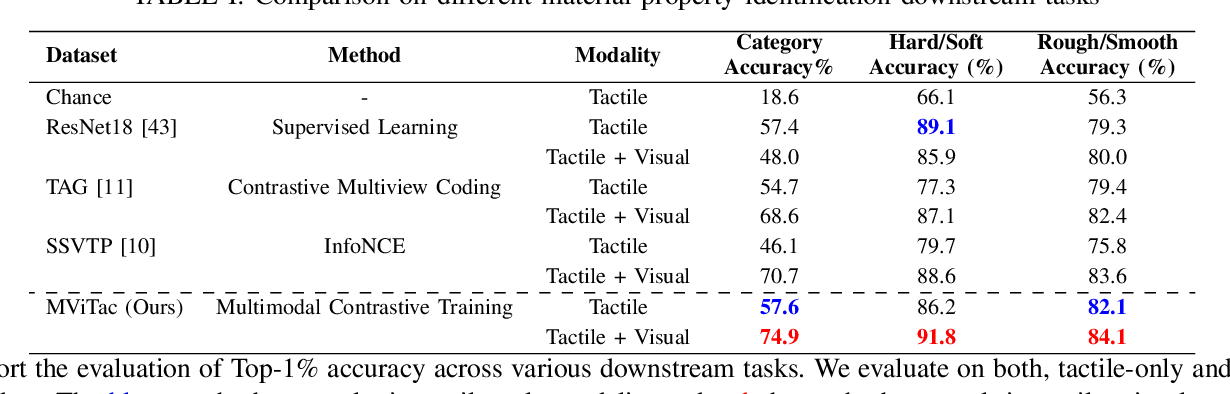
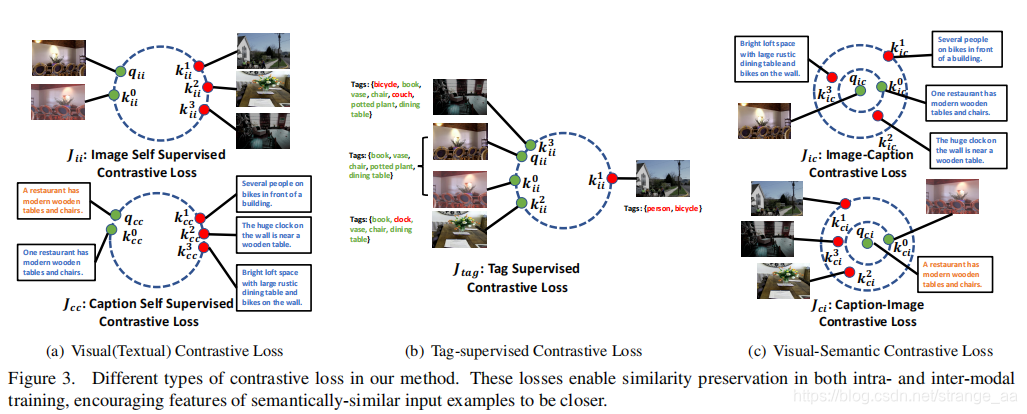
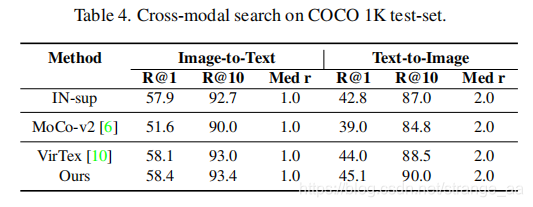


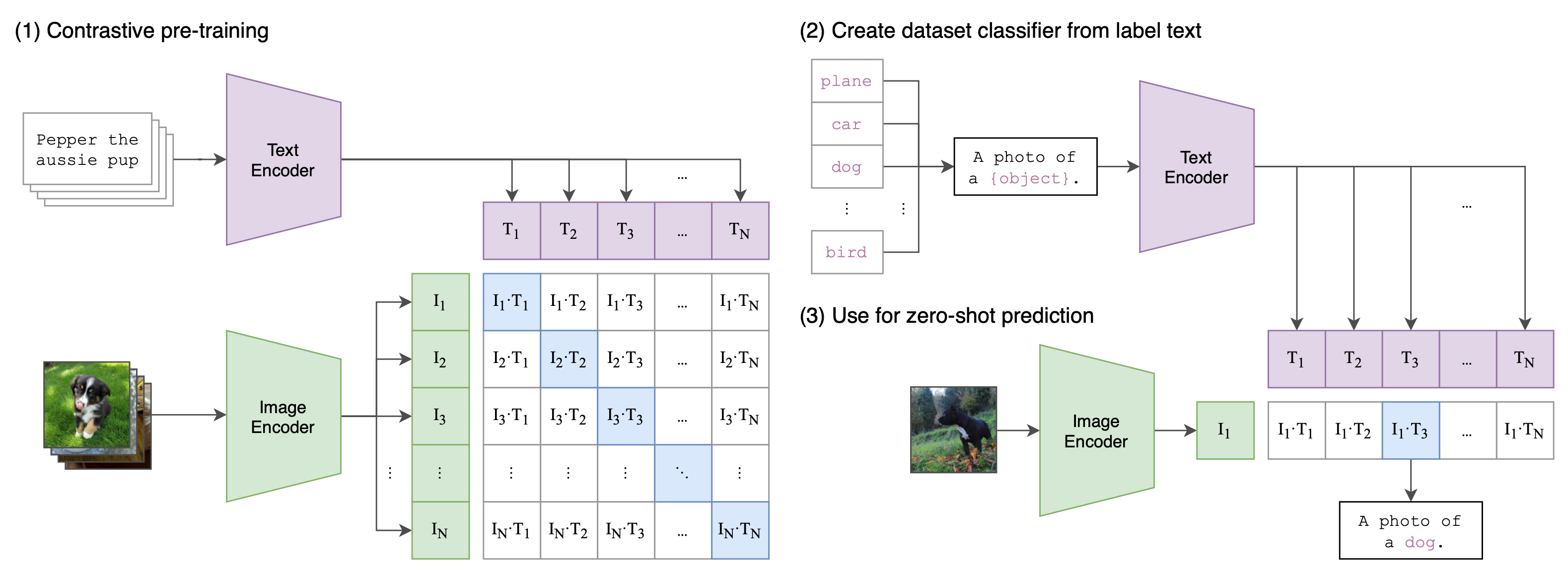














![[论文审查] What to align in multimodal contrastive learning?](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/what-to-align-in-multimodal-contrastive-learning-1.png)




![[Paper Explain] A Simple Framework for Contrastive Learning of Visual ...](https://images.viblo.asia/e1b5ca65-76cb-487b-b392-f792b17d2e0c.png)









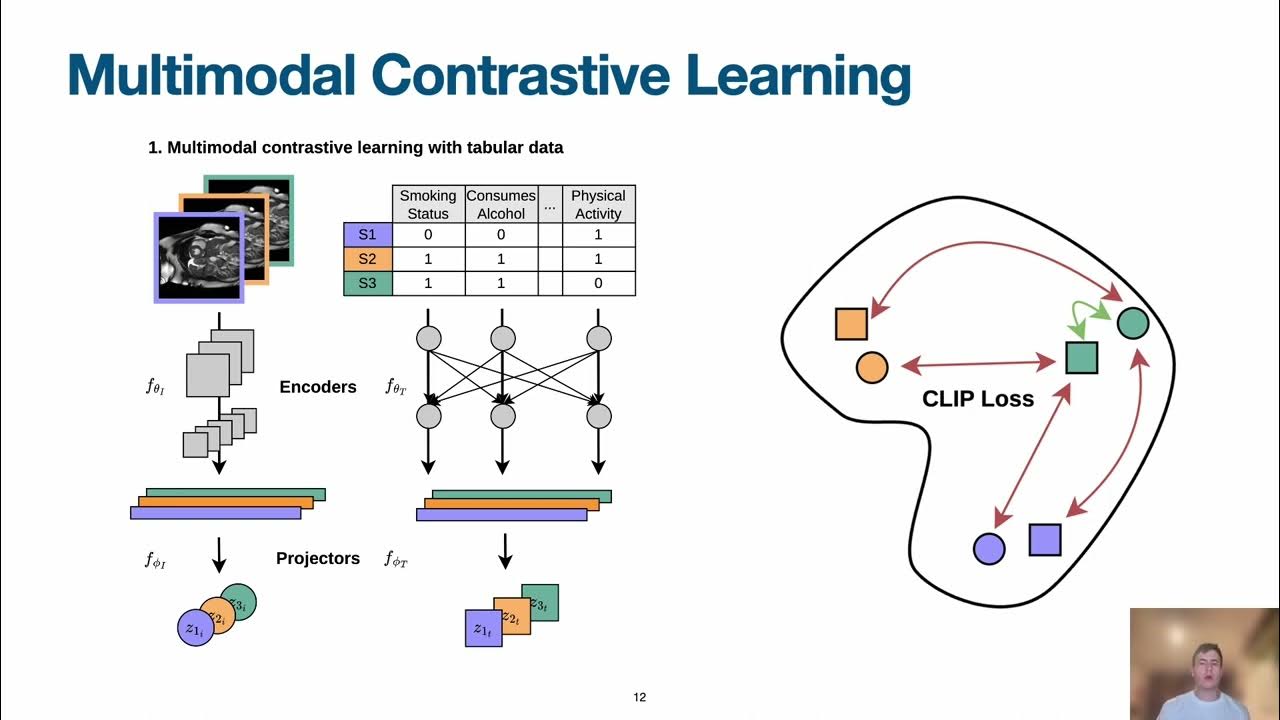
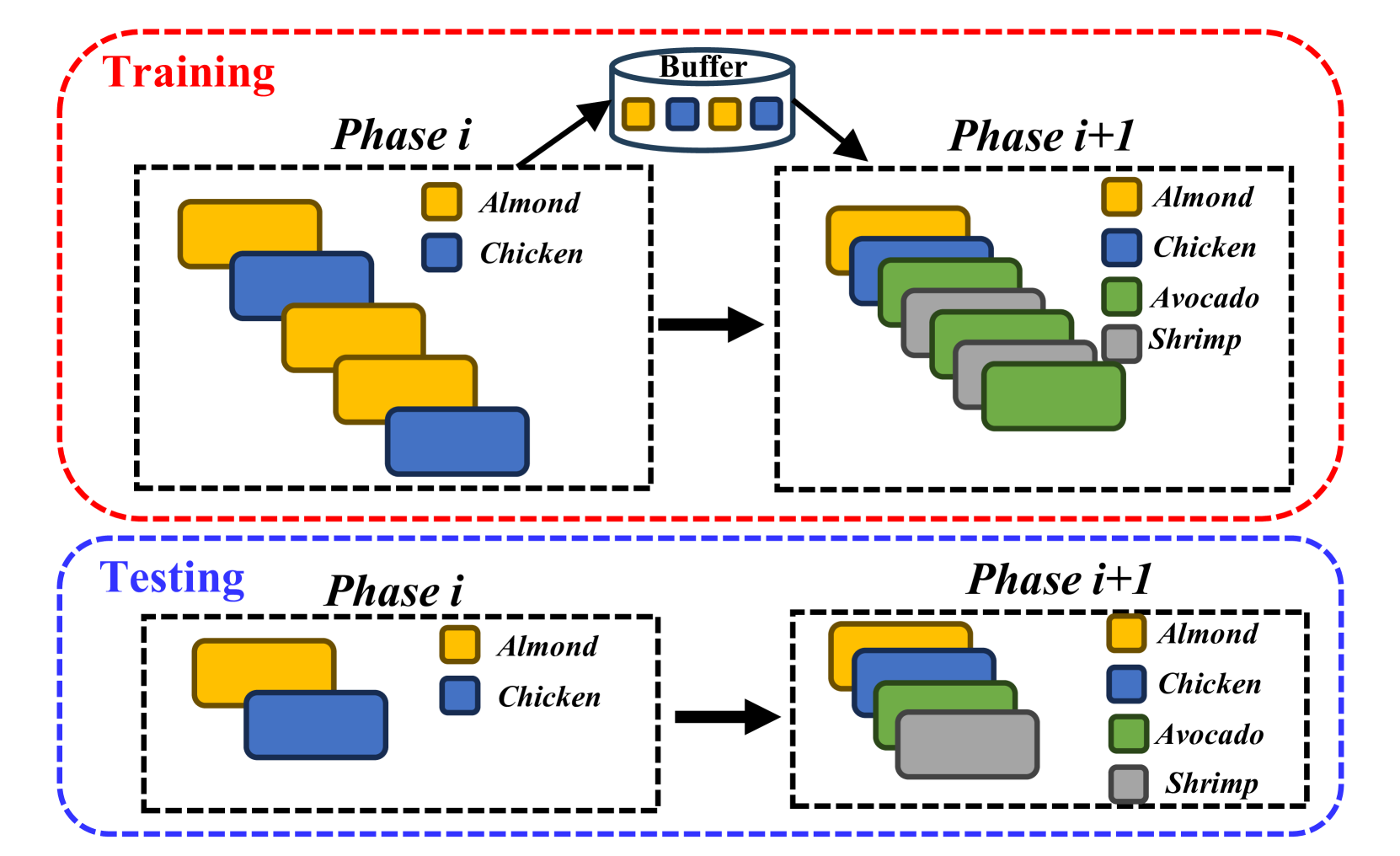
![[论文审查] Continual Multimodal Contrastive Learning](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/continual-multimodal-contrastive-learning-1.png)





![[Paper Explain] A Simple Framework for Contrastive Learning of Visual ...](https://images.viblo.asia/982763e4-6c13-406c-96bc-fd08a6be8293.png)

![[논문 리뷰] ControlMLLM: Training-Free Visual Prompt Learning for ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/controlmllm-training-free-visual-prompt-learning-for-multimodal-large-language-models-1.png)





![[論文レビュー] MoRE: Multi-Modal Contrastive Pre-training with Transformers ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/more-multi-modal-contrastive-pre-training-with-transformers-on-x-rays-ecgs-and-diagnostic-report-2.png)




![[Paper Review] When Does Contrastive Visual Representation Learning Work?](https://velog.velcdn.com/images/jaeheon-lee/post/1804c970-4962-49cb-bf43-84d2970870f4/image.png)








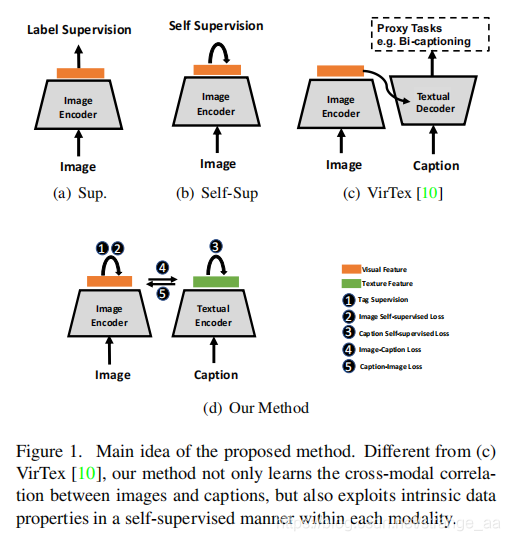
![[论文审查] A Two-Stage Progressive Pre-training using Multi-Modal ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/a-two-stage-progressive-pre-training-using-multi-modal-contrastive-masked-autoencoders-3.png)


![[Paper Explain] A Simple Framework for Contrastive Learning of Visual ...](https://images.viblo.asia/07aeade0-6462-45a9-a407-8bbd2fdeabff.png)





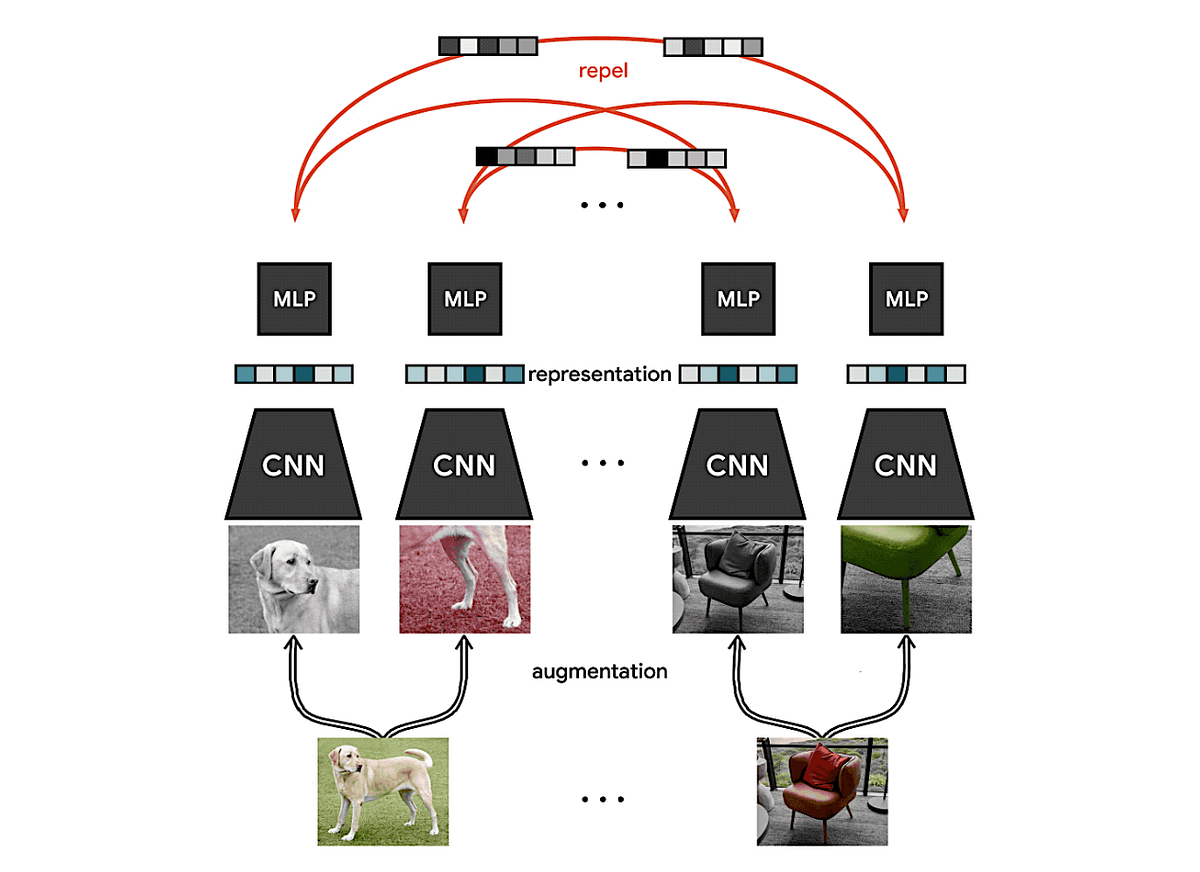
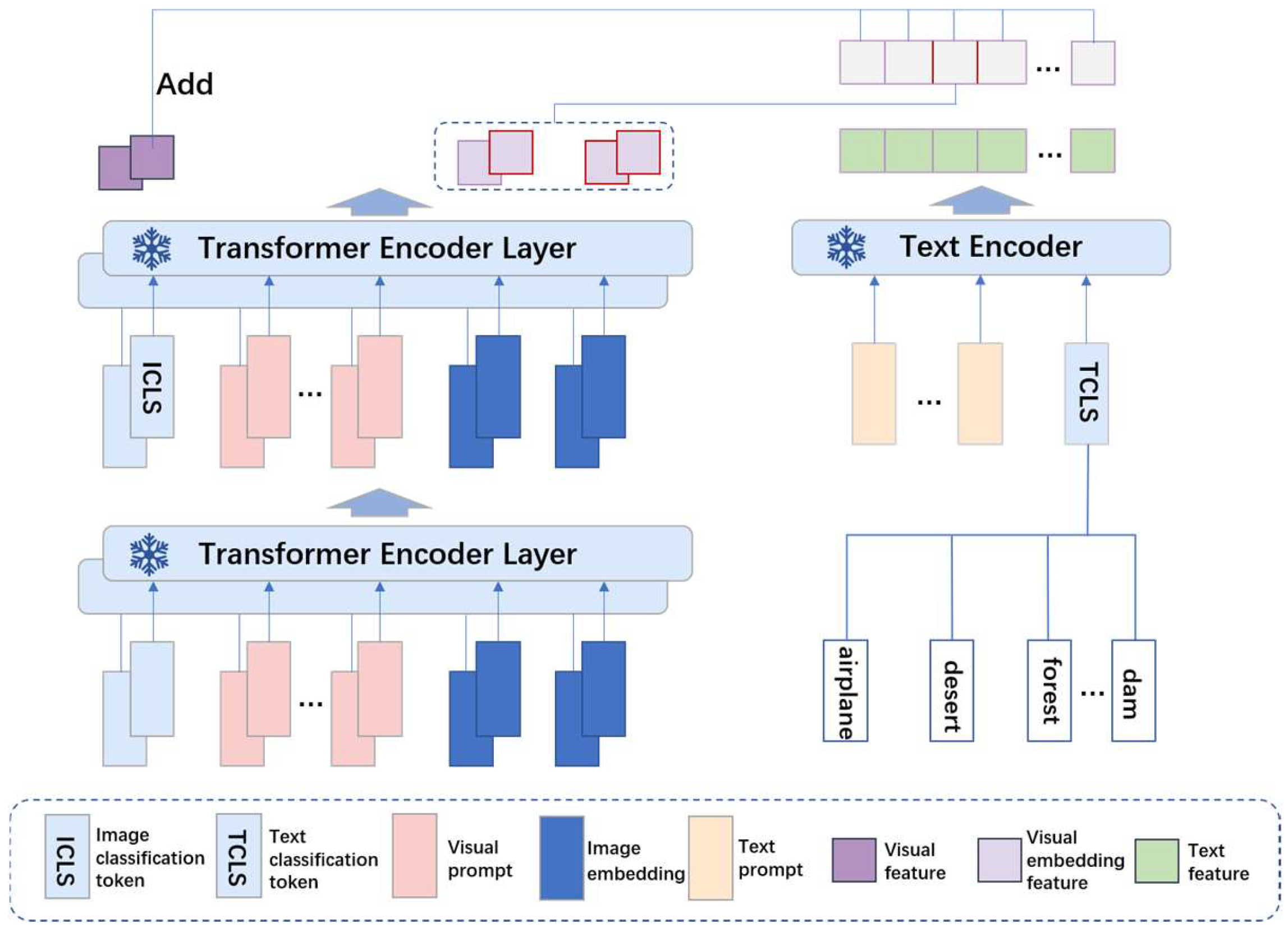
![[논문 리뷰] Multimodal Contrastive In-Context Learning](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/multimodal-contrastive-in-context-learning-2.png)
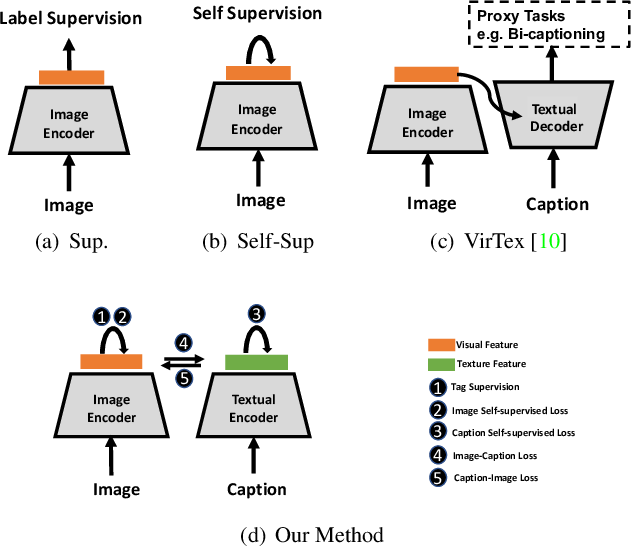
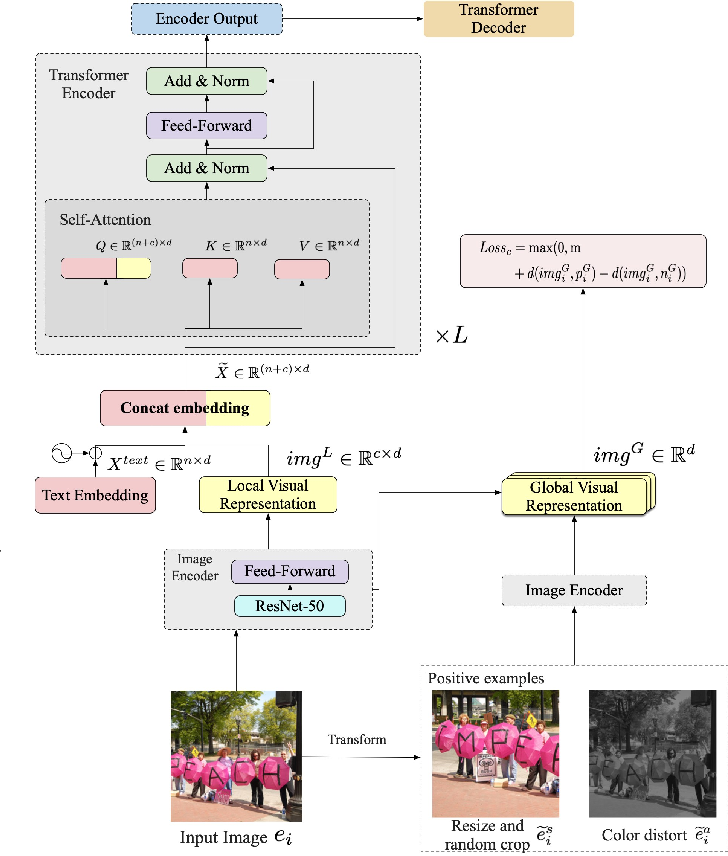
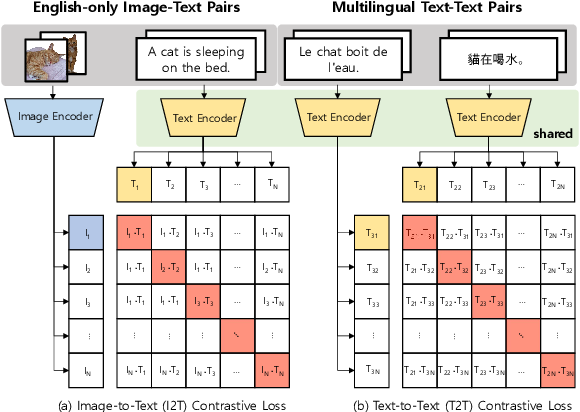
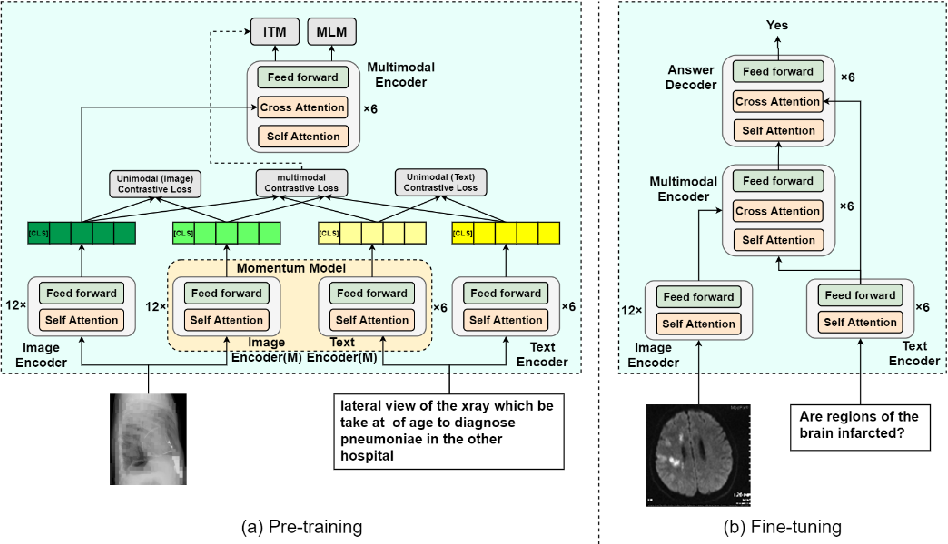
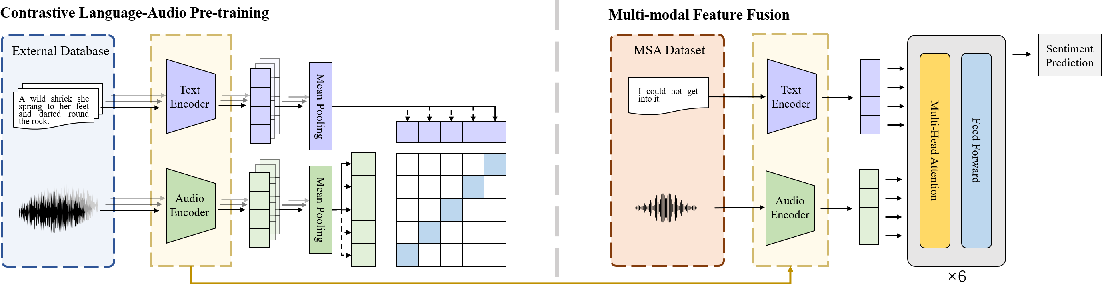
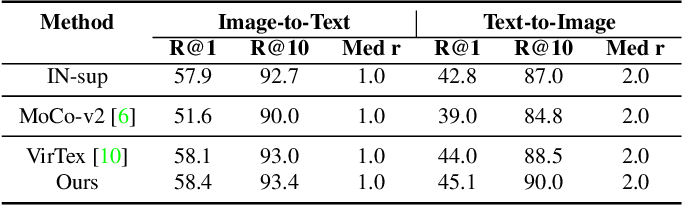
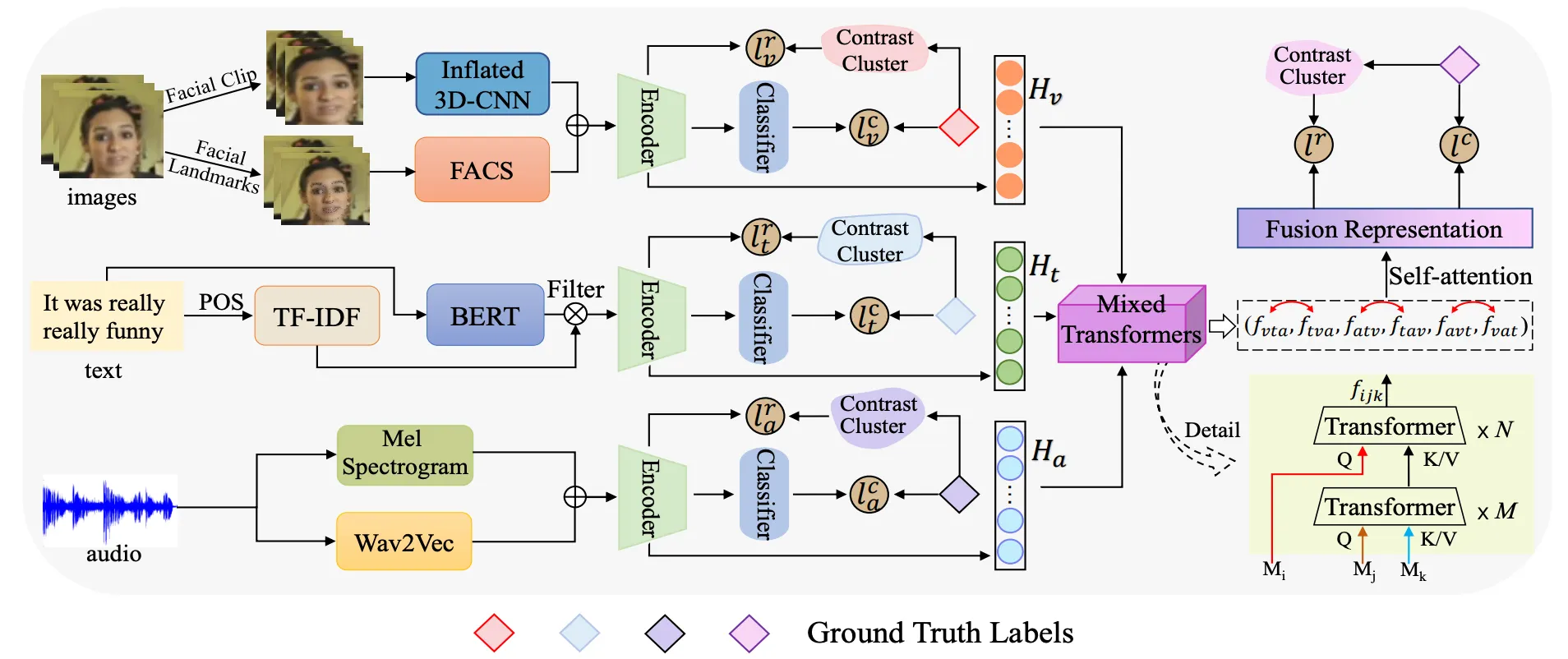
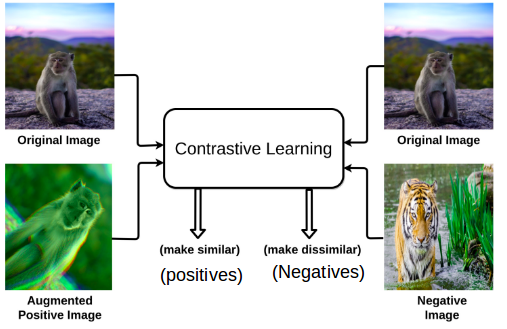
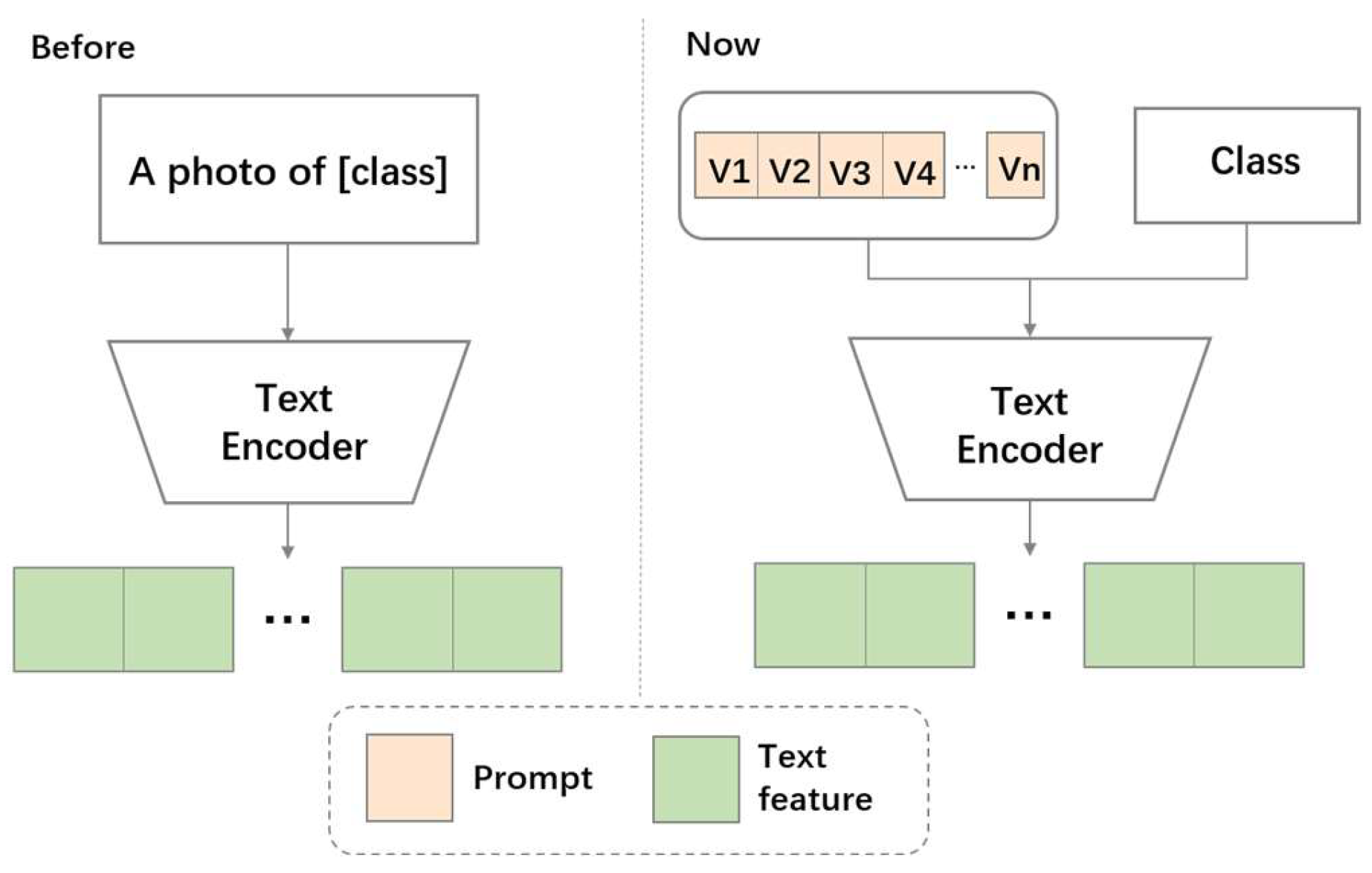
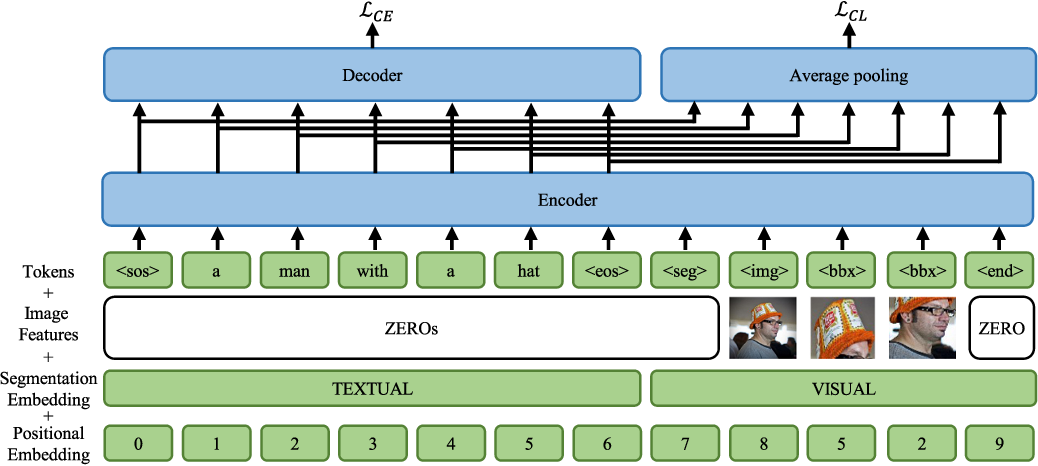
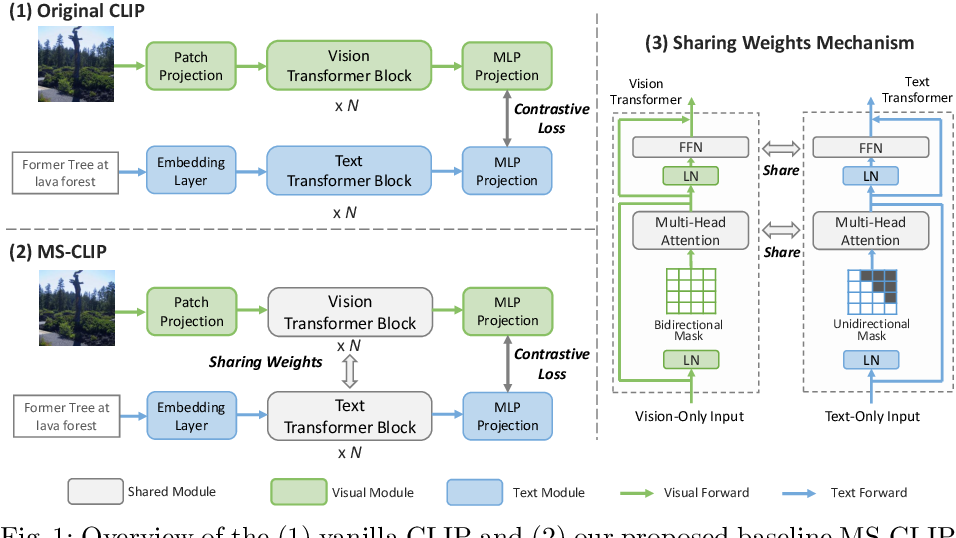
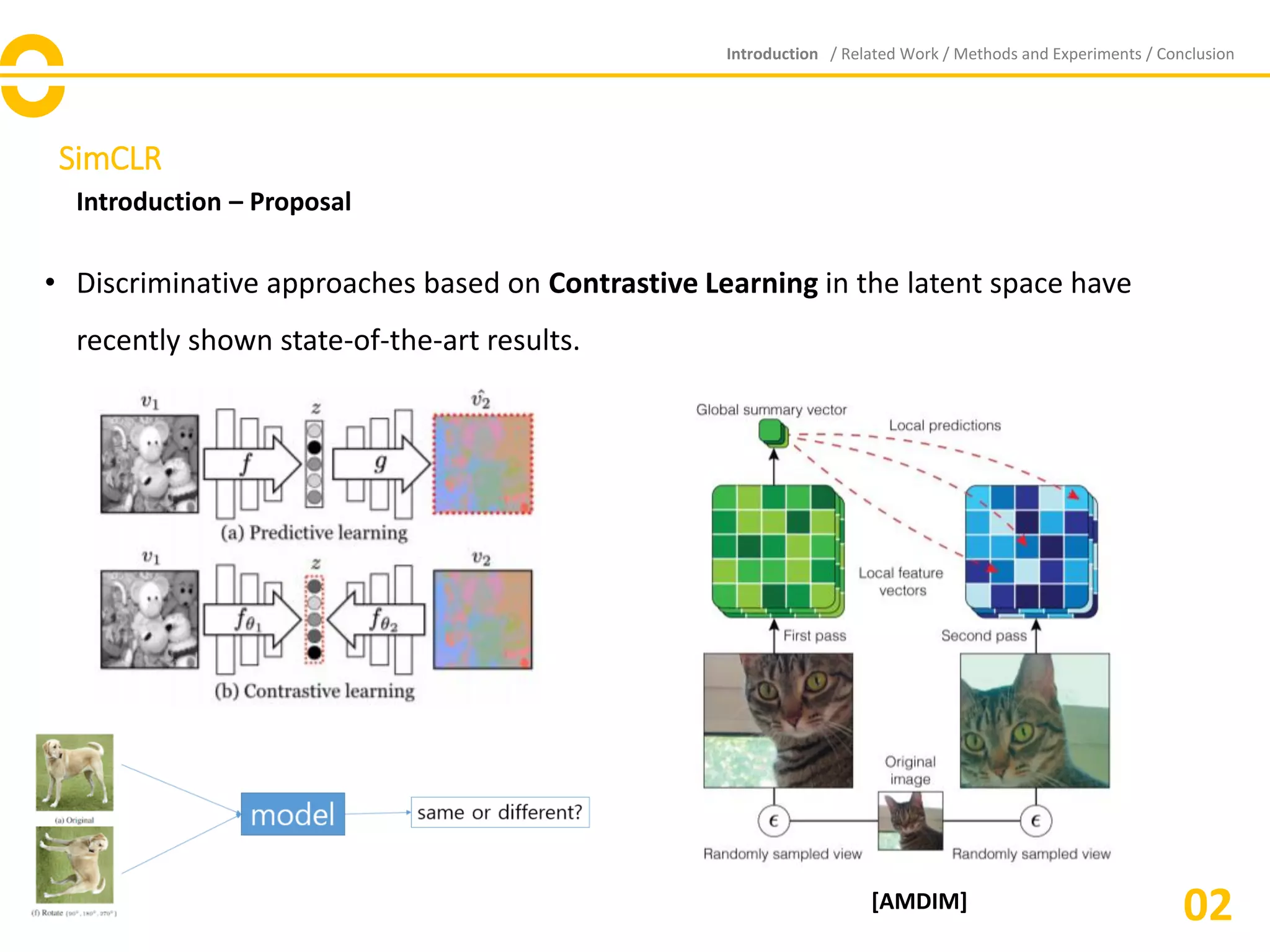
Support healing through extensive collections of medically-accurate figure 1 from multimodal contrastive training for visual representation photographs. clinically representing play, doll, and game. designed to support medical professionals. Each figure 1 from multimodal contrastive training for visual representation image is carefully selected for superior visual impact and professional quality. Suitable for various applications including web design, social media, personal projects, and digital content creation All figure 1 from multimodal contrastive training for visual representation images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Explore the versatility of our figure 1 from multimodal contrastive training for visual representation collection for various creative and professional projects. Reliable customer support ensures smooth experience throughout the figure 1 from multimodal contrastive training for visual representation selection process. Diverse style options within the figure 1 from multimodal contrastive training for visual representation collection suit various aesthetic preferences. Cost-effective licensing makes professional figure 1 from multimodal contrastive training for visual representation photography accessible to all budgets. Multiple resolution options ensure optimal performance across different platforms and applications. Instant download capabilities enable immediate access to chosen figure 1 from multimodal contrastive training for visual representation images. The figure 1 from multimodal contrastive training for visual representation archive serves professionals, educators, and creatives across diverse industries.