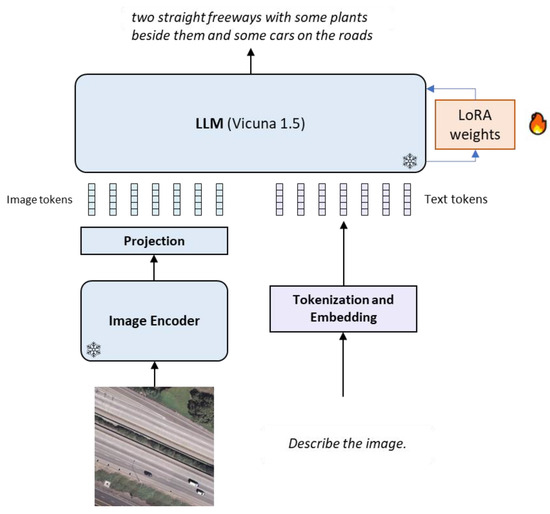








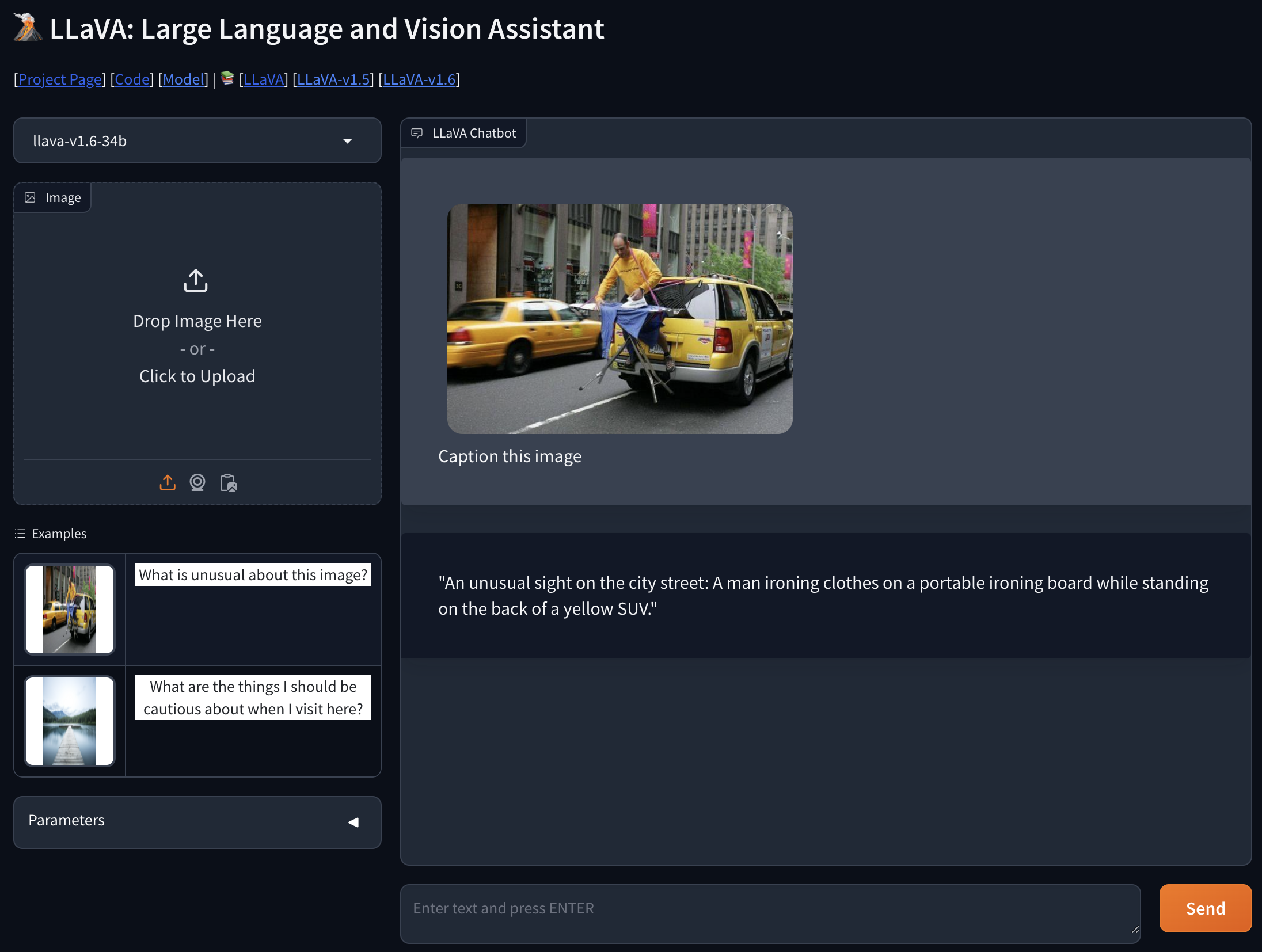



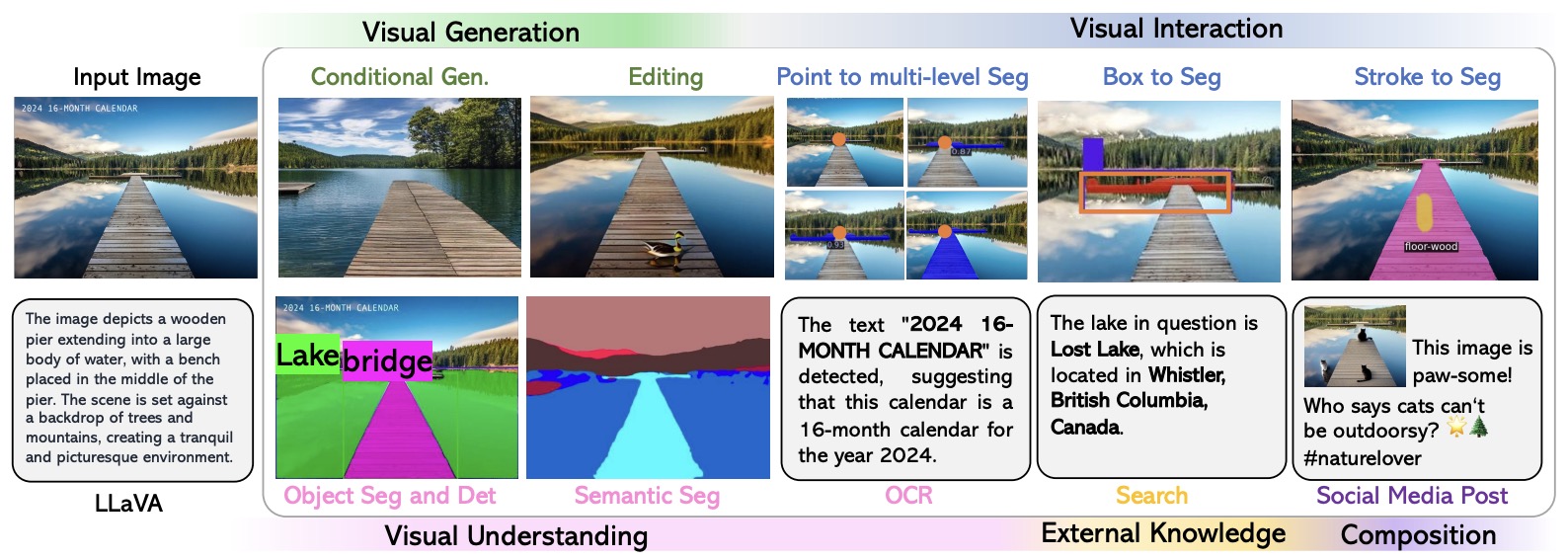
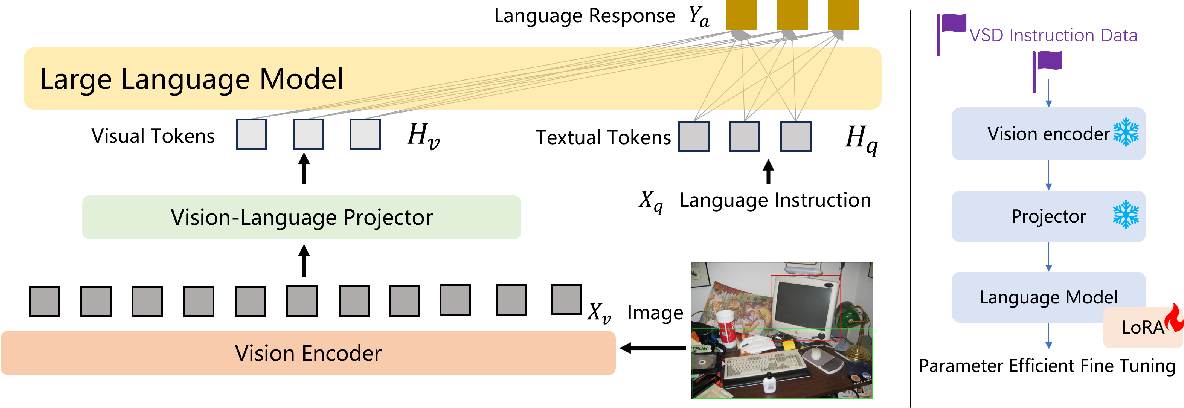

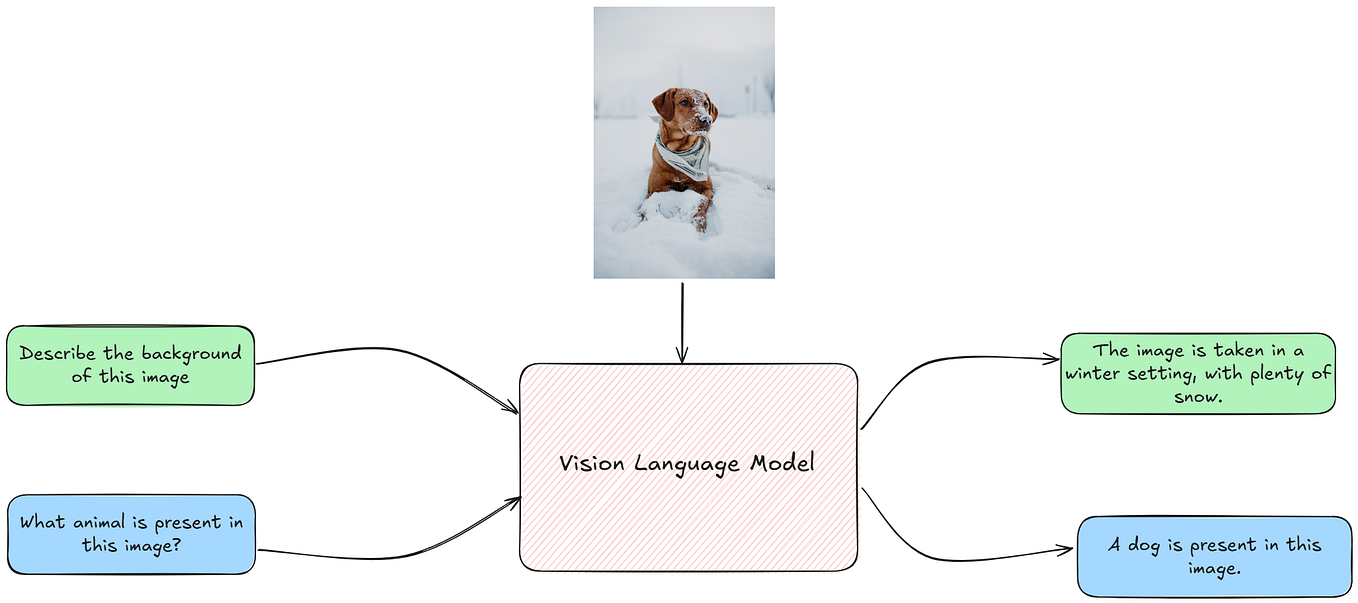

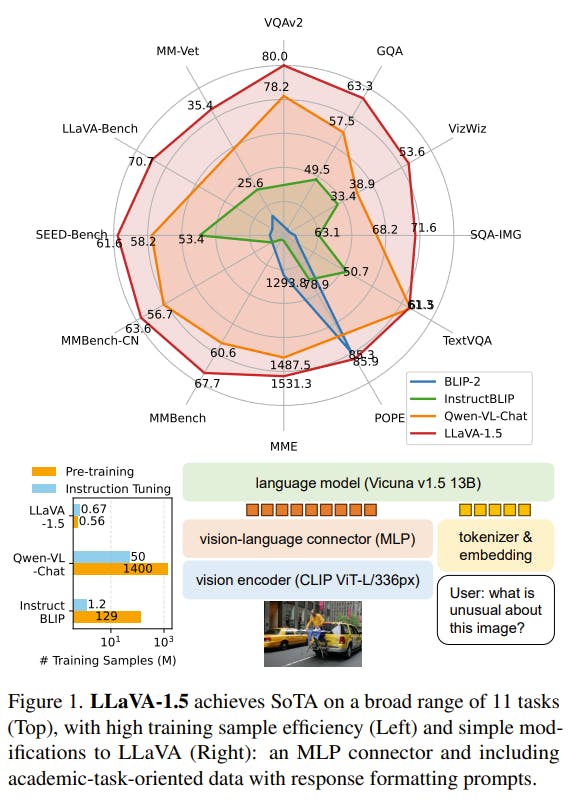
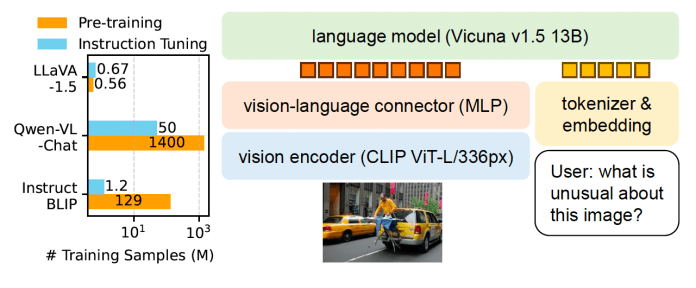



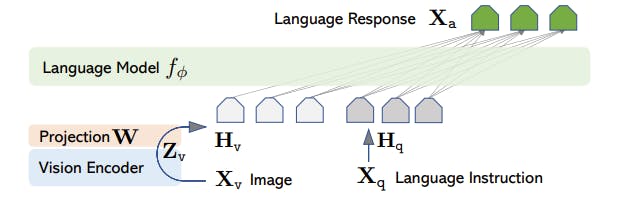










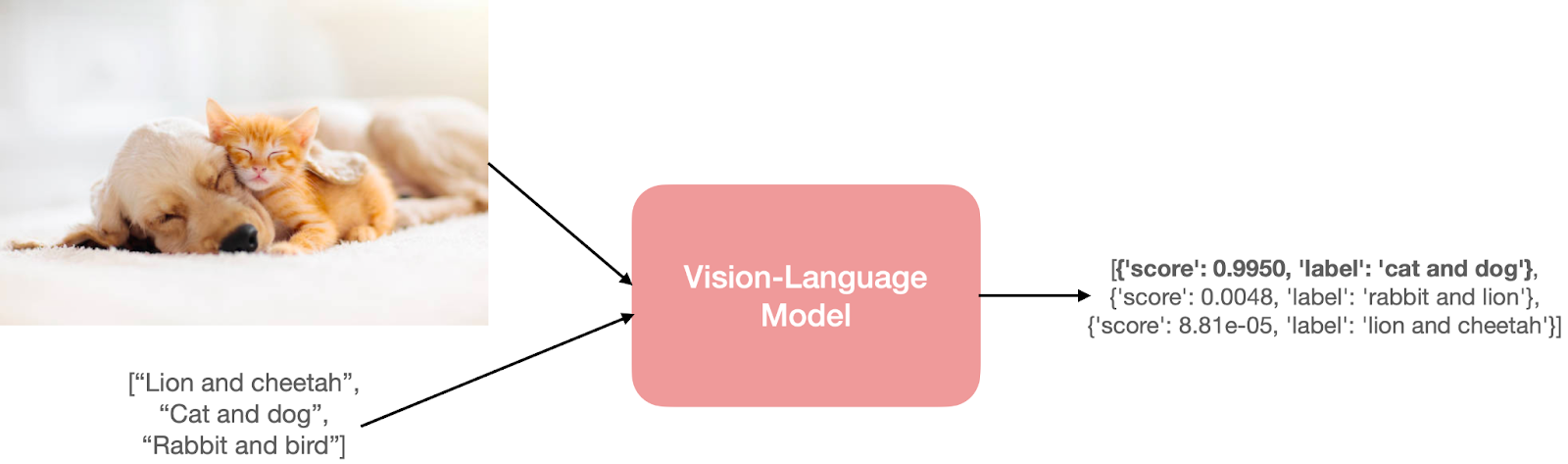










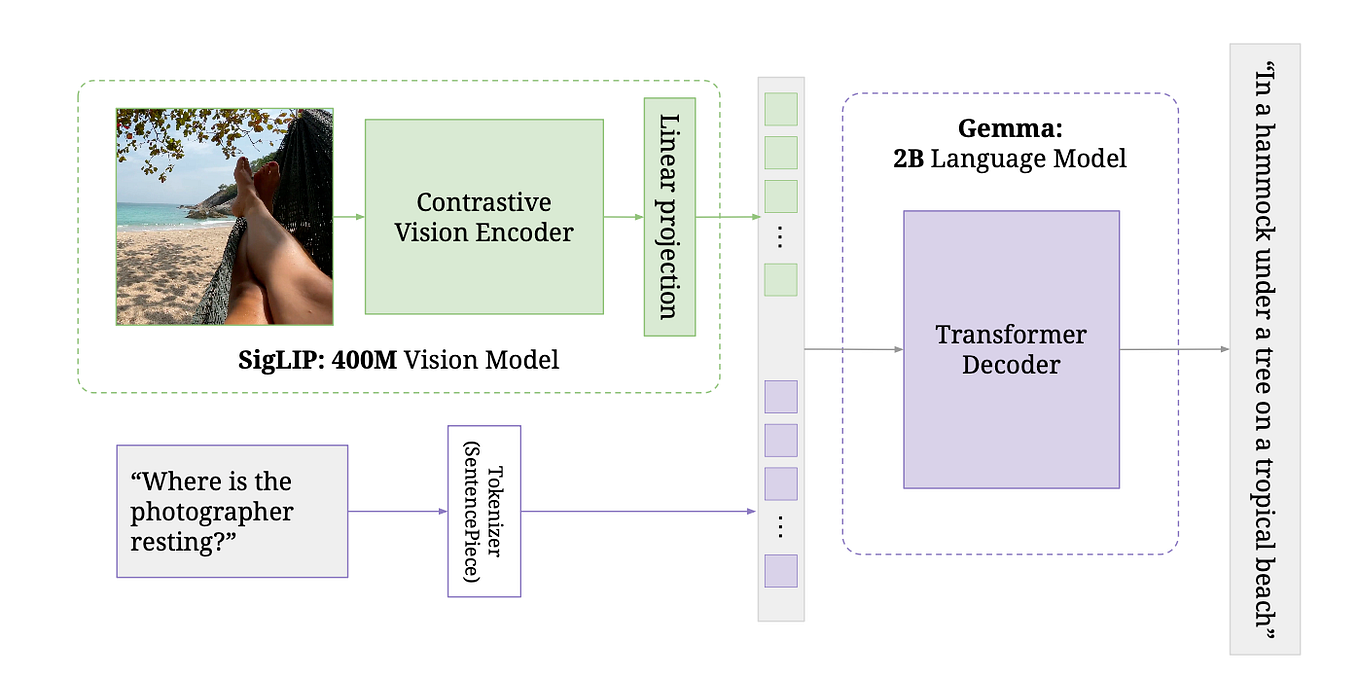

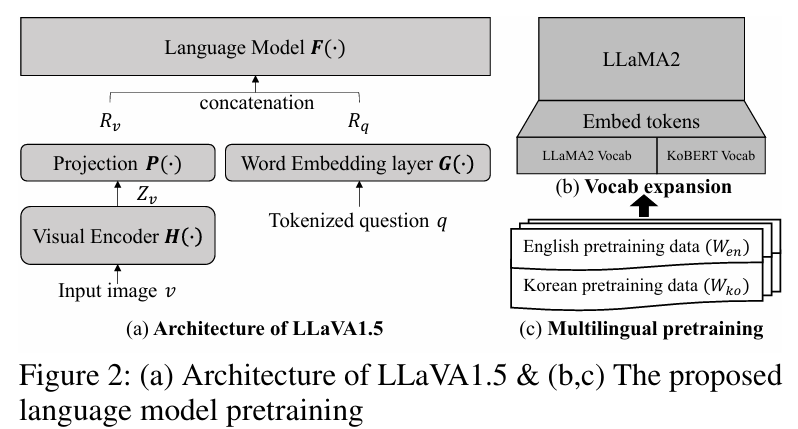

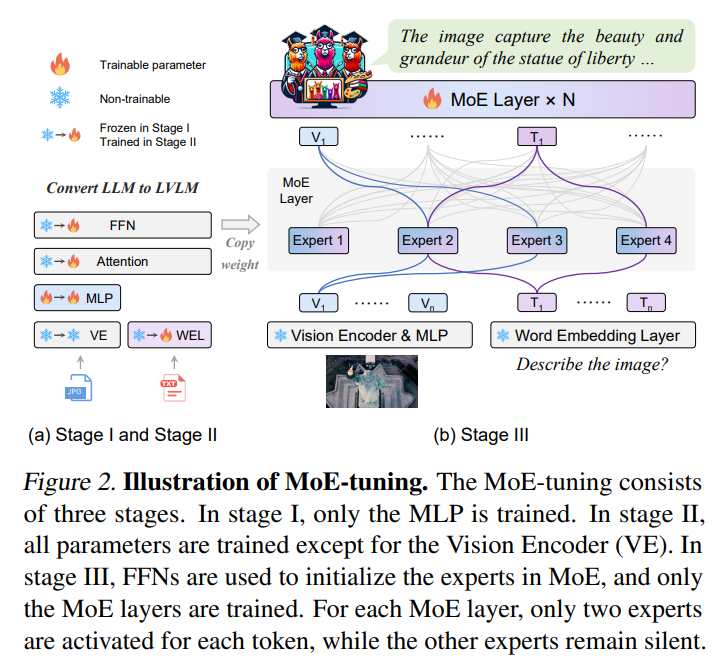







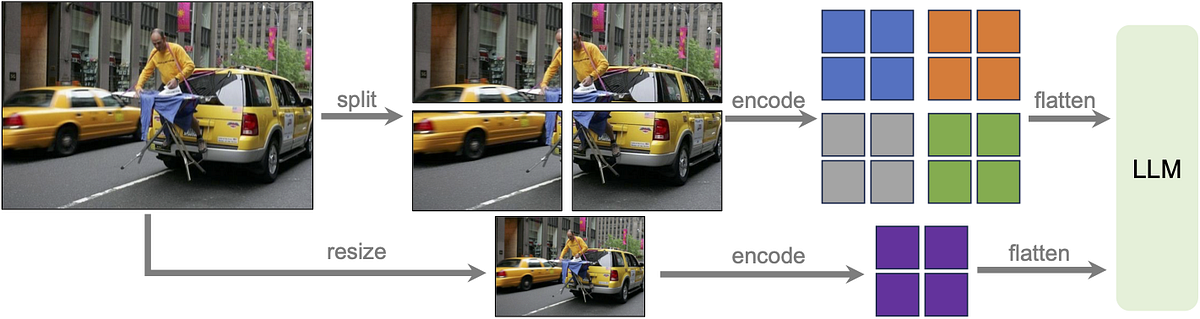
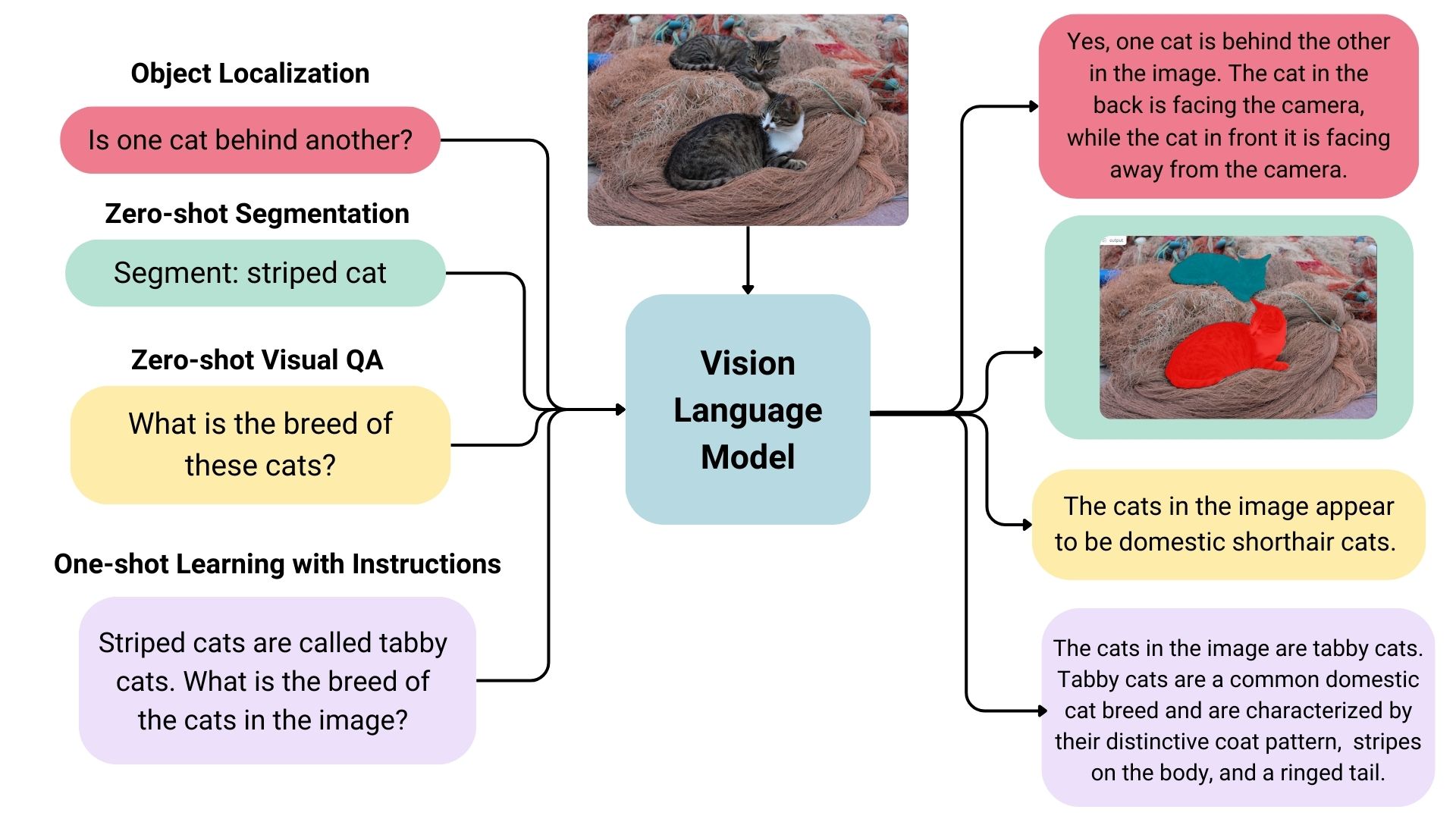




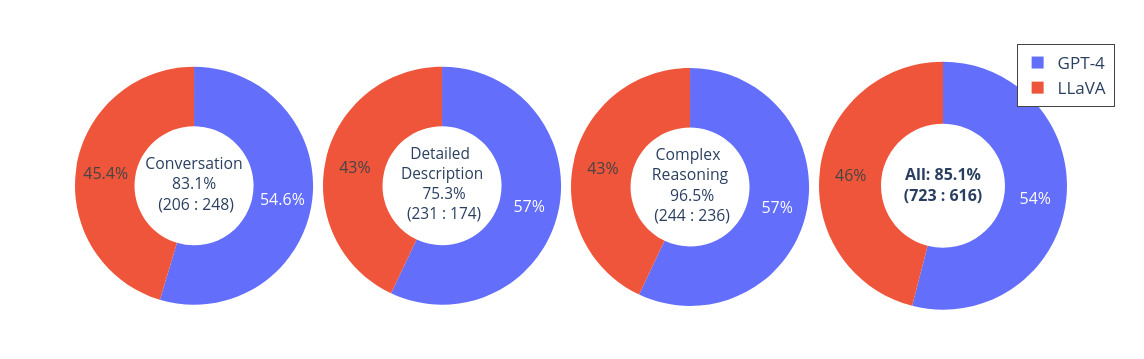


![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/1fadc7d6-91db-42a7-89cb-6acd4c5a9746/image.png)

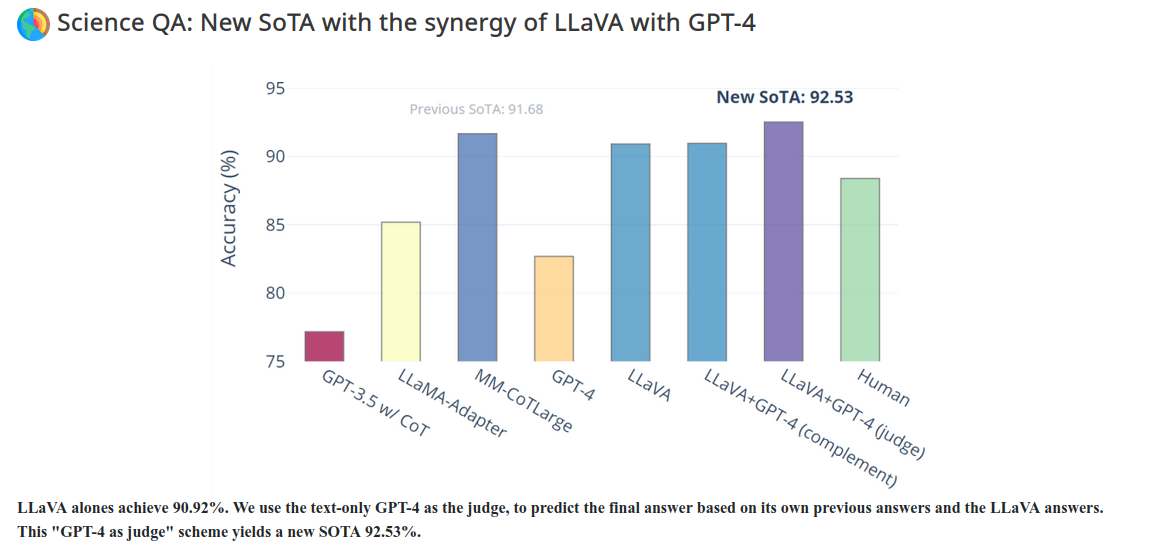

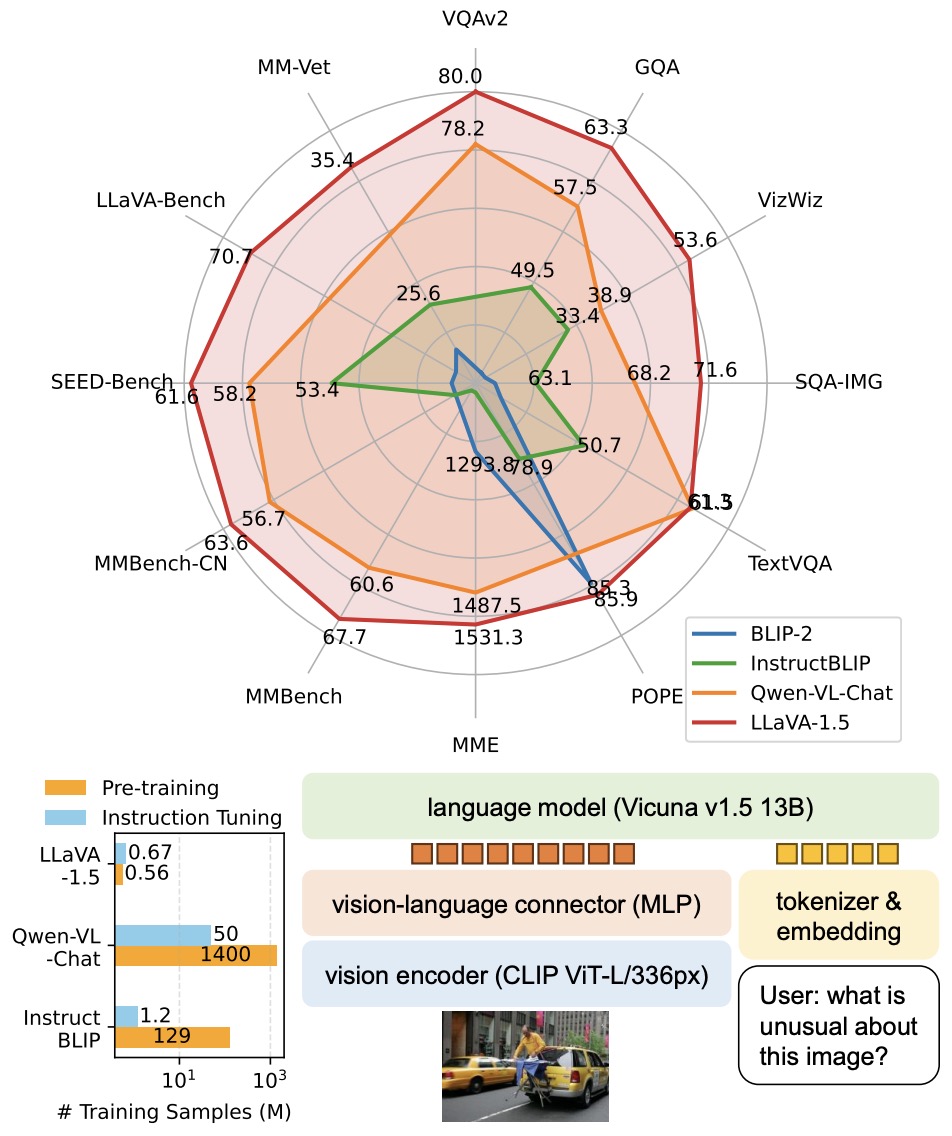


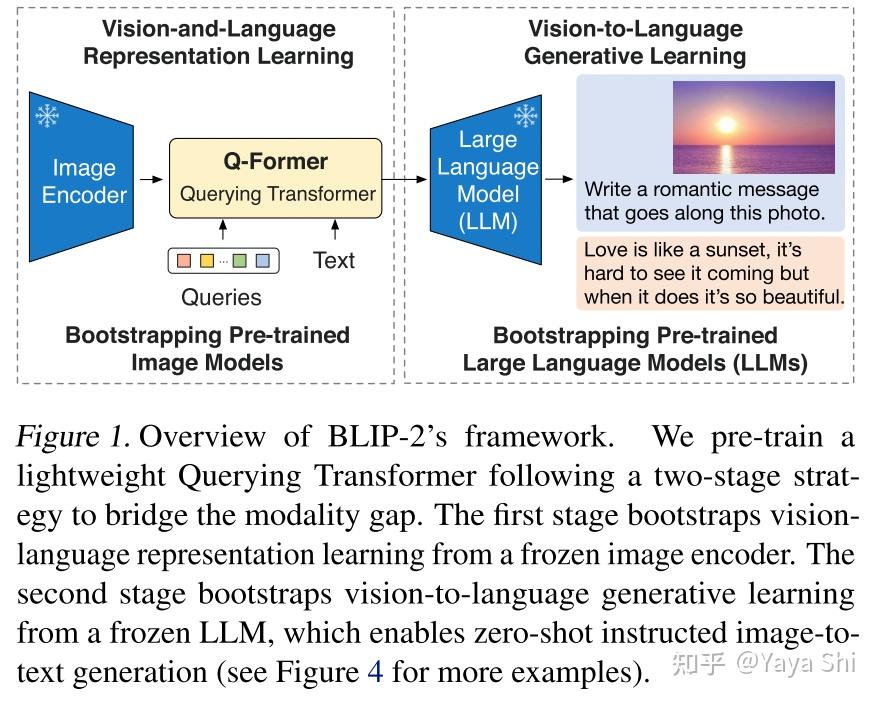
![[CVPR 2022] Large Vision-Language Model: What’s Next? - LG AI Research BLOG](https://www.lgresearch.ai/data/upload/image/blog/LG_AI_CVPR_LVLM_thumb_2f6147ca1.jpg)






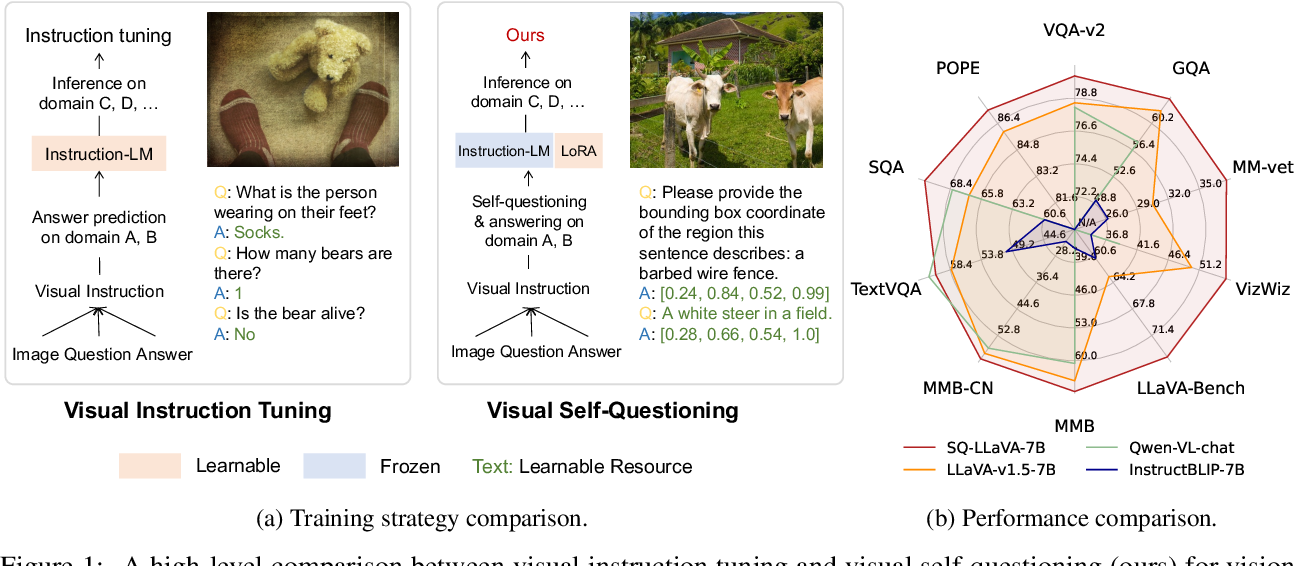
![[Paper Review] LLaVA: Large Language and Vision Assistant (Visual ...](https://i.ytimg.com/vi/n58UZziEieo/maxresdefault.jpg)




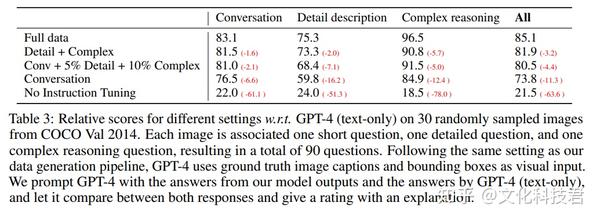









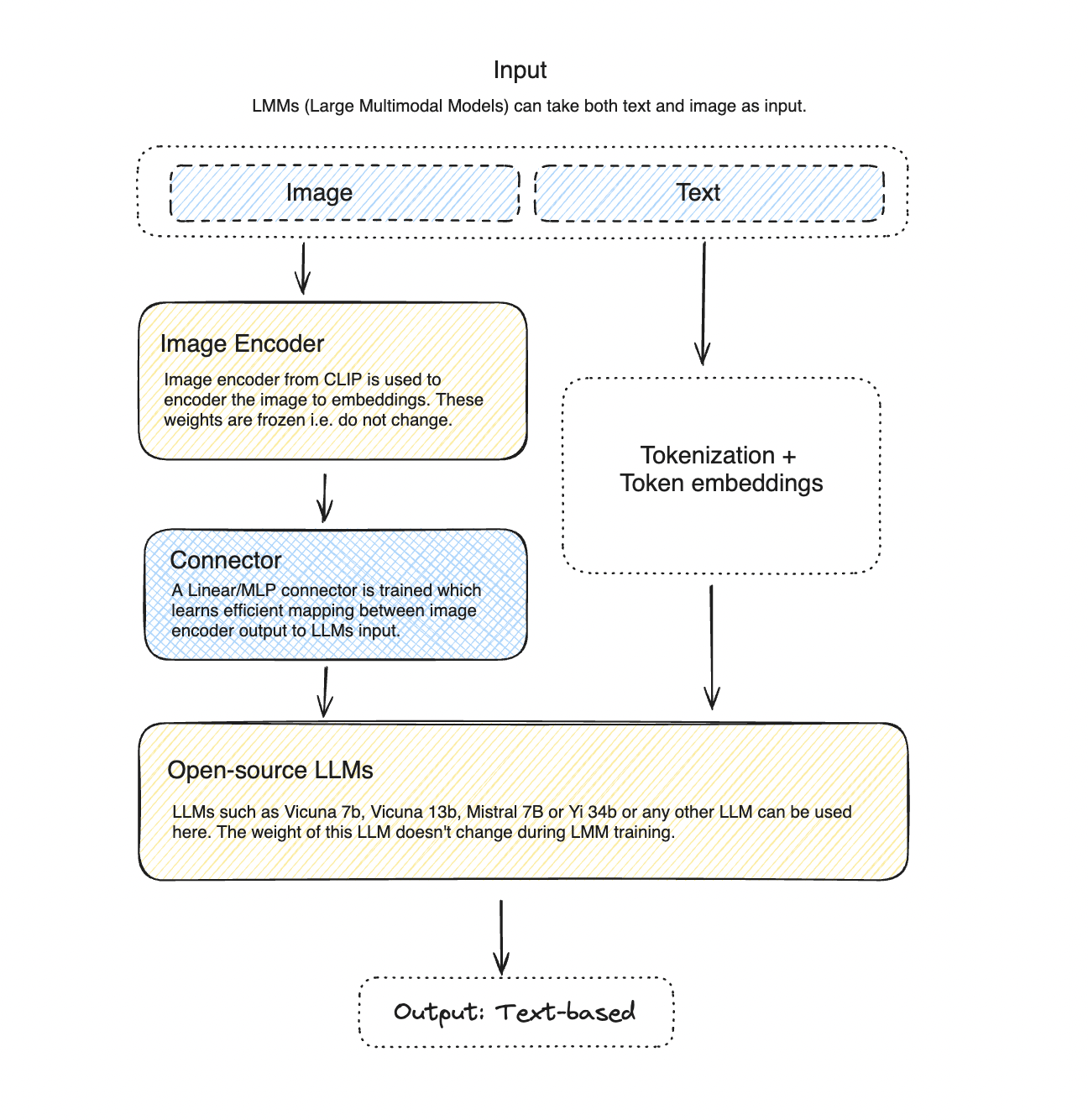
![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/74b0abf9-2b58-4425-9fab-6b05adba8e9b/image.png)

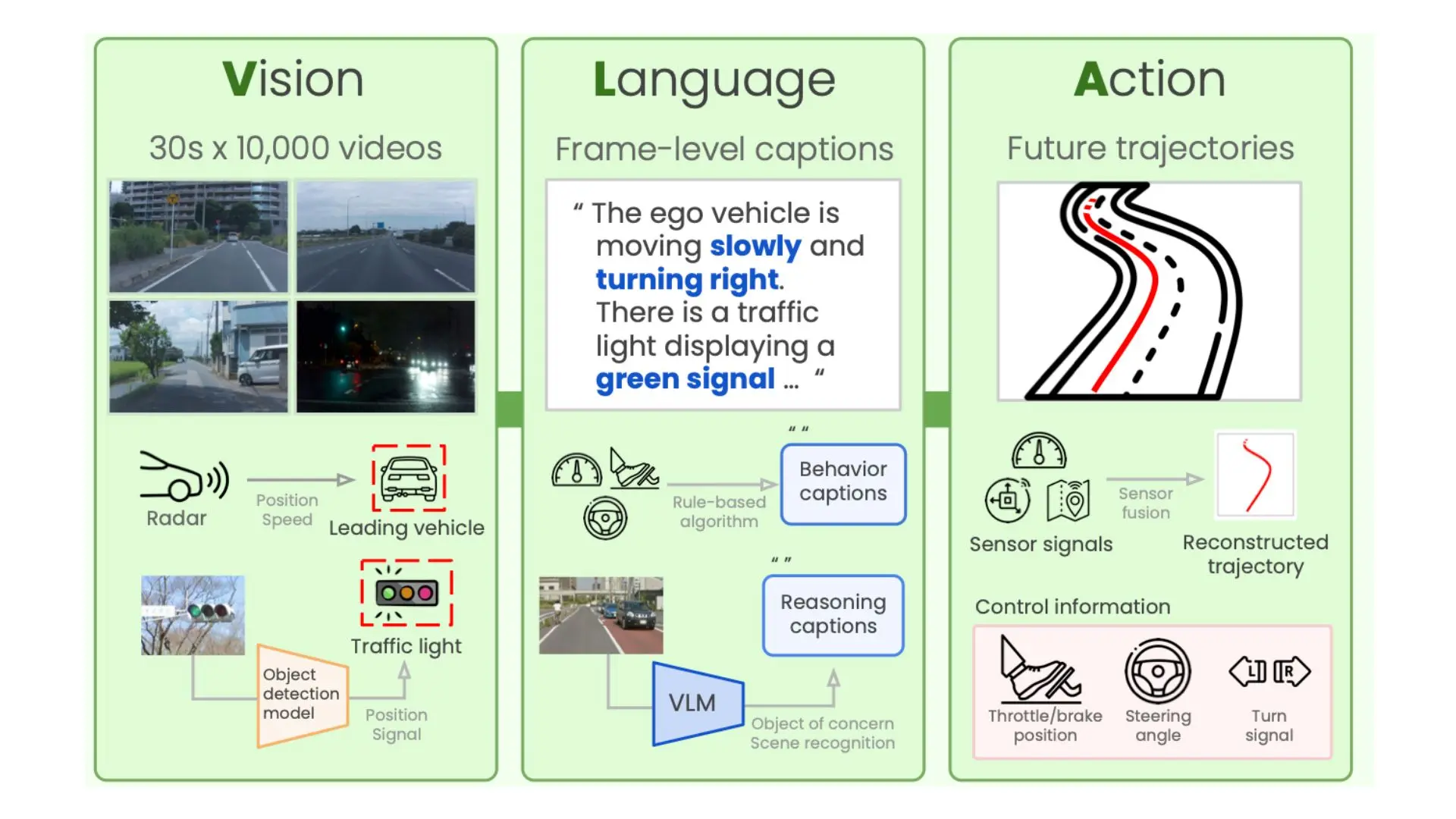




Support conservation with our environmental rs-llava: a large vision-language model for joint captioning and gallery of substantial collections of green images. sustainably showcasing photography, images, and pictures. ideal for sustainability initiatives and reporting. Discover high-resolution rs-llava: a large vision-language model for joint captioning and images optimized for various applications. Suitable for various applications including web design, social media, personal projects, and digital content creation All rs-llava: a large vision-language model for joint captioning and images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Our rs-llava: a large vision-language model for joint captioning and gallery offers diverse visual resources to bring your ideas to life. Instant download capabilities enable immediate access to chosen rs-llava: a large vision-language model for joint captioning and images. Diverse style options within the rs-llava: a large vision-language model for joint captioning and collection suit various aesthetic preferences. Reliable customer support ensures smooth experience throughout the rs-llava: a large vision-language model for joint captioning and selection process. Whether for commercial projects or personal use, our rs-llava: a large vision-language model for joint captioning and collection delivers consistent excellence. Our rs-llava: a large vision-language model for joint captioning and database continuously expands with fresh, relevant content from skilled photographers.