


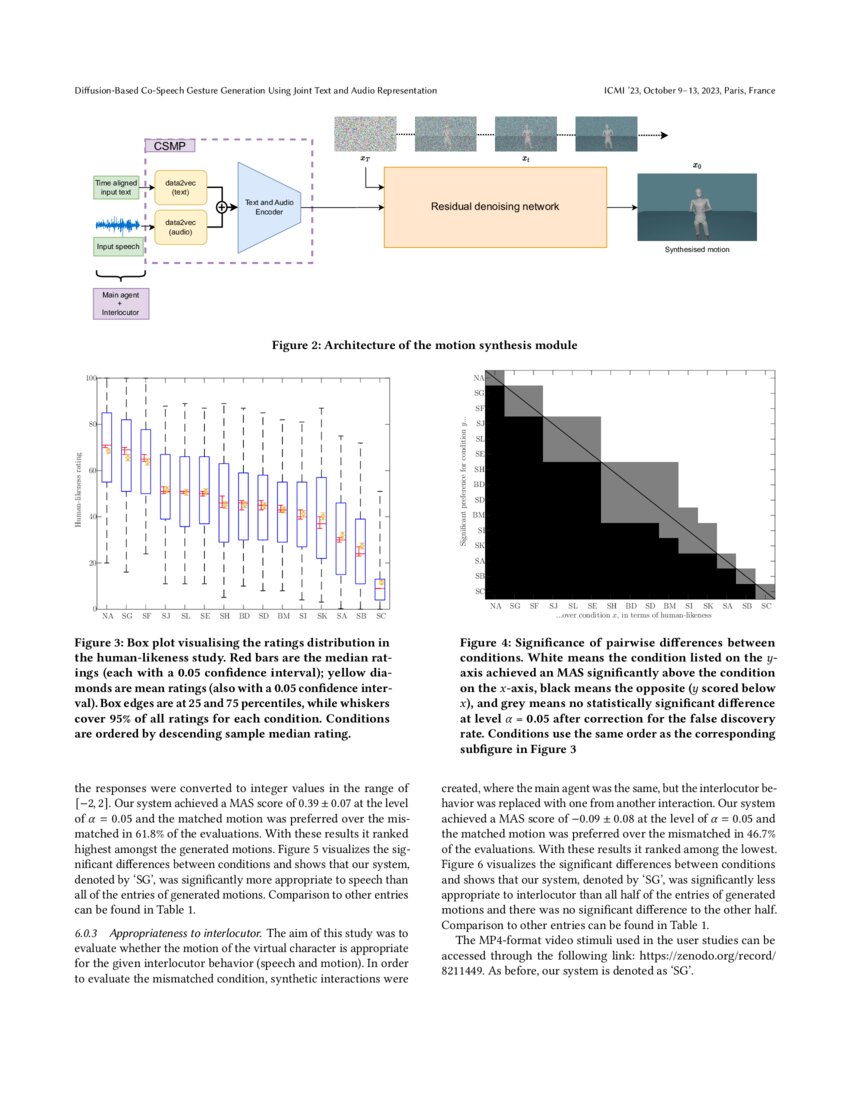



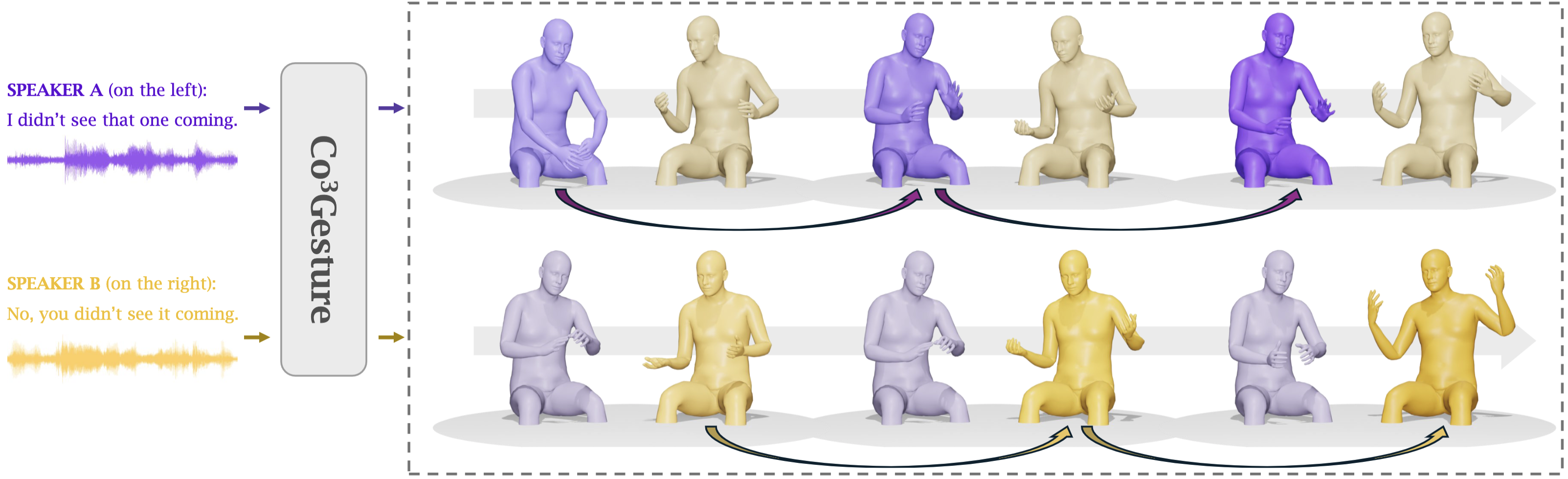
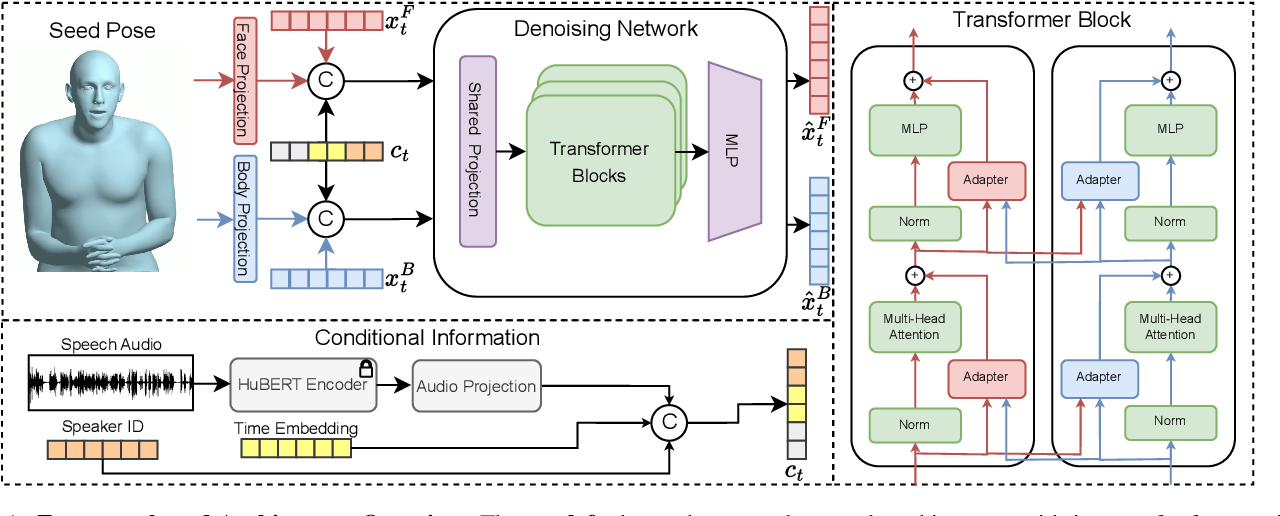














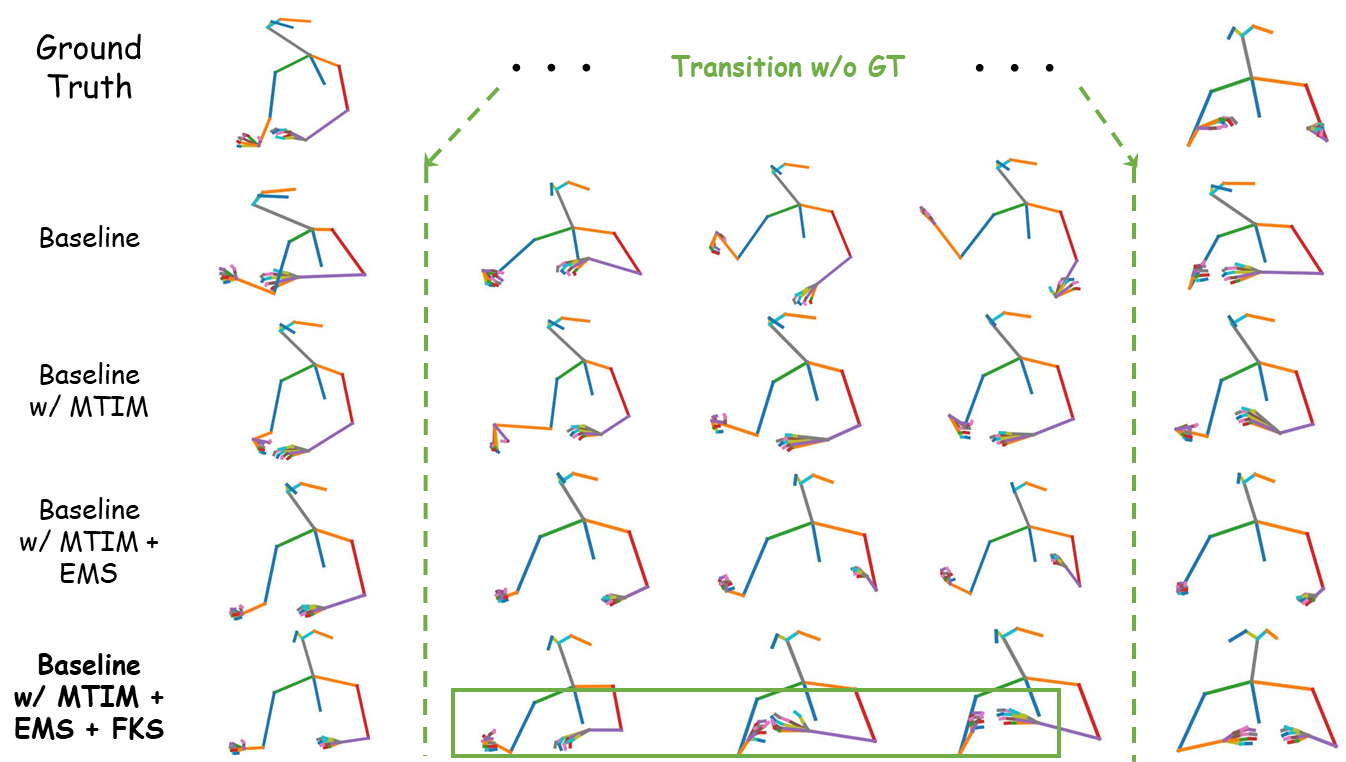
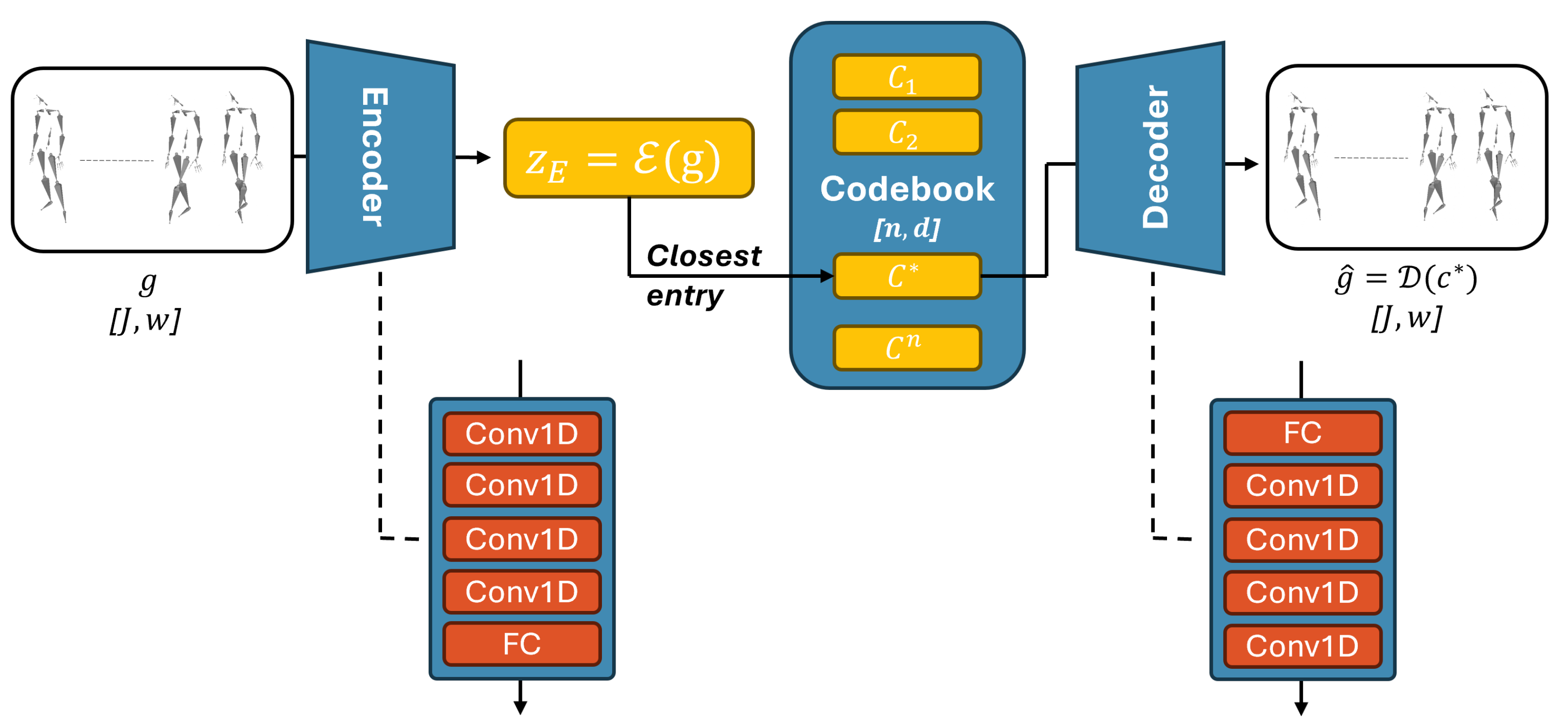
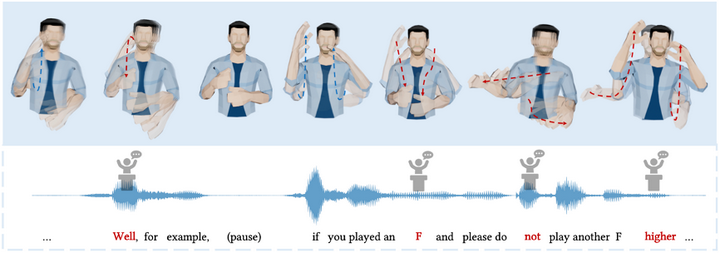
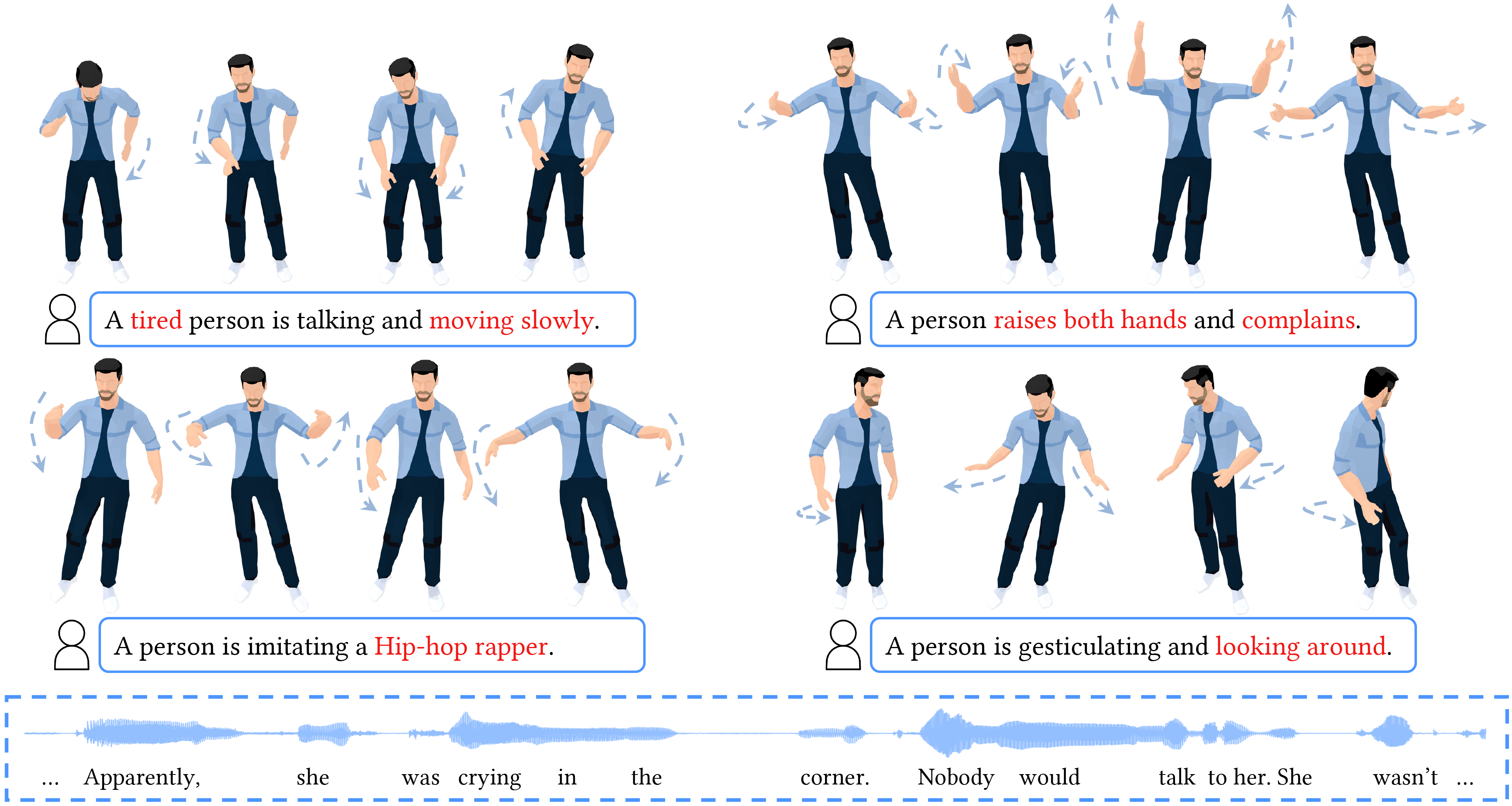
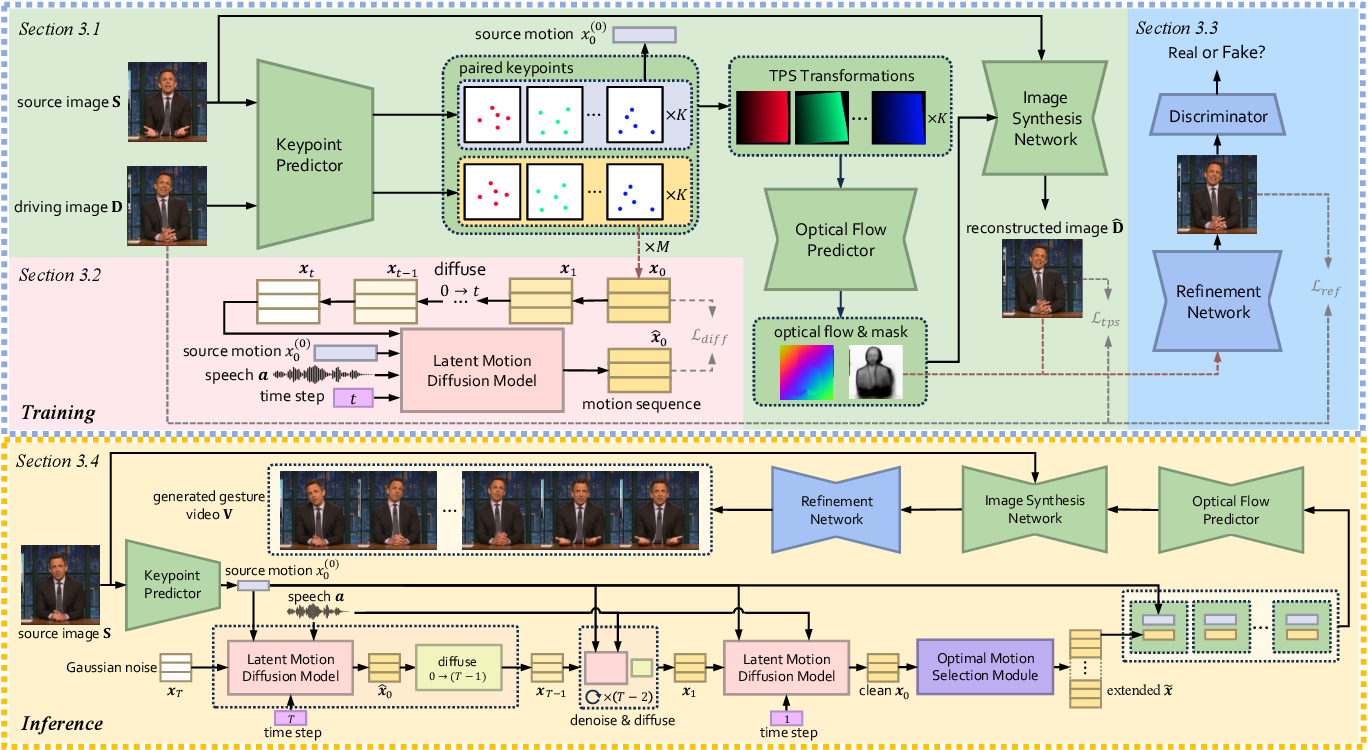
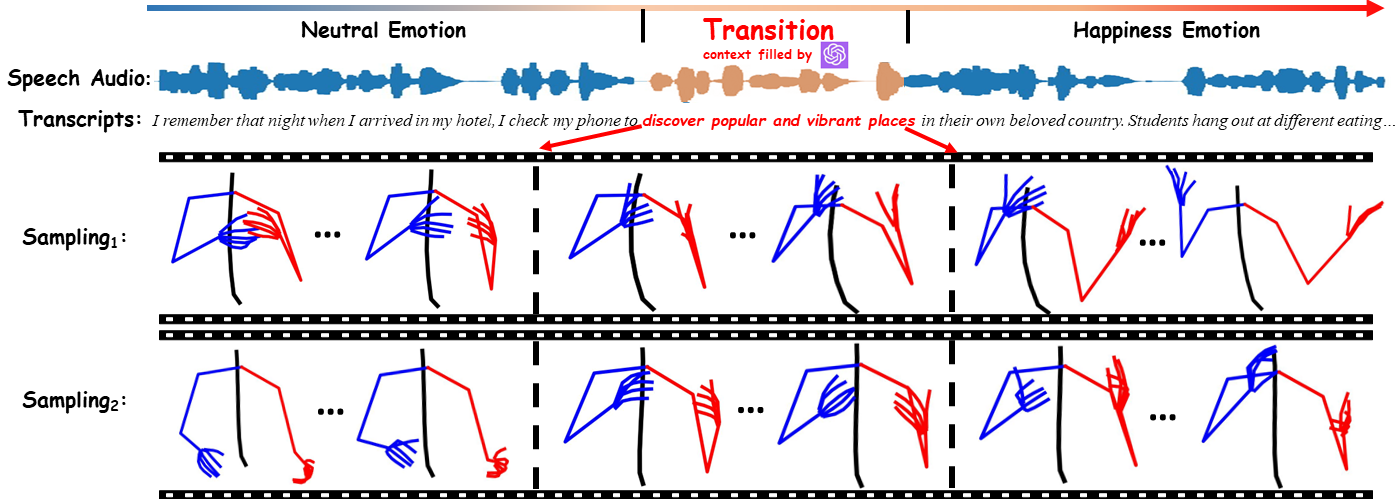
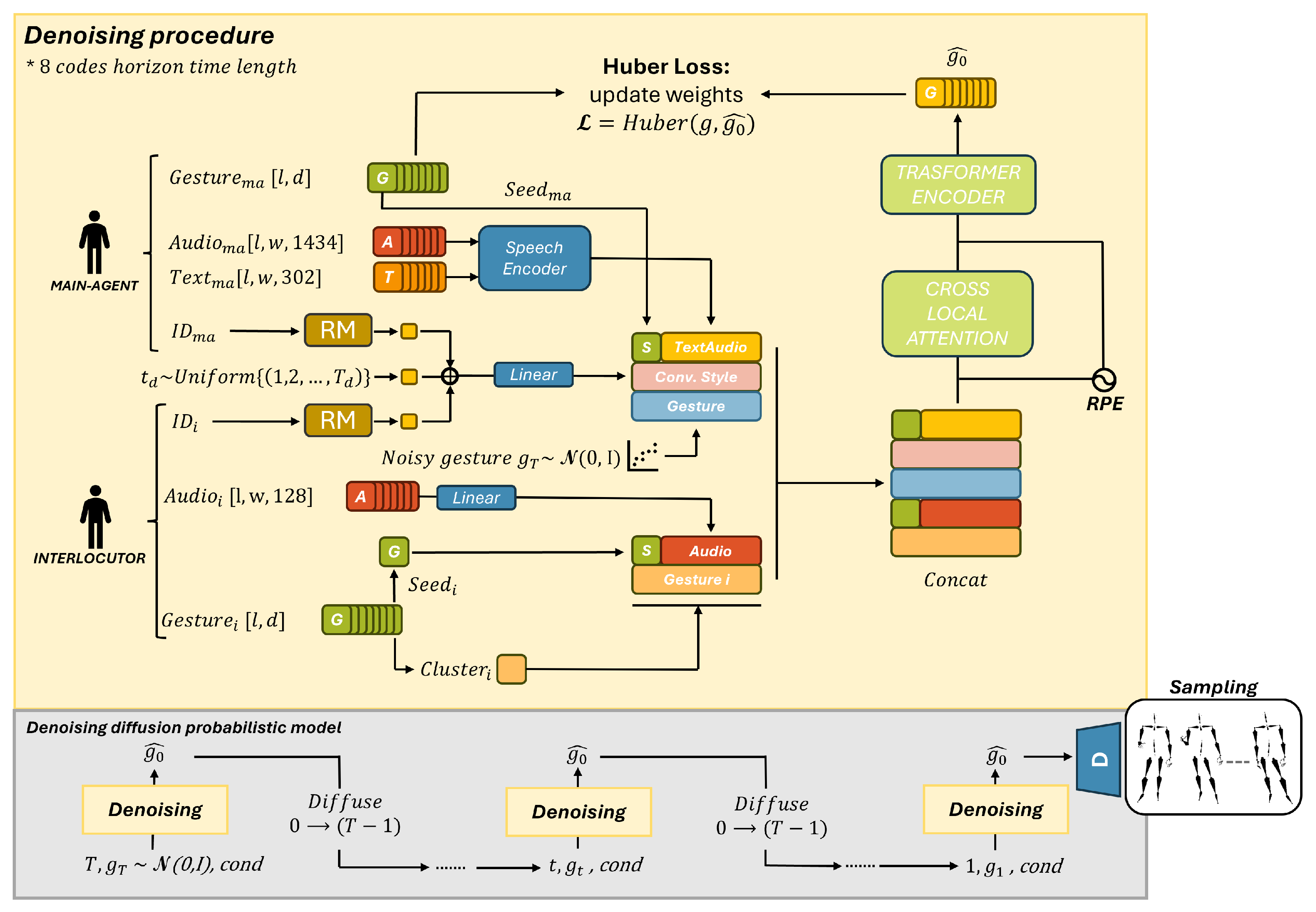
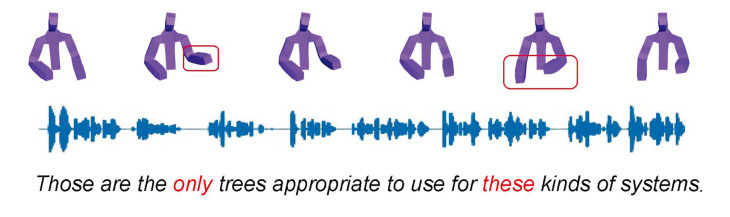
![[2309.05455] Diffusion-Based Co-Speech Gesture Generation Using Joint ...](https://ar5iv.labs.arxiv.org/html/2309.05455/assets/x2.png)












![[2301.10047] DiffMotion: Speech-Driven Gesture Synthesis Using ...](https://ar5iv.labs.arxiv.org/html/2301.10047/assets/x1.png)





![[논문 리뷰] HOP: Heterogeneous Topology-based Multimodal Entanglement for ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/hop-heterogeneous-topology-based-multimodal-entanglement-for-co-speech-gesture-generation-0.png)


![[논문 리뷰] MAG: Multi-Modal Aligned Autoregressive Co-Speech Gesture ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/mag-multi-modal-aligned-autoregressive-co-speech-gesture-generation-without-vector-quantization-0.png)

![[2305.04919] DiffuseStyleGesture: Stylized Audio-Driven Co-Speech ...](https://ar5iv.labs.arxiv.org/html/2305.04919/assets/x2.png)













![[2009.02119] Speech Gesture Generation from the Trimodal Context of ...](https://ar5iv.labs.arxiv.org/html/2009.02119/assets/fig/teaser.png)




![[2305.04919] DiffuseStyleGesture: Stylized Audio-Driven Co-Speech ...](https://ar5iv.labs.arxiv.org/html/2305.04919/assets/x1.png)







![[GENEA'23] Gesture Generation with Diffusion Models Aided by Speech ...](https://i.ytimg.com/vi/7_I8rT7pXWo/maxresdefault.jpg?sqp=-oaymwEmCIAKENAF8quKqQMa8AEB-AH-CIAC0AWKAgwIABABGGUgZShlMA8=&rs=AOn4CLCDS0j4ynpBanwle1KzJDaZuJV1Kg)








![[2309.05455] Diffusion-Based Co-Speech Gesture Generation Using Joint ...](https://ar5iv.labs.arxiv.org/html/2309.05455/assets/x6.png)

Preserve history with our remarkable historical paper page - diffusion-based co-speech gesture generation using joint collection of extensive collections of heritage images. heritage-preserving showcasing photography, images, and pictures. ideal for museums and cultural institutions. Our paper page - diffusion-based co-speech gesture generation using joint collection features high-quality images with excellent detail and clarity. Suitable for various applications including web design, social media, personal projects, and digital content creation All paper page - diffusion-based co-speech gesture generation using joint images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Explore the versatility of our paper page - diffusion-based co-speech gesture generation using joint collection for various creative and professional projects. Instant download capabilities enable immediate access to chosen paper page - diffusion-based co-speech gesture generation using joint images. Reliable customer support ensures smooth experience throughout the paper page - diffusion-based co-speech gesture generation using joint selection process. Professional licensing options accommodate both commercial and educational usage requirements. Each image in our paper page - diffusion-based co-speech gesture generation using joint gallery undergoes rigorous quality assessment before inclusion. Whether for commercial projects or personal use, our paper page - diffusion-based co-speech gesture generation using joint collection delivers consistent excellence.