



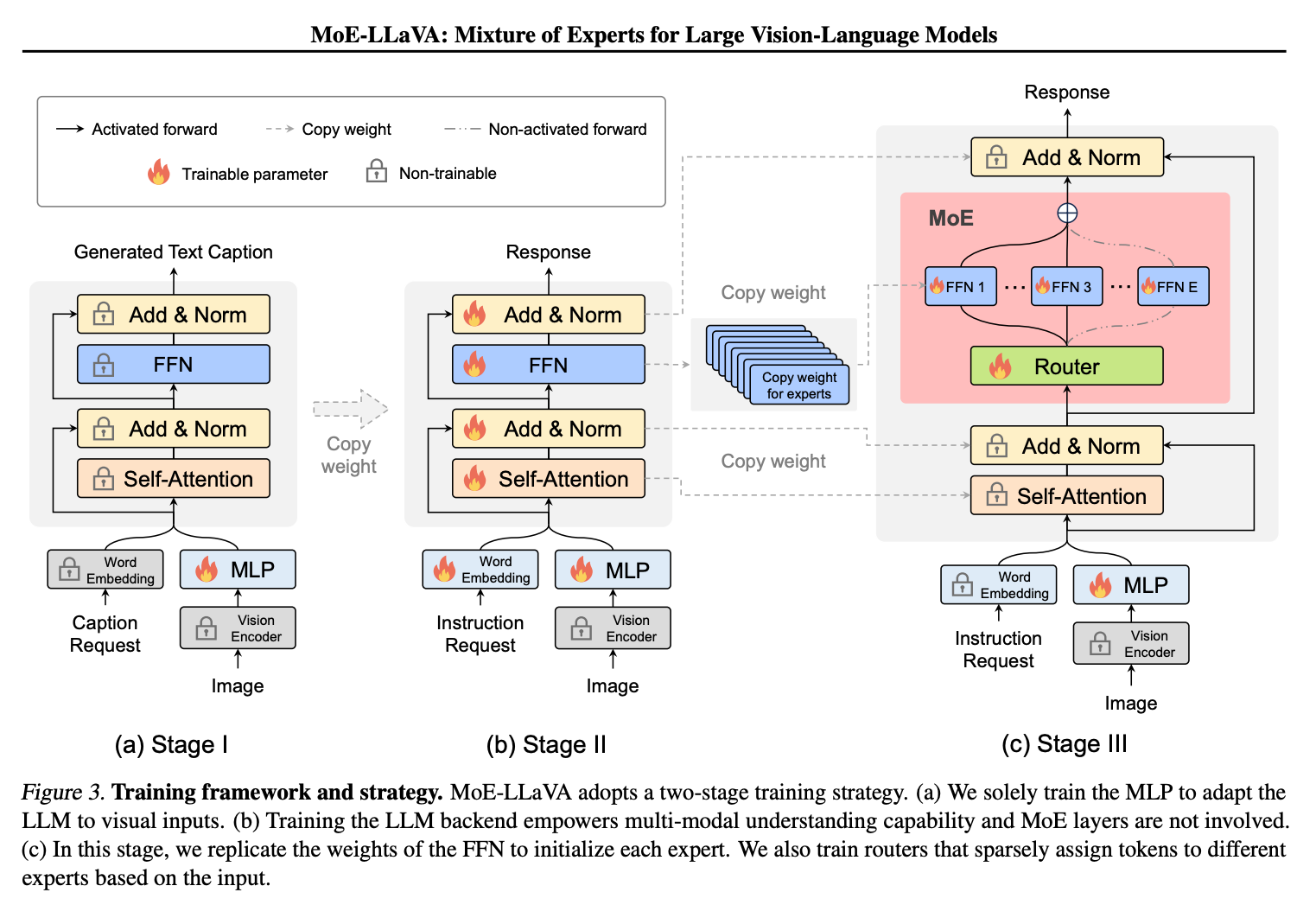












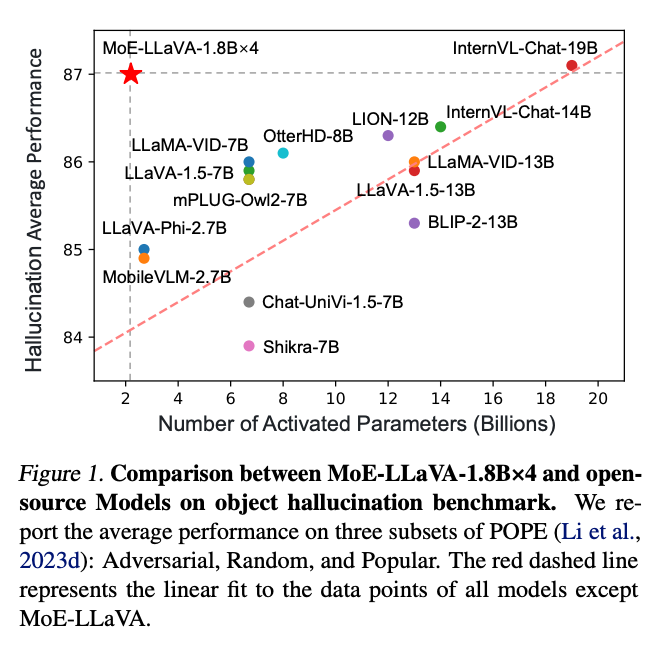

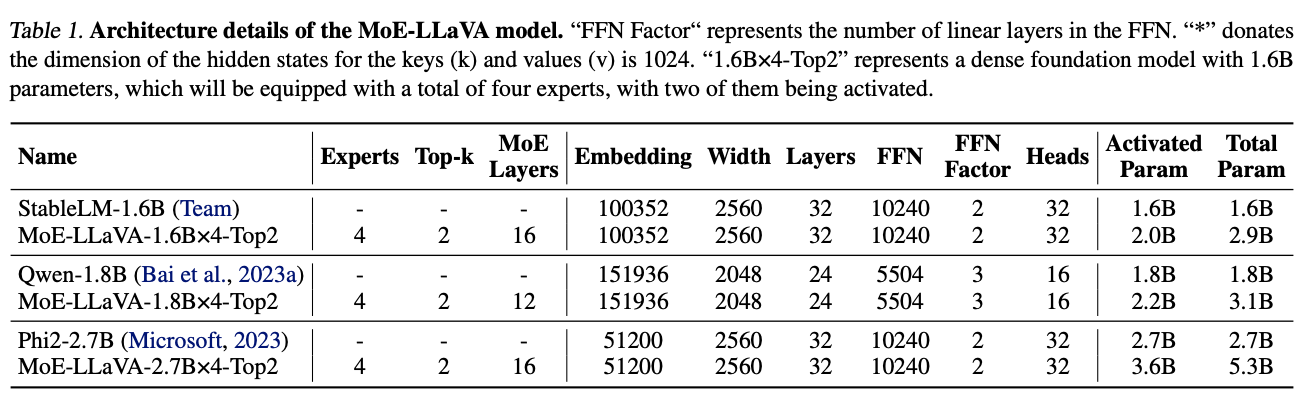





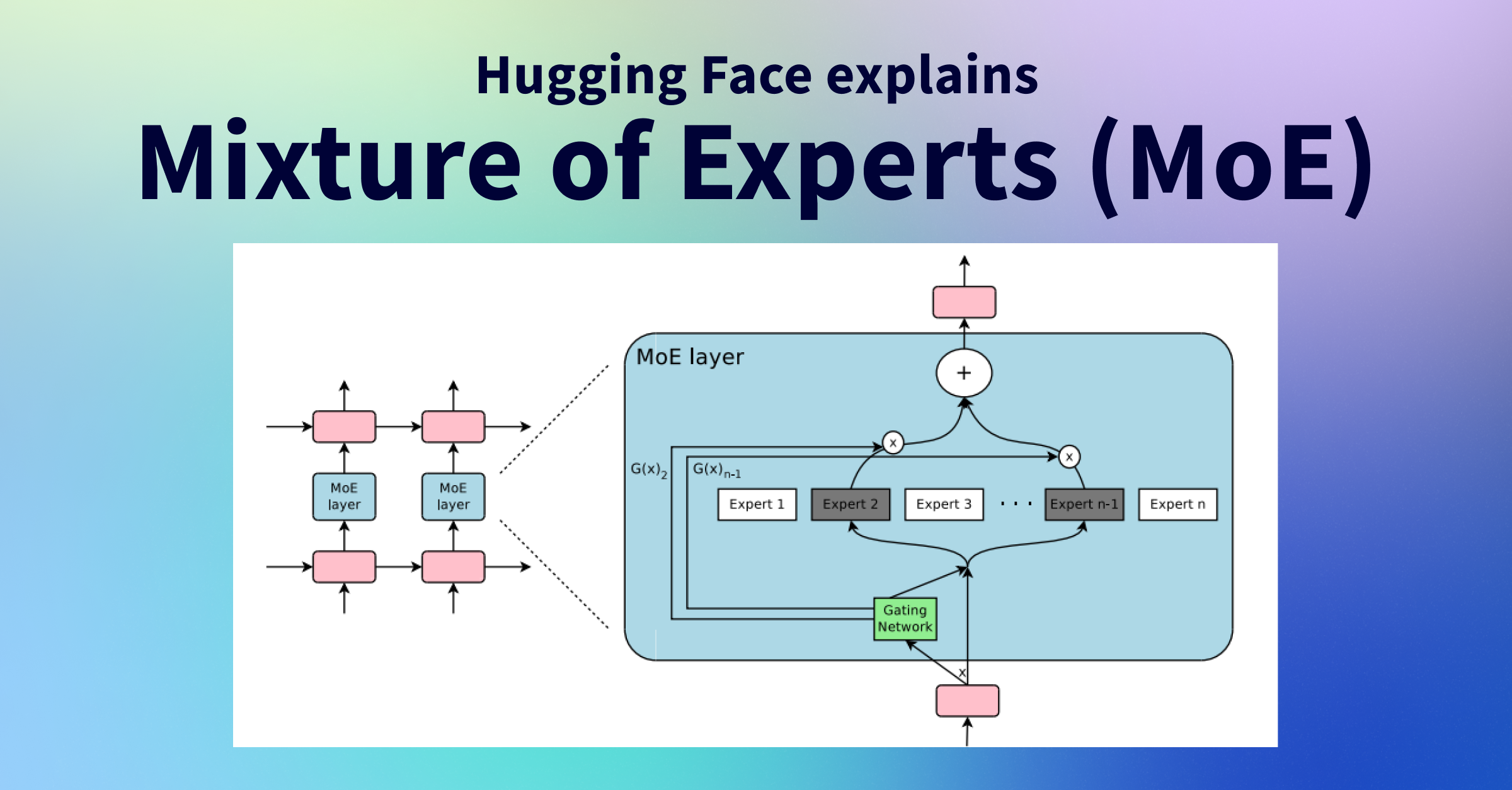















![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/6dd32ba0-3ff8-43f6-b9da-8f006d2a21f9/image.png)

![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/1fadc7d6-91db-42a7-89cb-6acd4c5a9746/image.png)








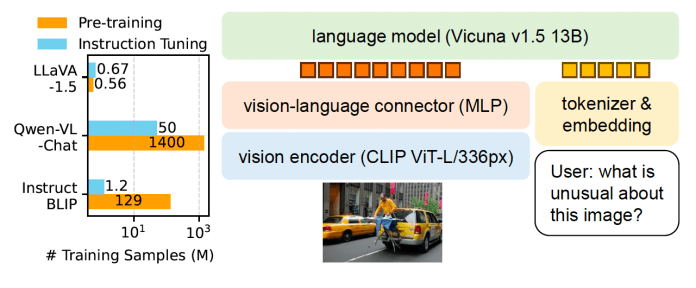
![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/8111c54f-e83f-4249-96db-de762e988f39/image.png)




![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/bc81a43f-f08c-4d3d-b1ad-06245c993051/image.png)

![[Paper Review] LLaVA: Large Language and Vision Assistant (Visual ...](https://i.ytimg.com/vi/n58UZziEieo/maxresdefault.jpg)





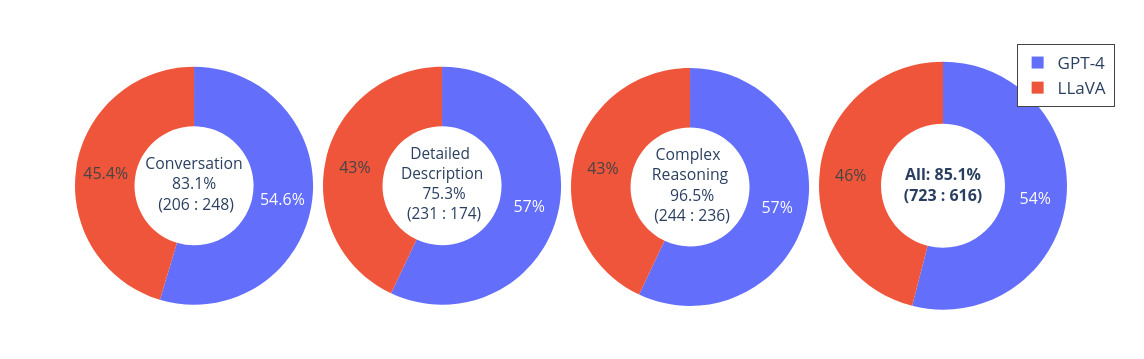






![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/92a88551-9a18-4a58-95b2-f6a073bdbd4a/image.png)



![[논문 리뷰] Med-MoE: Mixture of Domain-Specific Experts for Lightweight ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/med-moe-mixture-of-domain-specific-experts-for-lightweight-medical-vision-language-models-1.png)
![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/d28d288d-a6c2-4efb-9cfe-195055c12d15/image.png)



![[论文审查] CL-MoE: Enhancing Multimodal Large Language Model with Dual ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/cl-moe-enhancing-multimodal-large-language-model-with-dual-momentum-mixture-of-experts-for-continual-visual-question-answering-0.png)





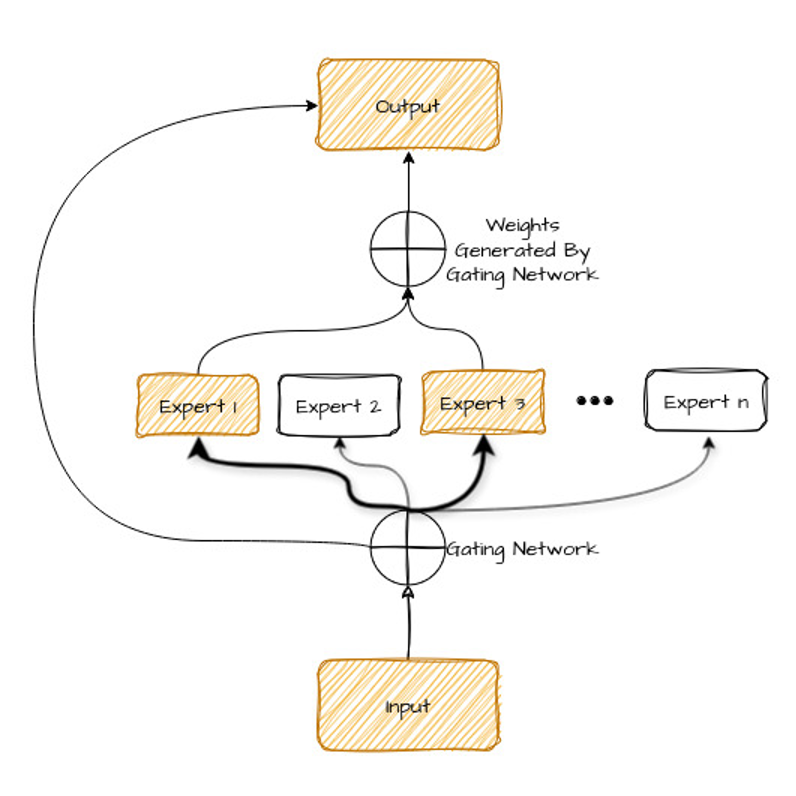
![[Paper Review] LLaVA: Large Language and Vision Assistant, Visual ...](https://velog.velcdn.com/images/harms/post/345fc5f3-de64-4ed7-b7d8-c93ca3e8bdfc/image.png)


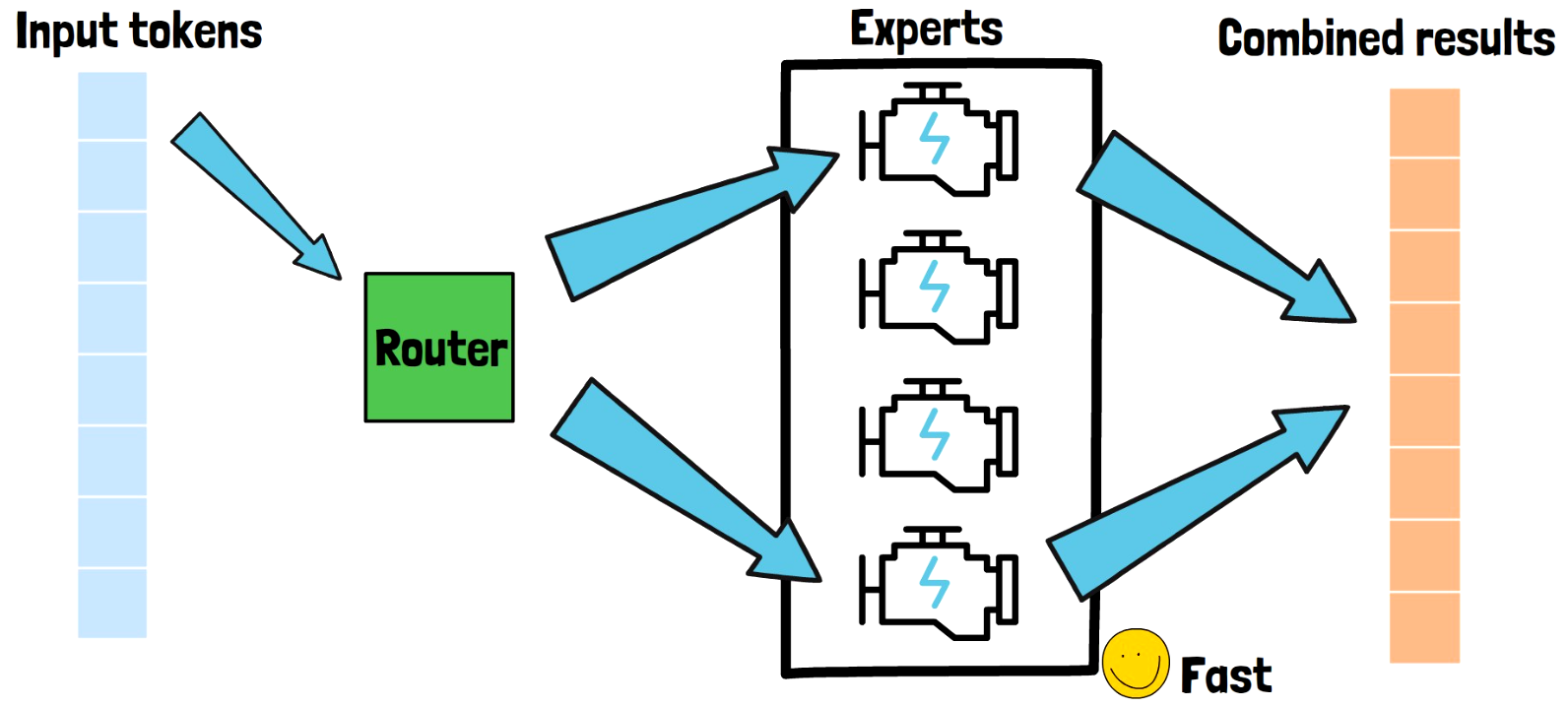











Embrace the remarkable lifestyle with our paper page - moe-llava: mixture of experts for large vision-language models collection of countless inspiring images. inspiring lifestyle choices through photography, images, and pictures. designed to inspire positive life choices. The paper page - moe-llava: mixture of experts for large vision-language models collection maintains consistent quality standards across all images. Suitable for various applications including web design, social media, personal projects, and digital content creation All paper page - moe-llava: mixture of experts for large vision-language models images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Explore the versatility of our paper page - moe-llava: mixture of experts for large vision-language models collection for various creative and professional projects. Cost-effective licensing makes professional paper page - moe-llava: mixture of experts for large vision-language models photography accessible to all budgets. Professional licensing options accommodate both commercial and educational usage requirements. Regular updates keep the paper page - moe-llava: mixture of experts for large vision-language models collection current with contemporary trends and styles. Each image in our paper page - moe-llava: mixture of experts for large vision-language models gallery undergoes rigorous quality assessment before inclusion.