


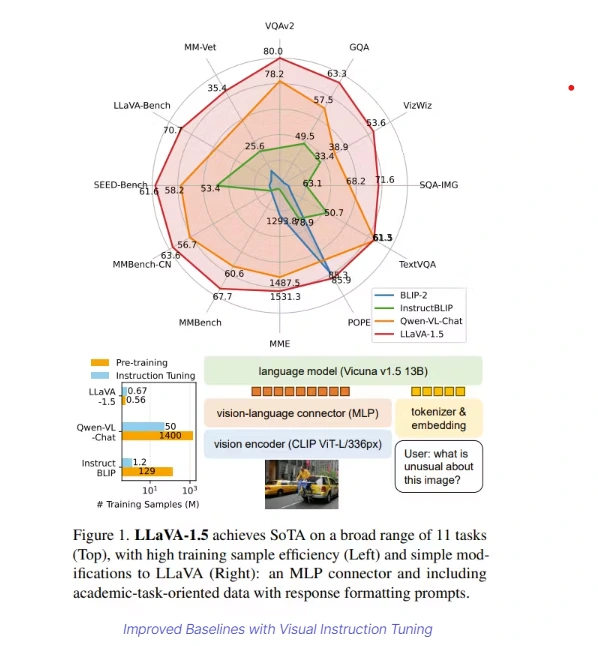
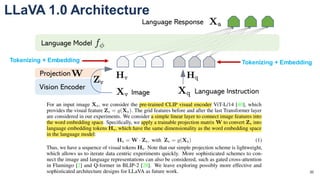

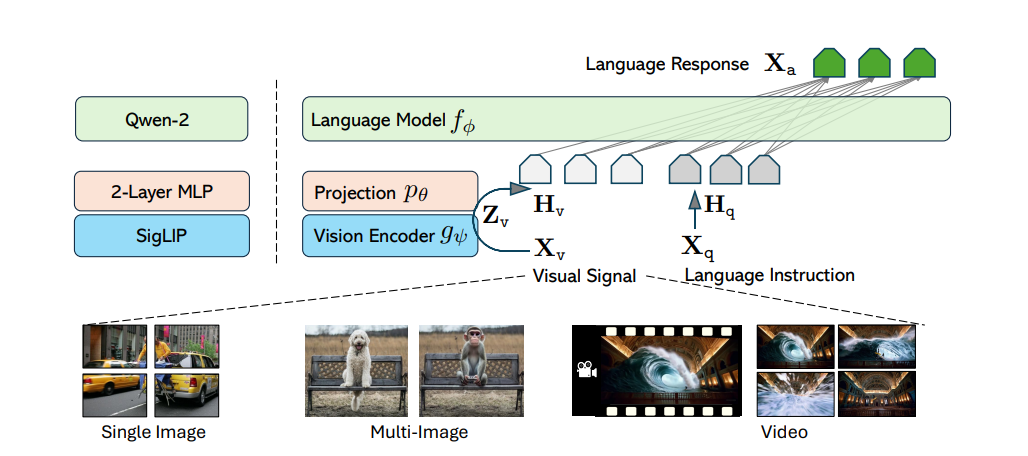
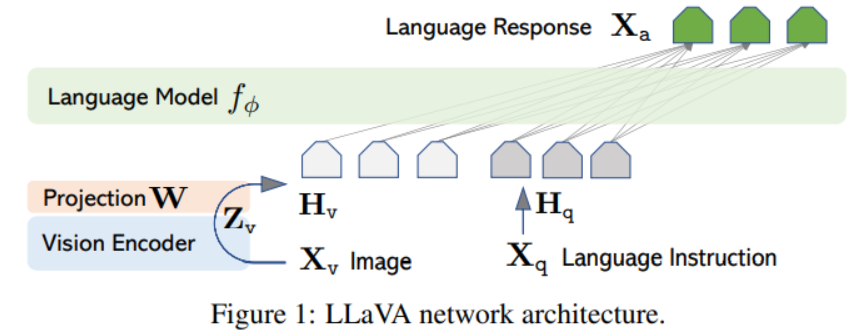
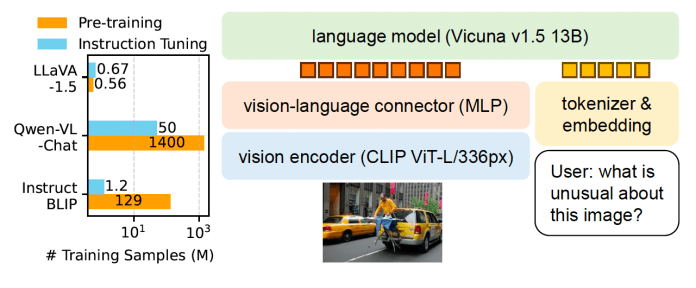

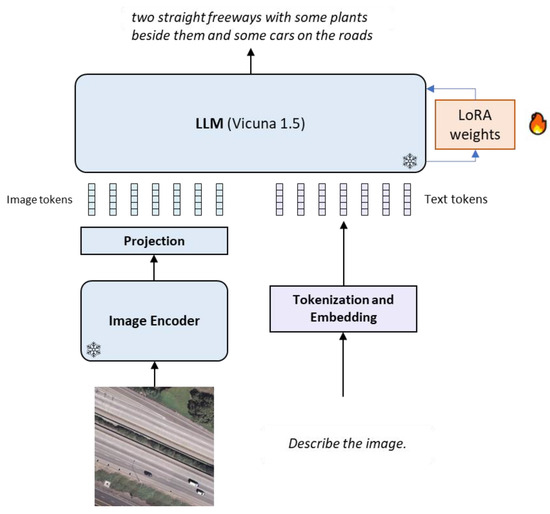

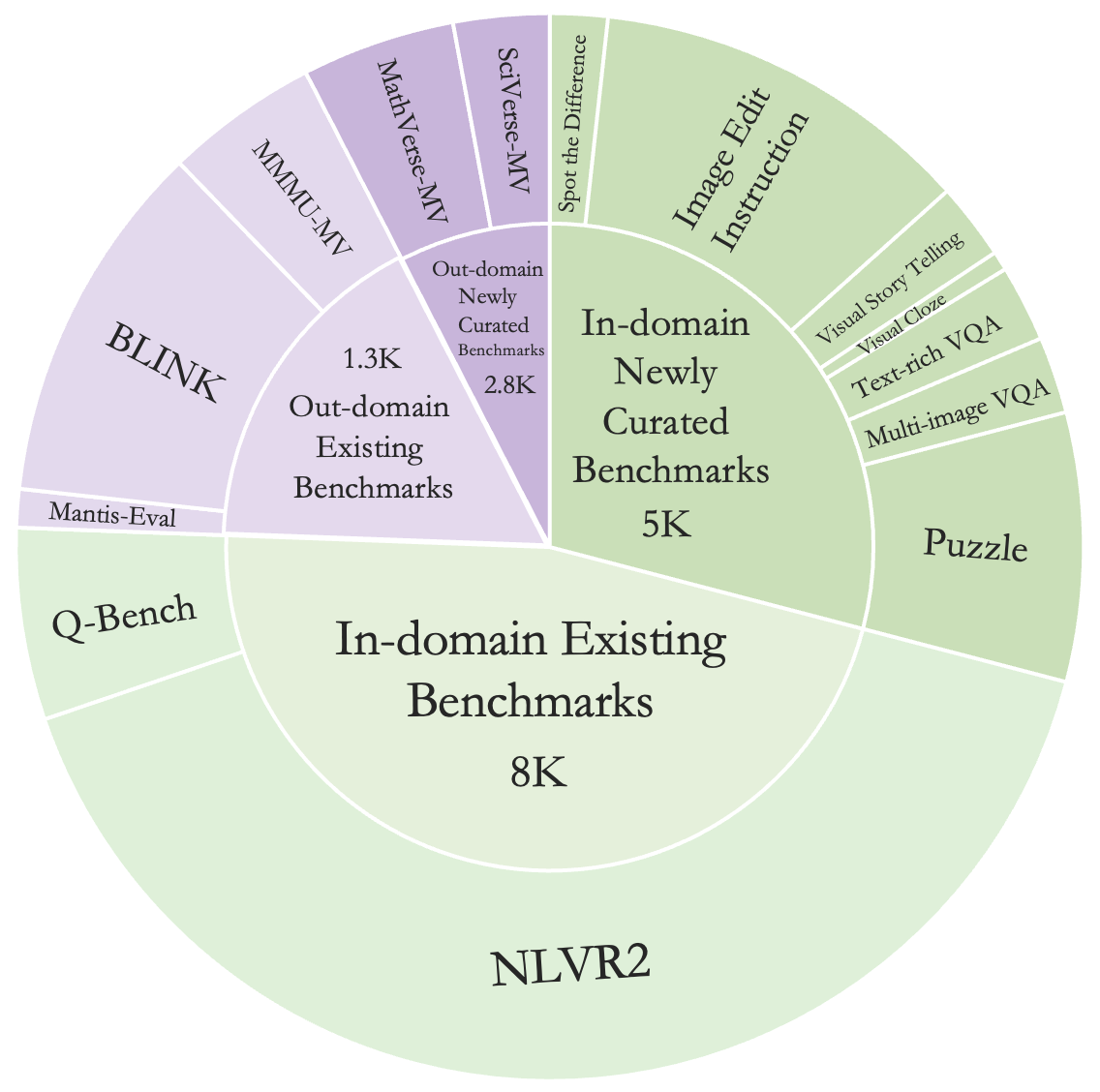
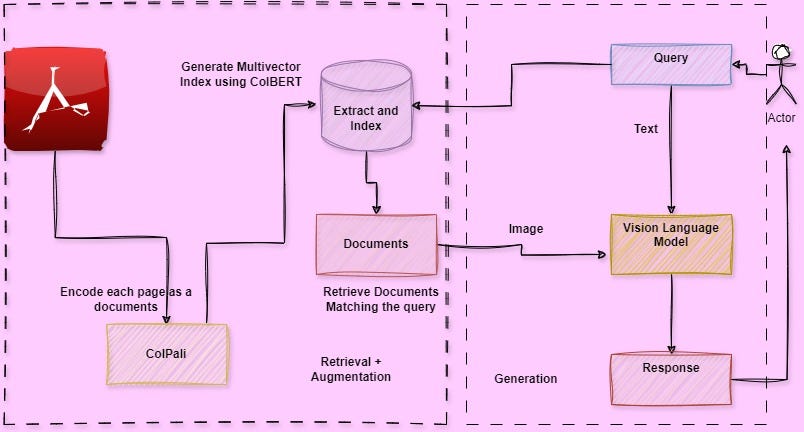
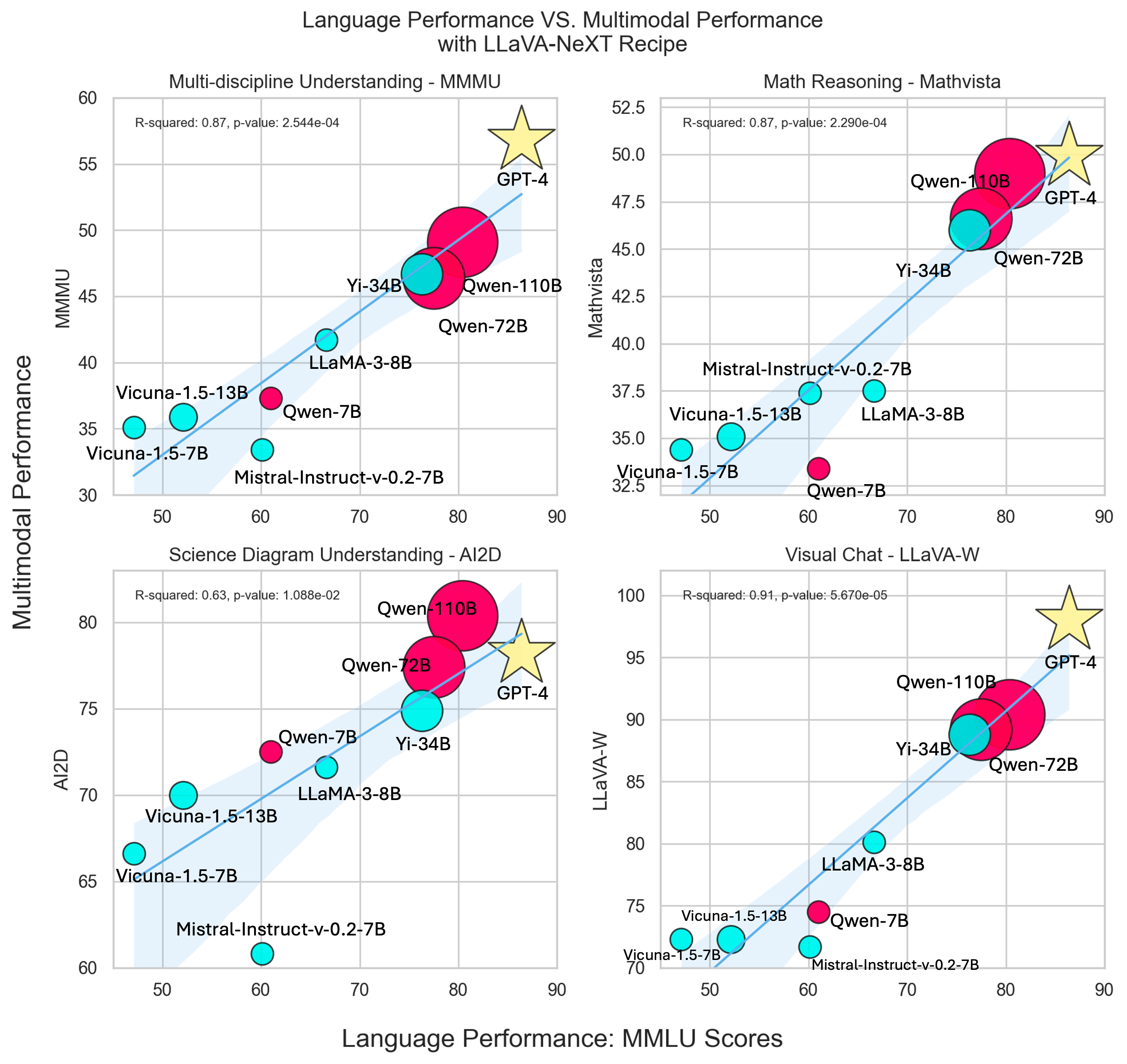
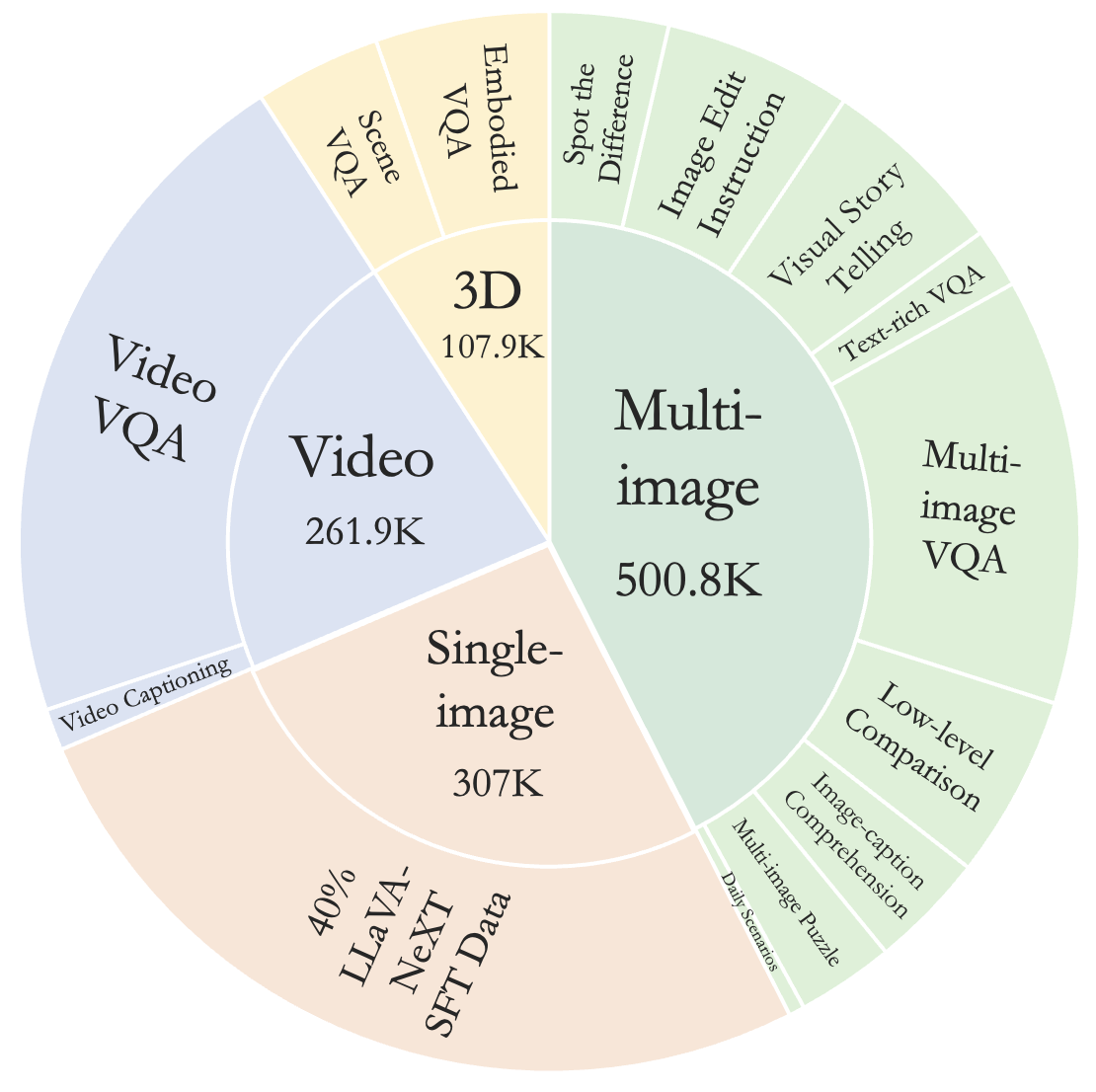
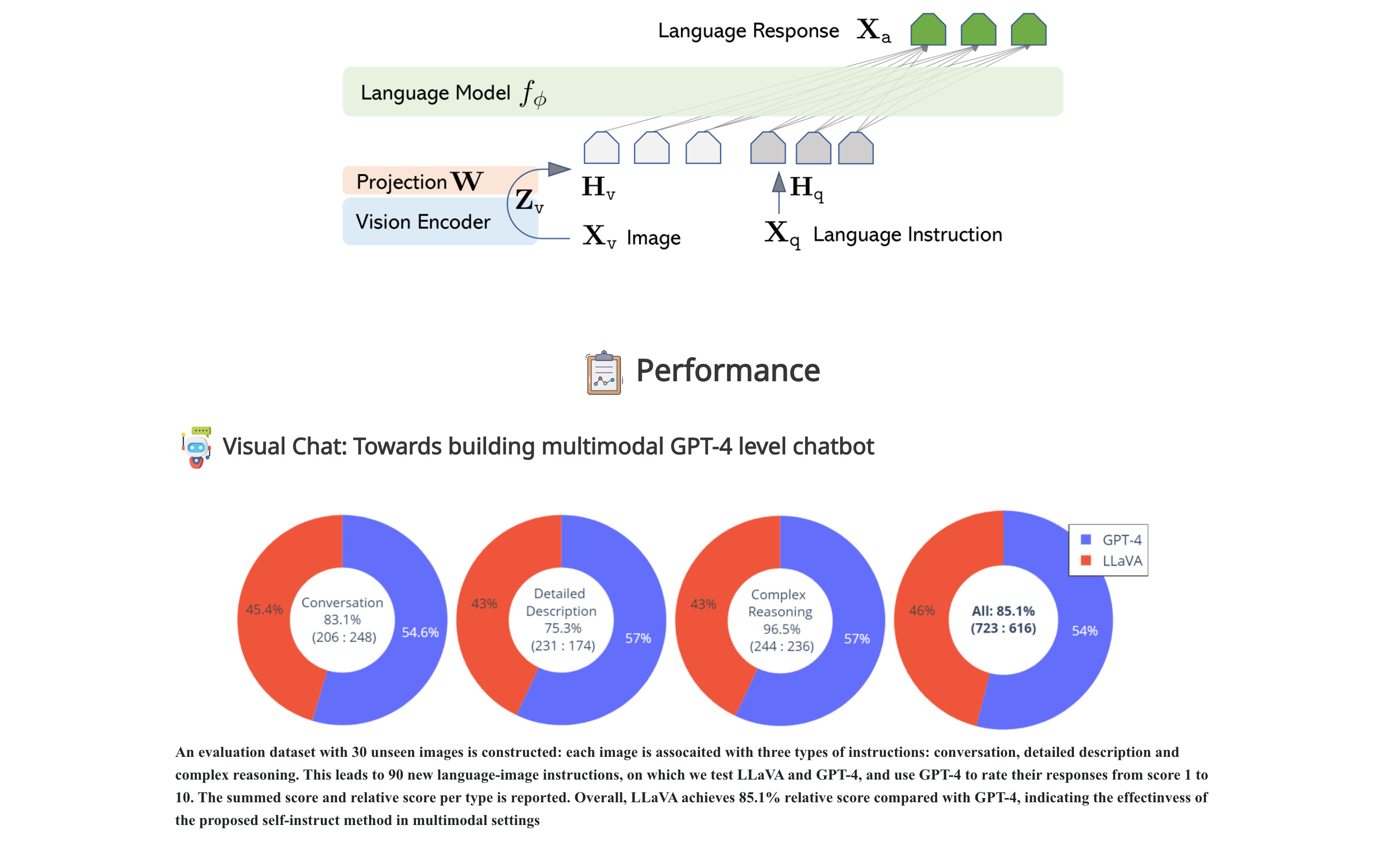
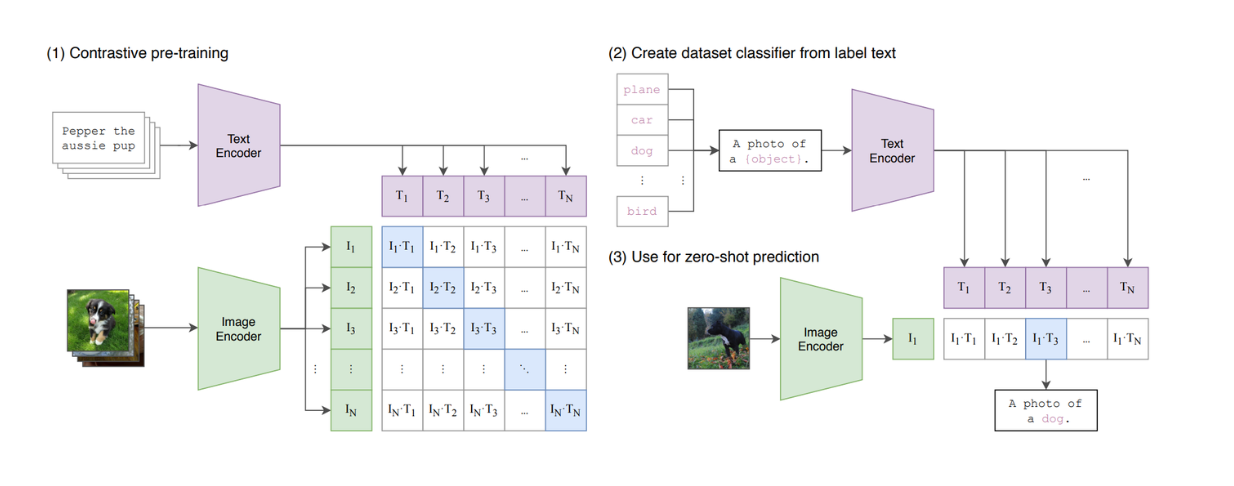
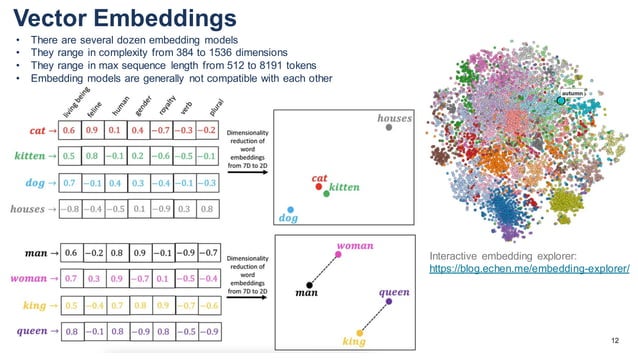
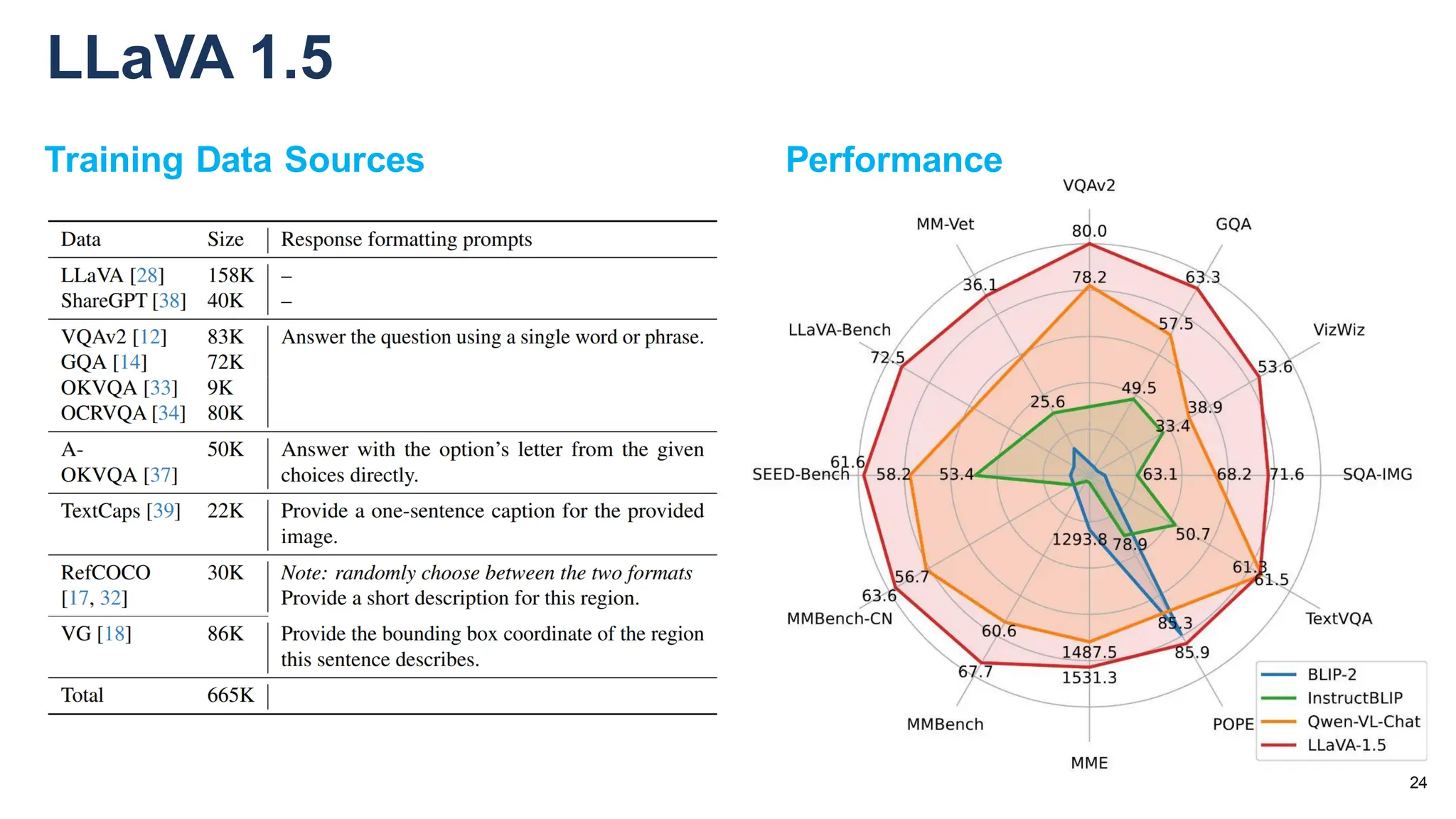
![[LLaVA系列]📒CLIP/LLaVA/LLaVA1.5/VILA笔记: 核心点解析 - 知乎](https://pic3.zhimg.com/v2-795365d3be59787f08b170cf97fd0b3e_1440w.jpg)








![[논문 리뷰] WSI-LLaVA: A Multimodal Large Language Model for Whole Slide Image](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/wsi-llava-a-multimodal-large-language-model-for-whole-slide-image-2.png)



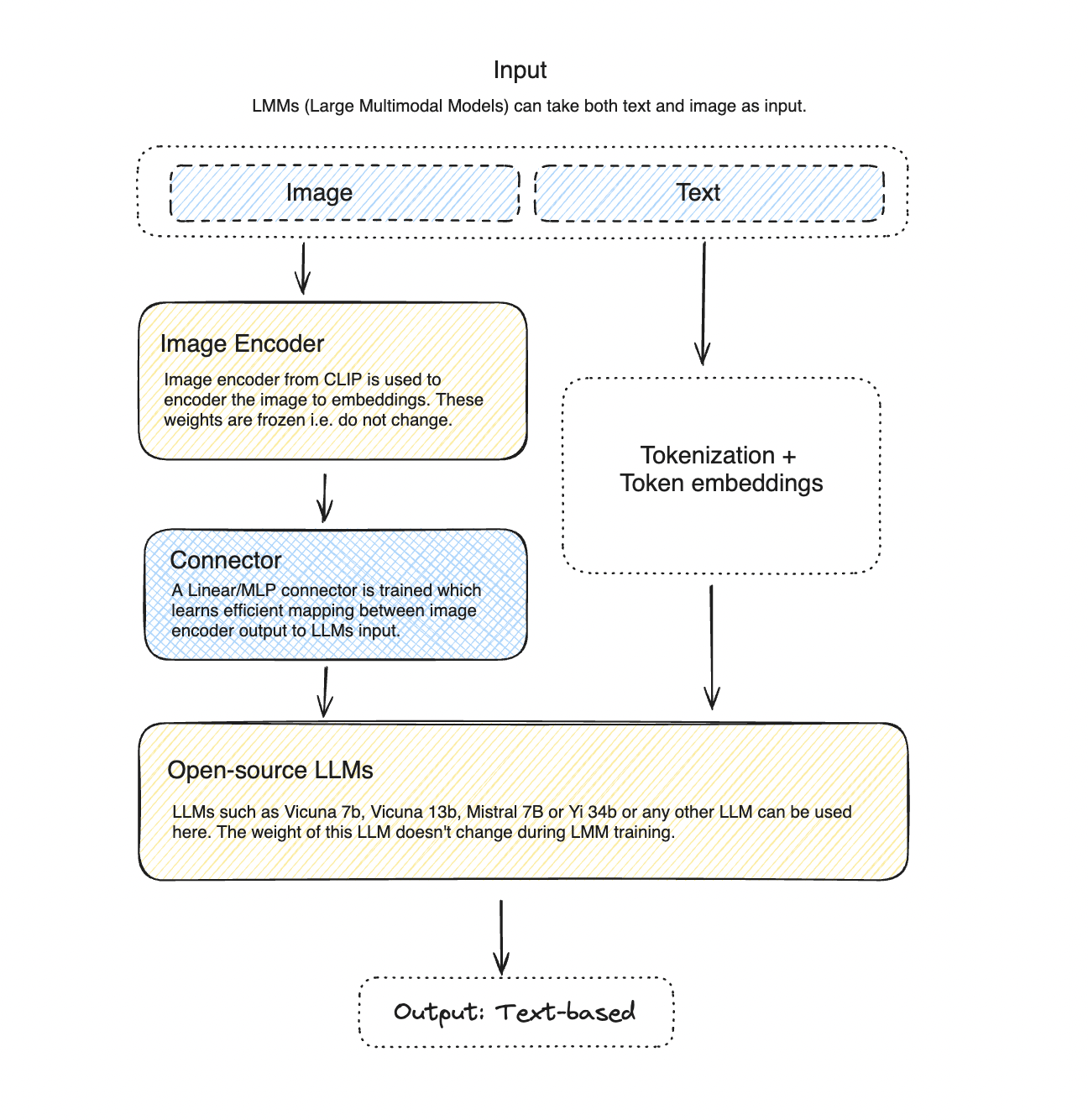
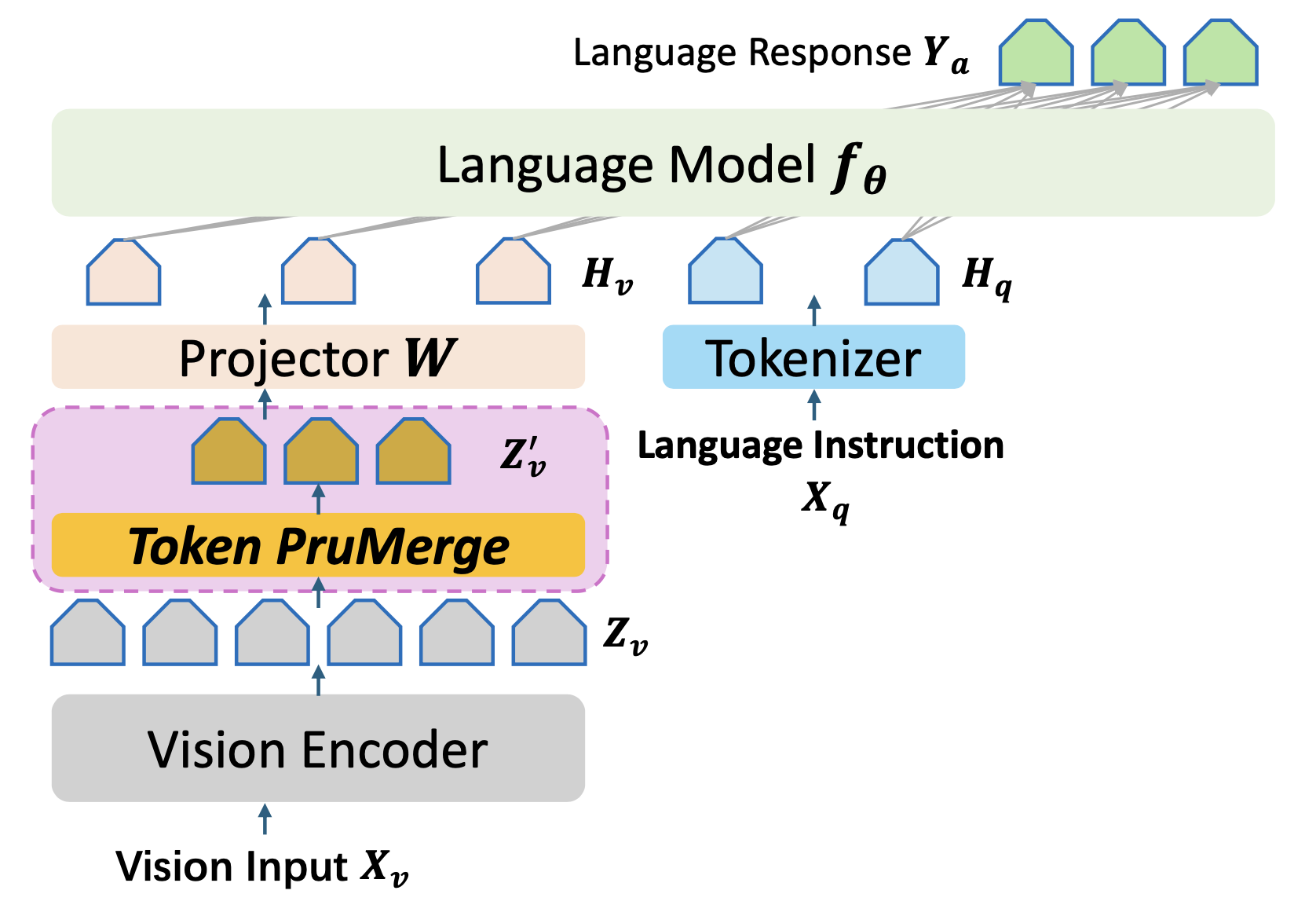
![[논문 리뷰] LLaVA-Mini: Efficient Image and Video Large Multimodal Models ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/llava-mini-efficient-image-and-video-large-multimodal-models-with-one-vision-token-1.png)
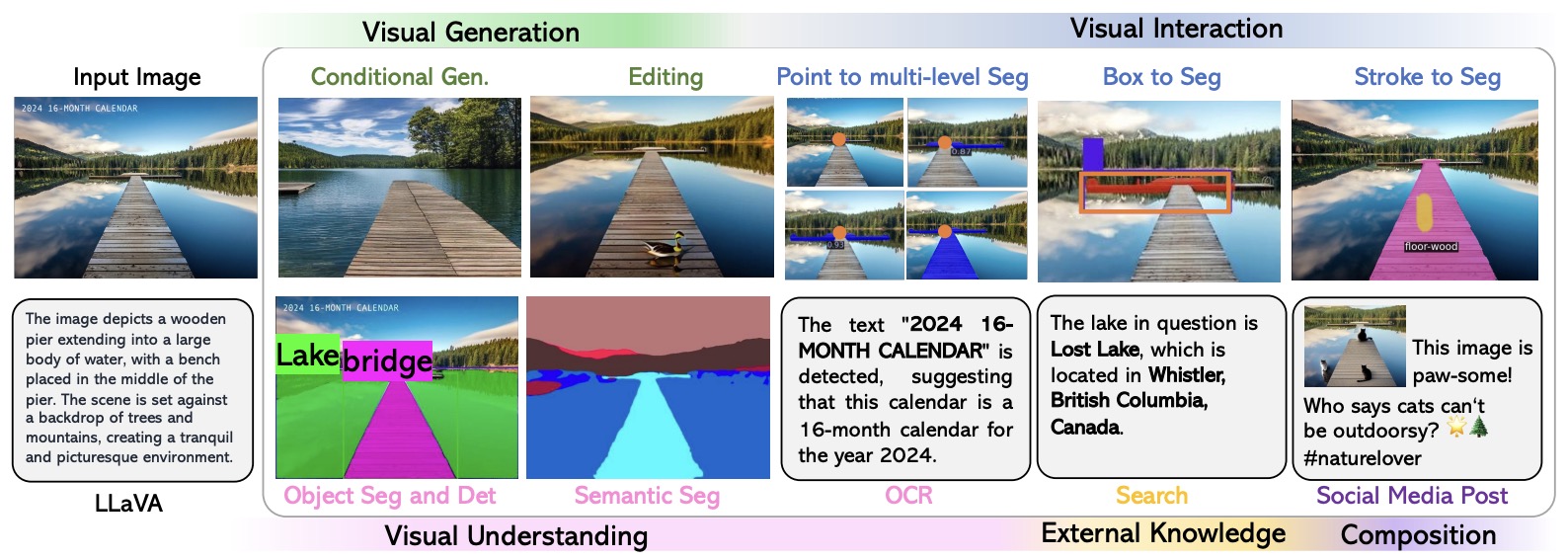
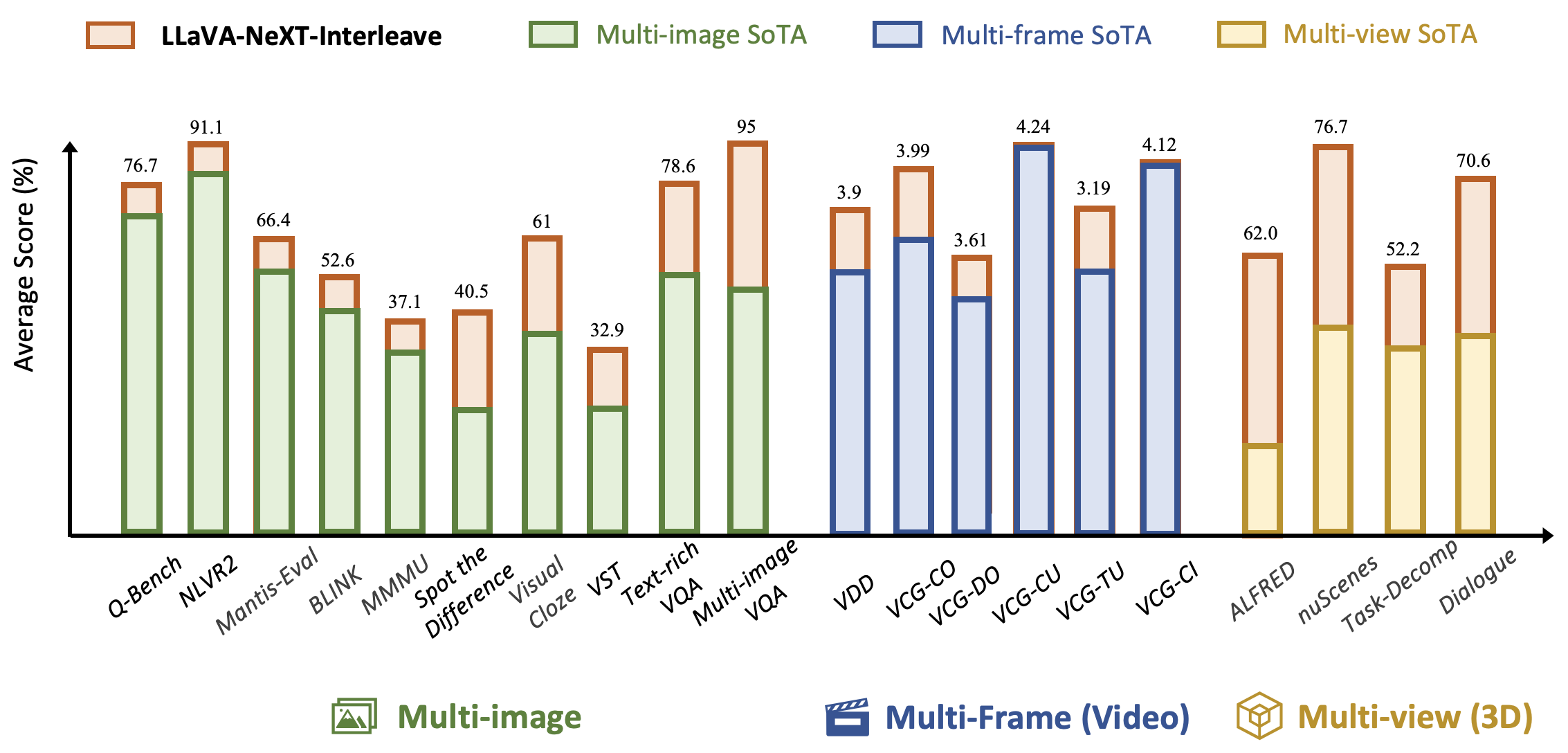
![[논문 리뷰] LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/llava-next-interleave-tackling-multi-image-video-and-3d-in-large-multimodal-models-0.png)










![[2410.02712] LLaVA-Critic: Learning to Evaluate Multimodal Models](https://ar5iv.labs.arxiv.org/html/2410.02712/assets/x2.png)

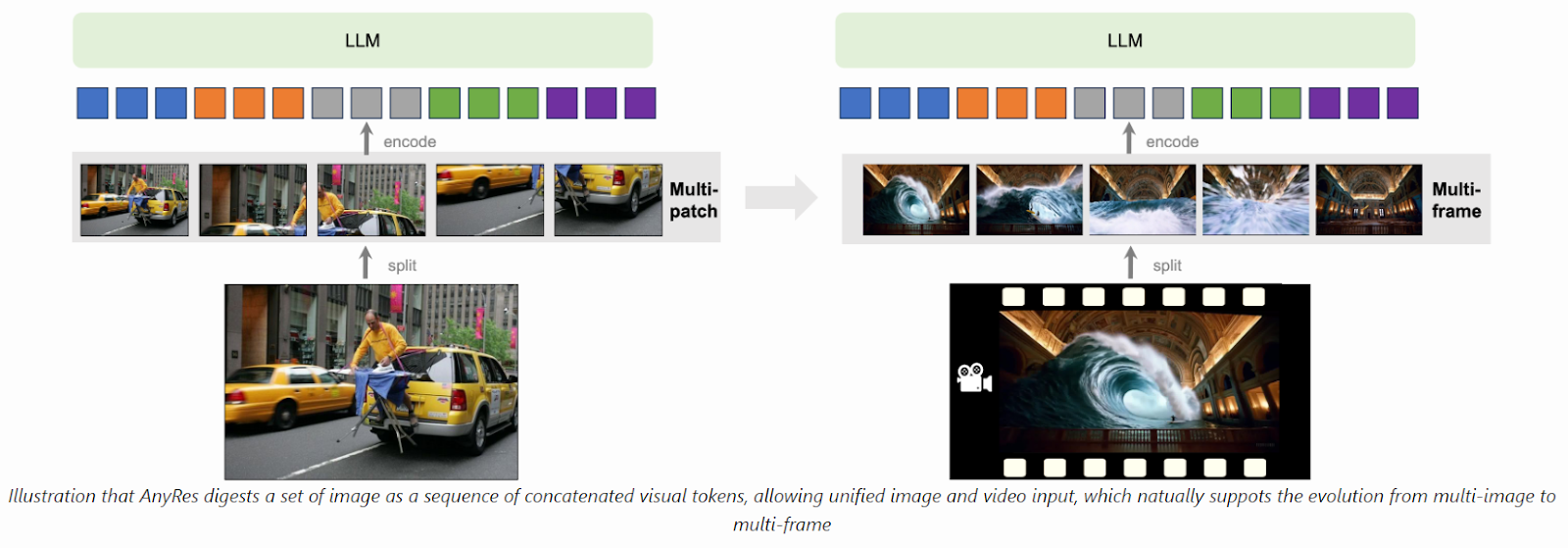
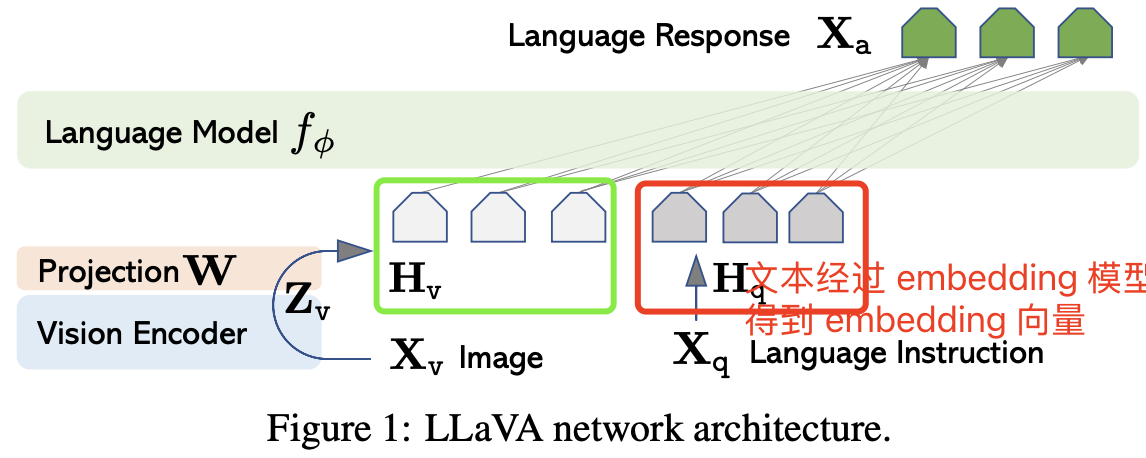
![[논문 리뷰] LLaVA-ST: A Multimodal Large Language Model for Fine-Grained ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/llava-st-a-multimodal-large-language-model-for-fine-grained-spatial-temporal-understanding-0.png)








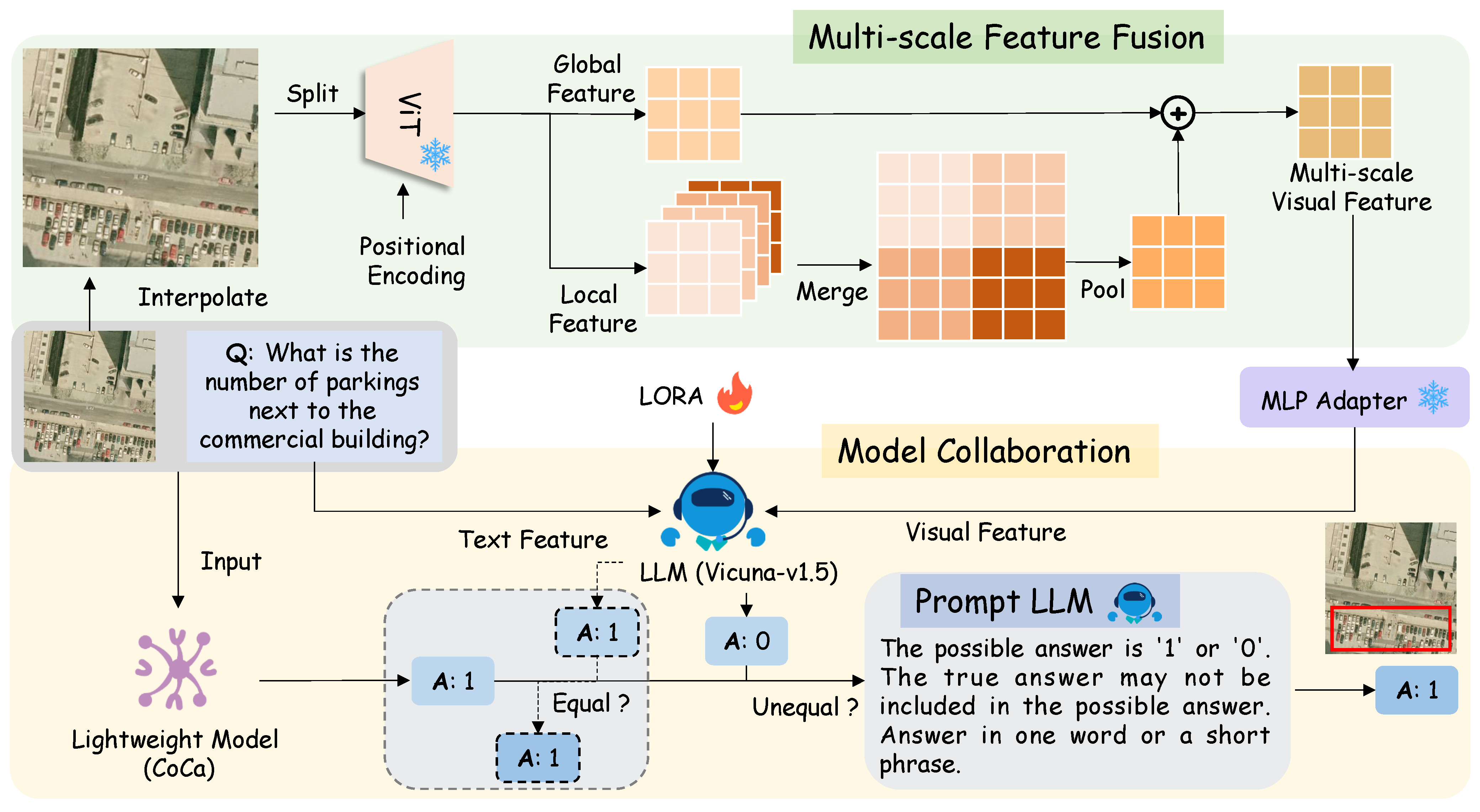
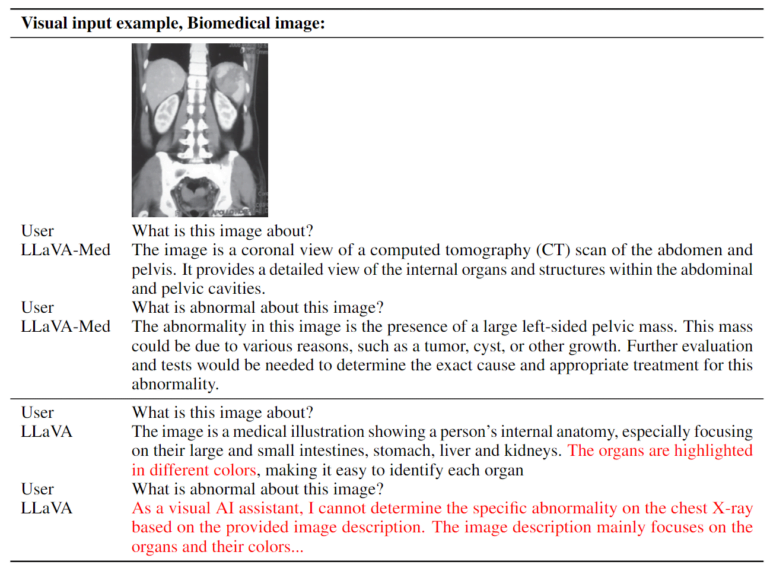




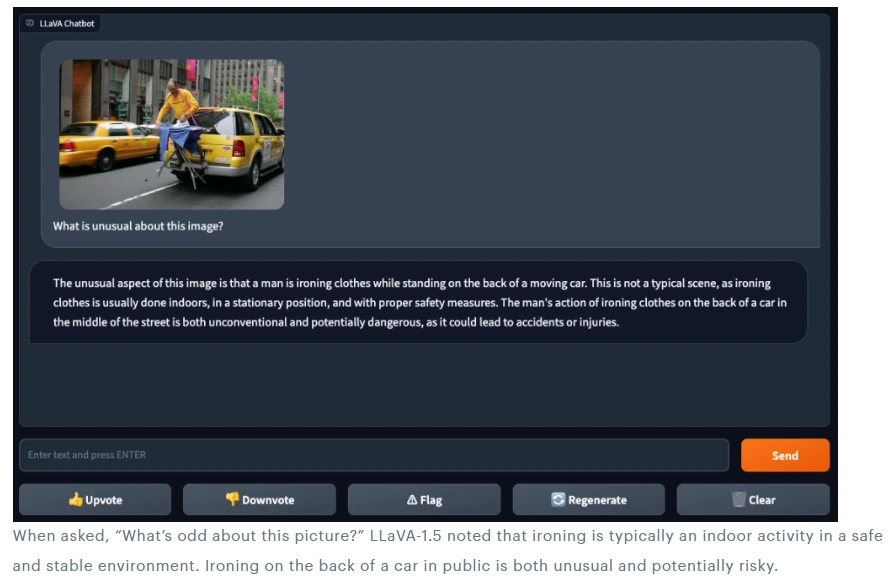

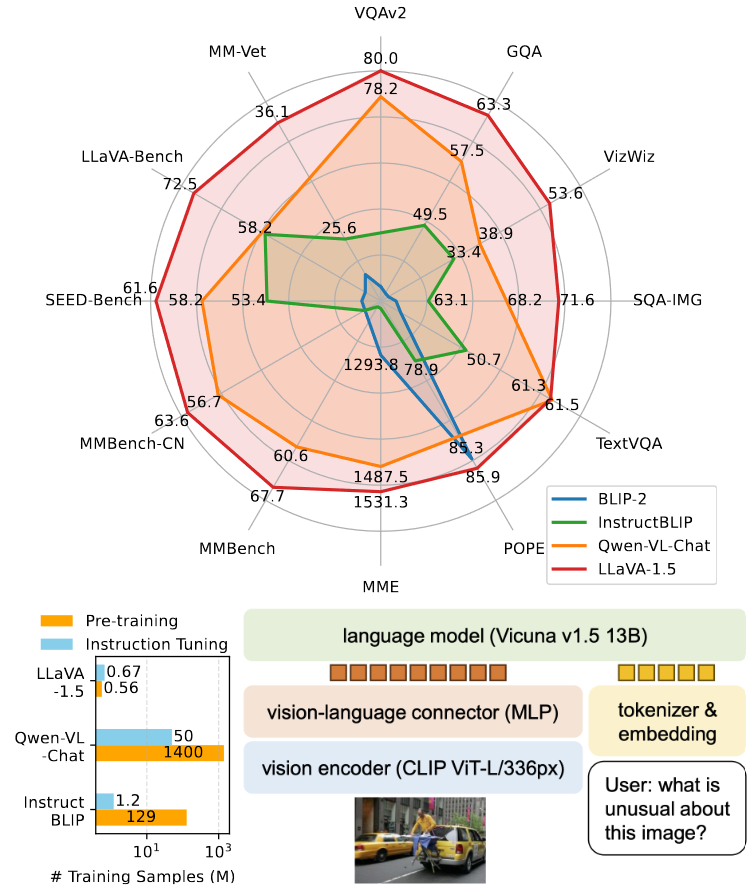
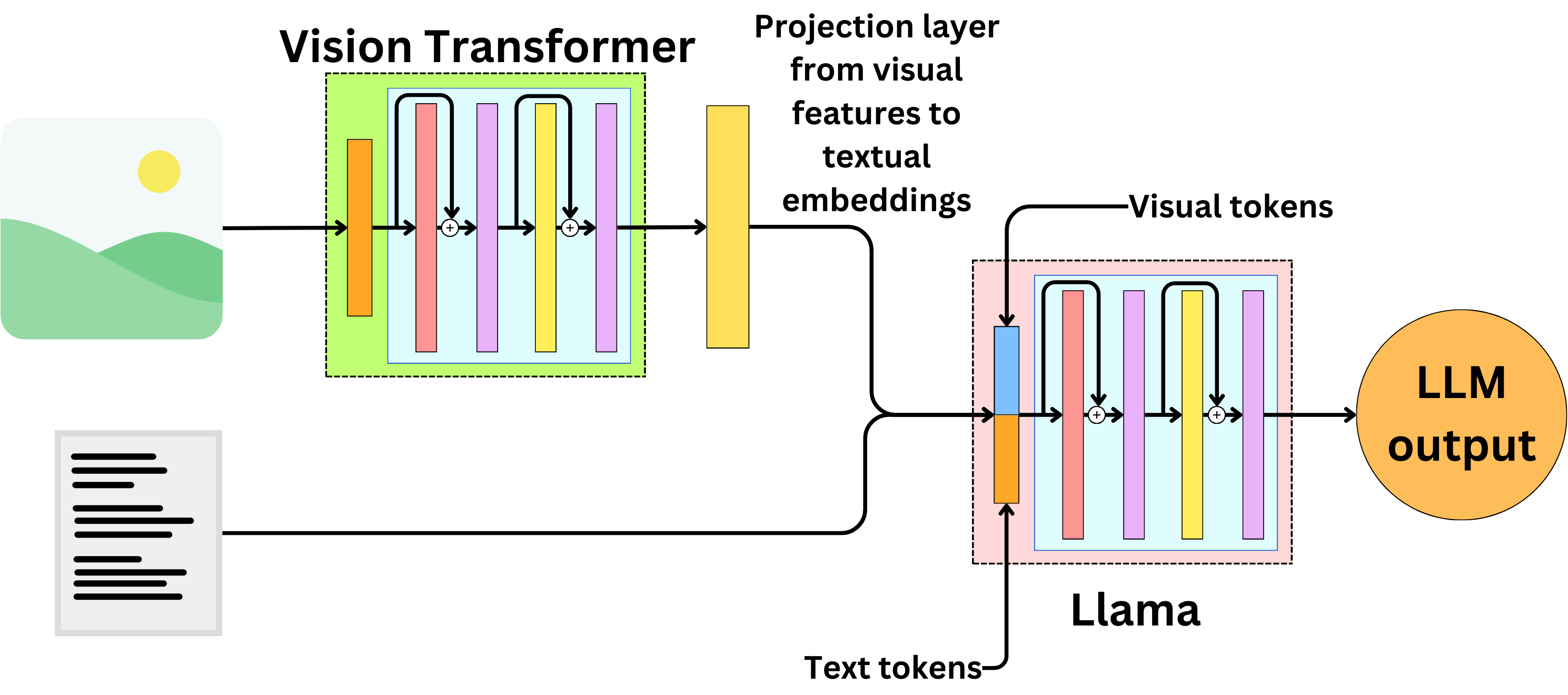




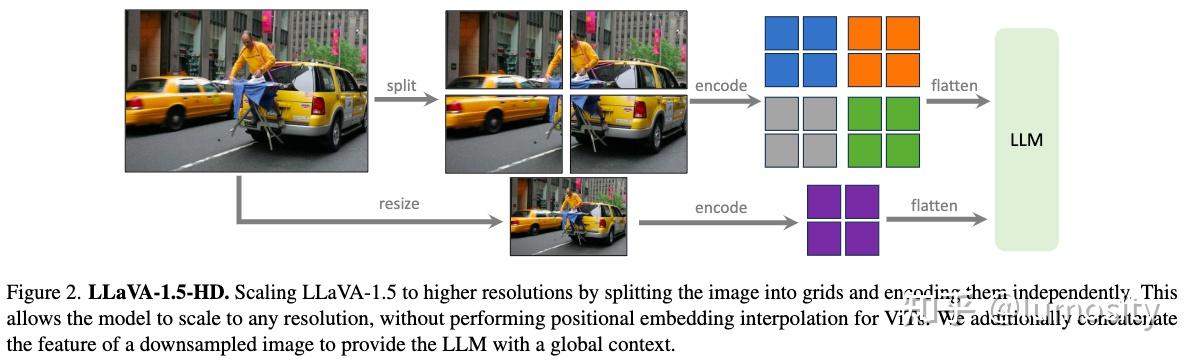







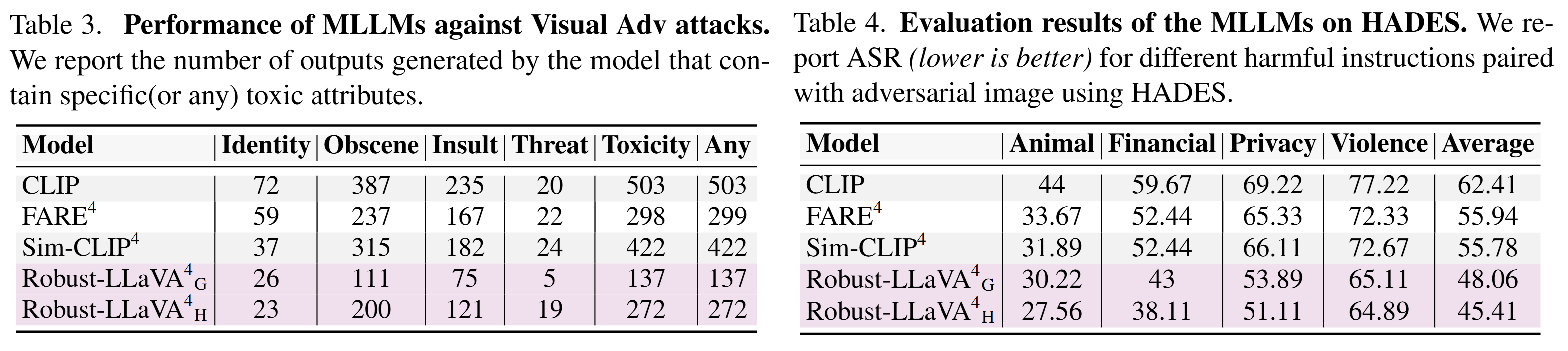
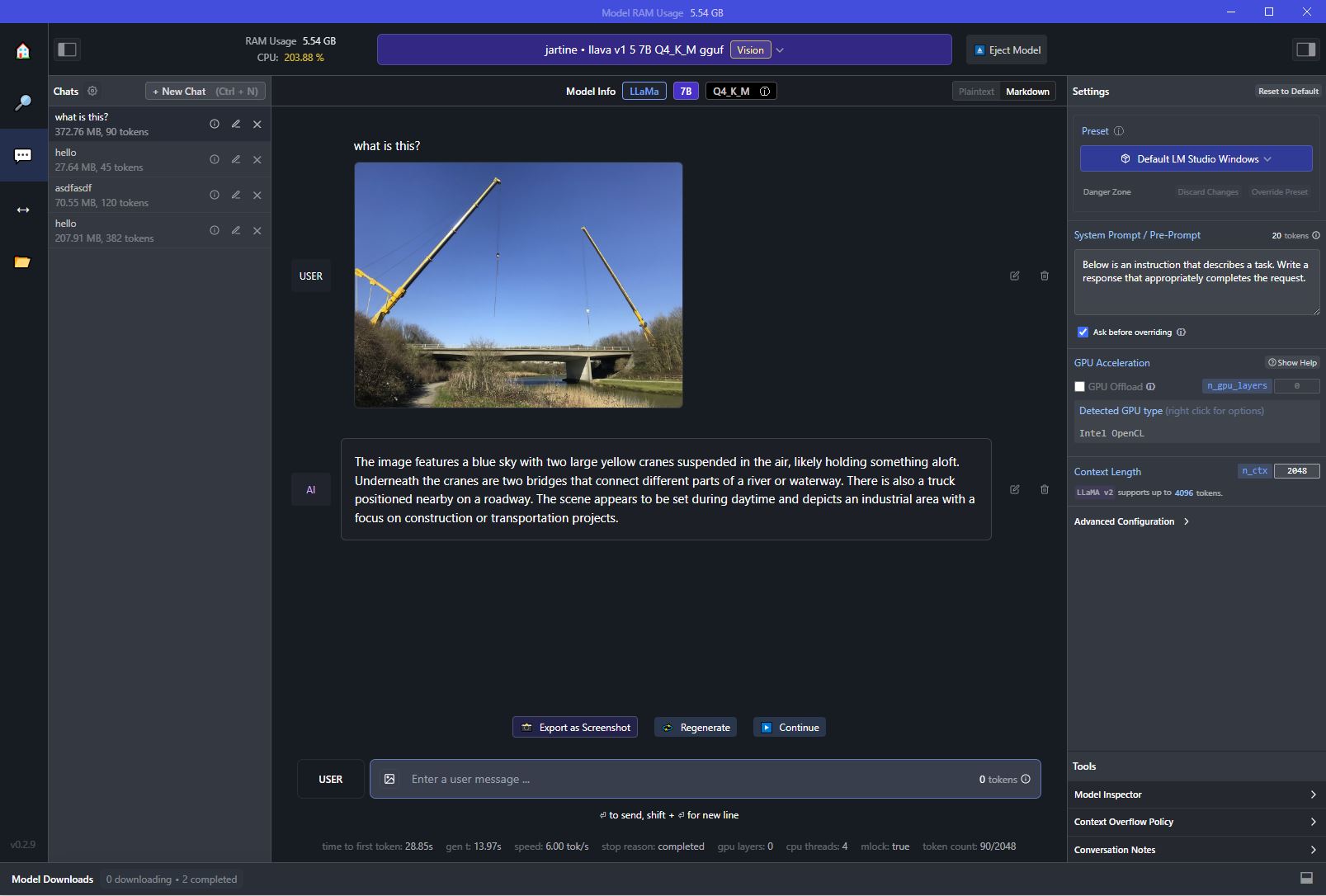



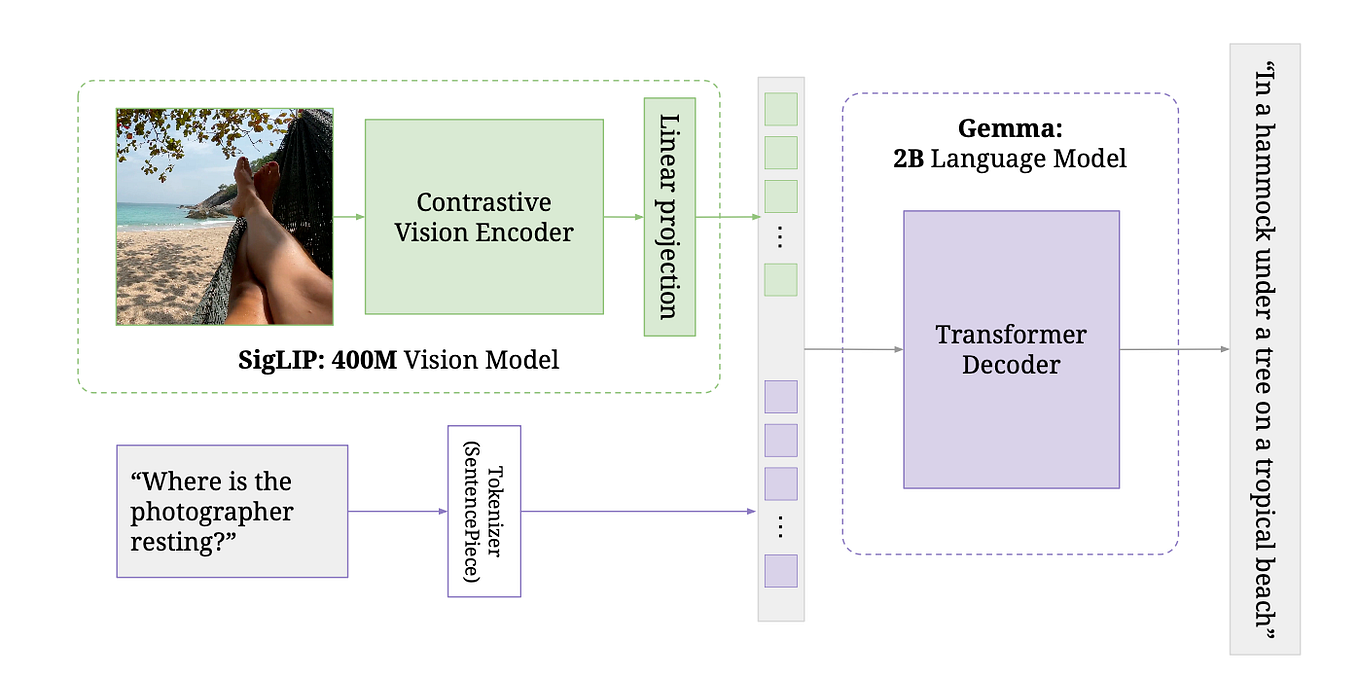

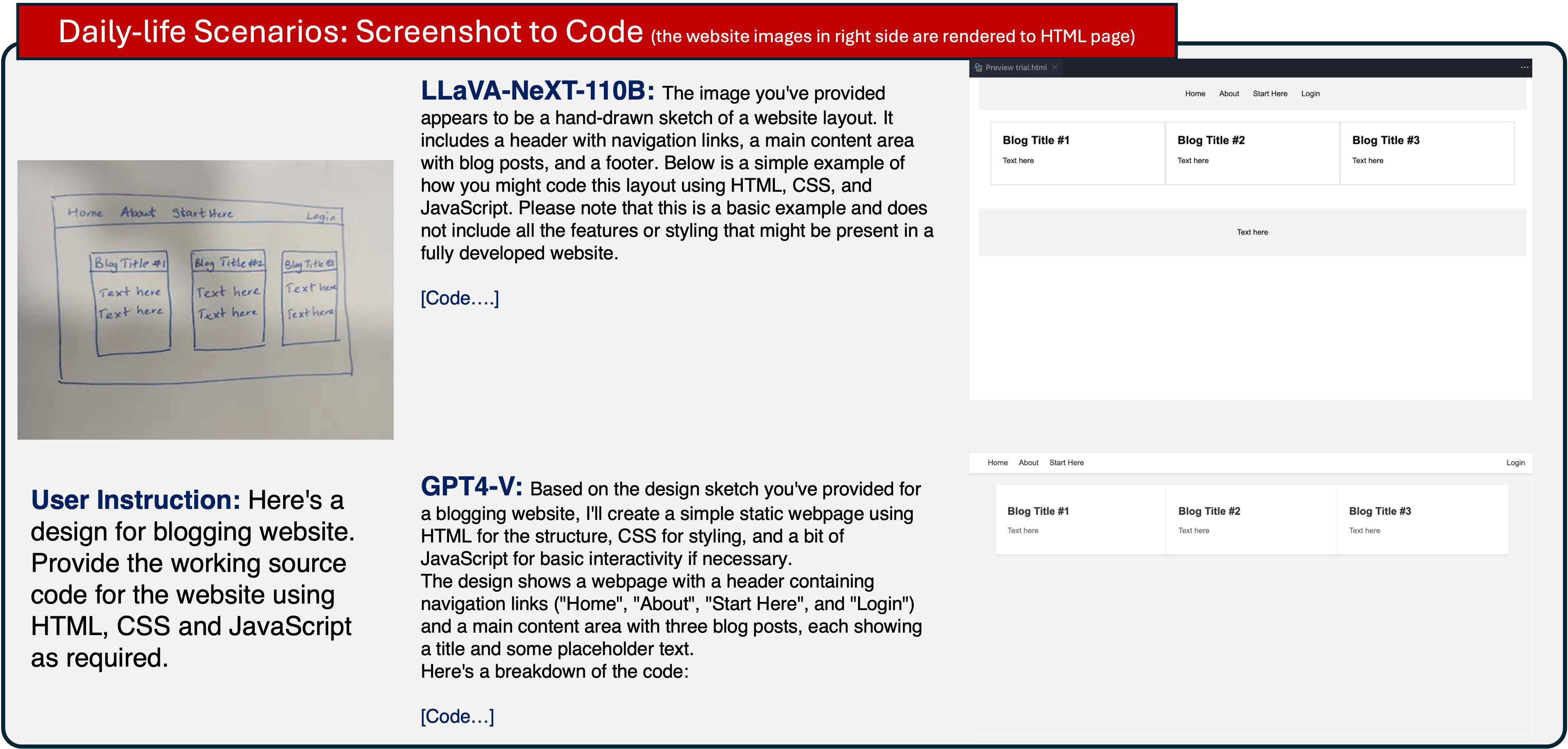

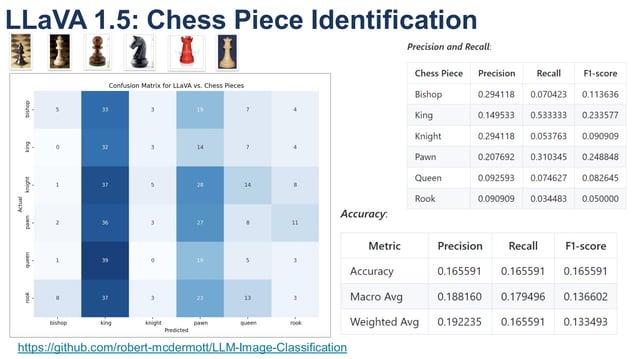

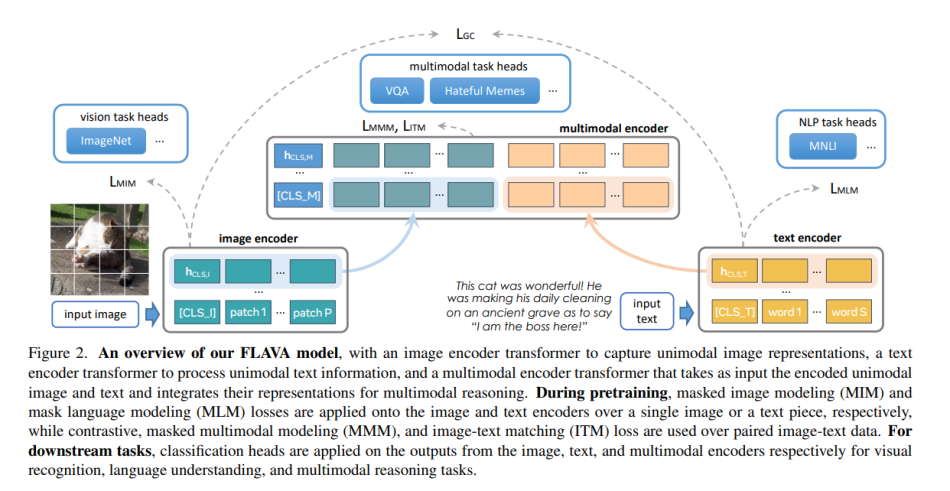






Enhance your business with our remarkable commercial image analysis using llava model. running a multimodal llava model, for collection of comprehensive galleries of professional images. designed for business applications featuring picture, photo, and photograph. ideal for corporate communications and branding. Each image analysis using llava model. running a multimodal llava model, for image is carefully selected for superior visual impact and professional quality. Suitable for various applications including web design, social media, personal projects, and digital content creation All image analysis using llava model. running a multimodal llava model, for images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Discover the perfect image analysis using llava model. running a multimodal llava model, for images to enhance your visual communication needs. Professional licensing options accommodate both commercial and educational usage requirements. Advanced search capabilities make finding the perfect image analysis using llava model. running a multimodal llava model, for image effortless and efficient. Multiple resolution options ensure optimal performance across different platforms and applications. The image analysis using llava model. running a multimodal llava model, for collection represents years of careful curation and professional standards.