




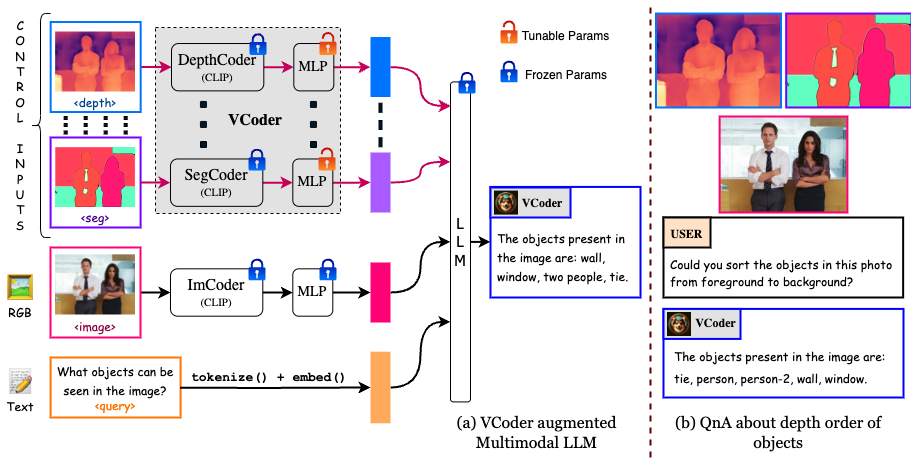


![[논문 리딩] VCodeR: Versatile Vision Encoders for Multimodal Large Language ...](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https:%2F%2Fblog.kakaocdn.net%2Fdna%2FHA1AG%2FbtsIozTrH5k%2FAAAAAAAAAAAAAAAAAAAAAP3p_NwXTD18EJq2LbTrlVa3UjjOP_Uc7xf5vwSy30kz%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1759244399%26allow_ip%3D%26allow_referer%3D%26signature%3Dpd9z4Mm9fBvr6JAzPkf%252BYdxLky8%253D)





























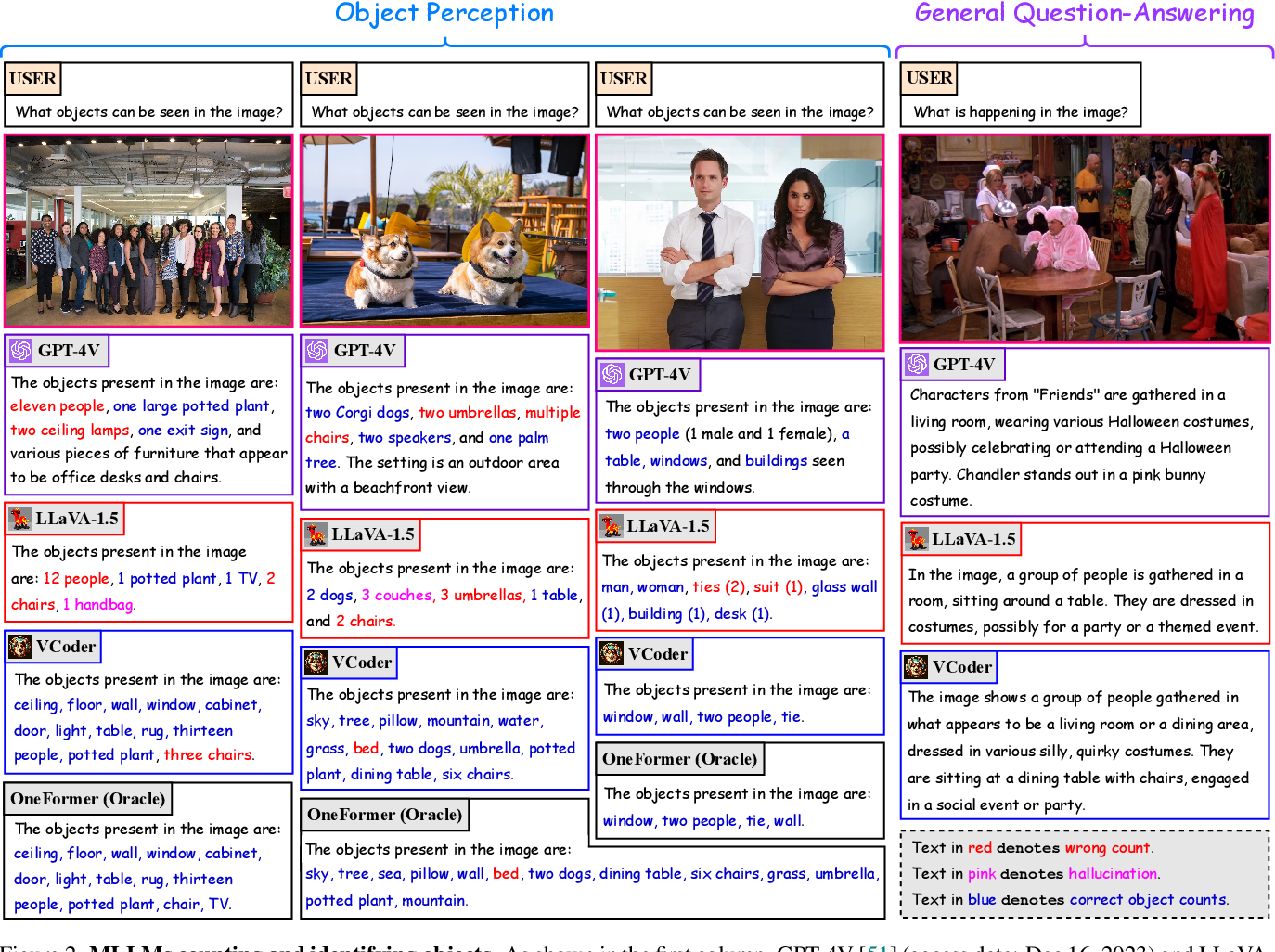
![[논문 리뷰] Voice Activity Projection Model with Multimodal Encoders](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/voice-activity-projection-model-with-multimodal-encoders-1.png)





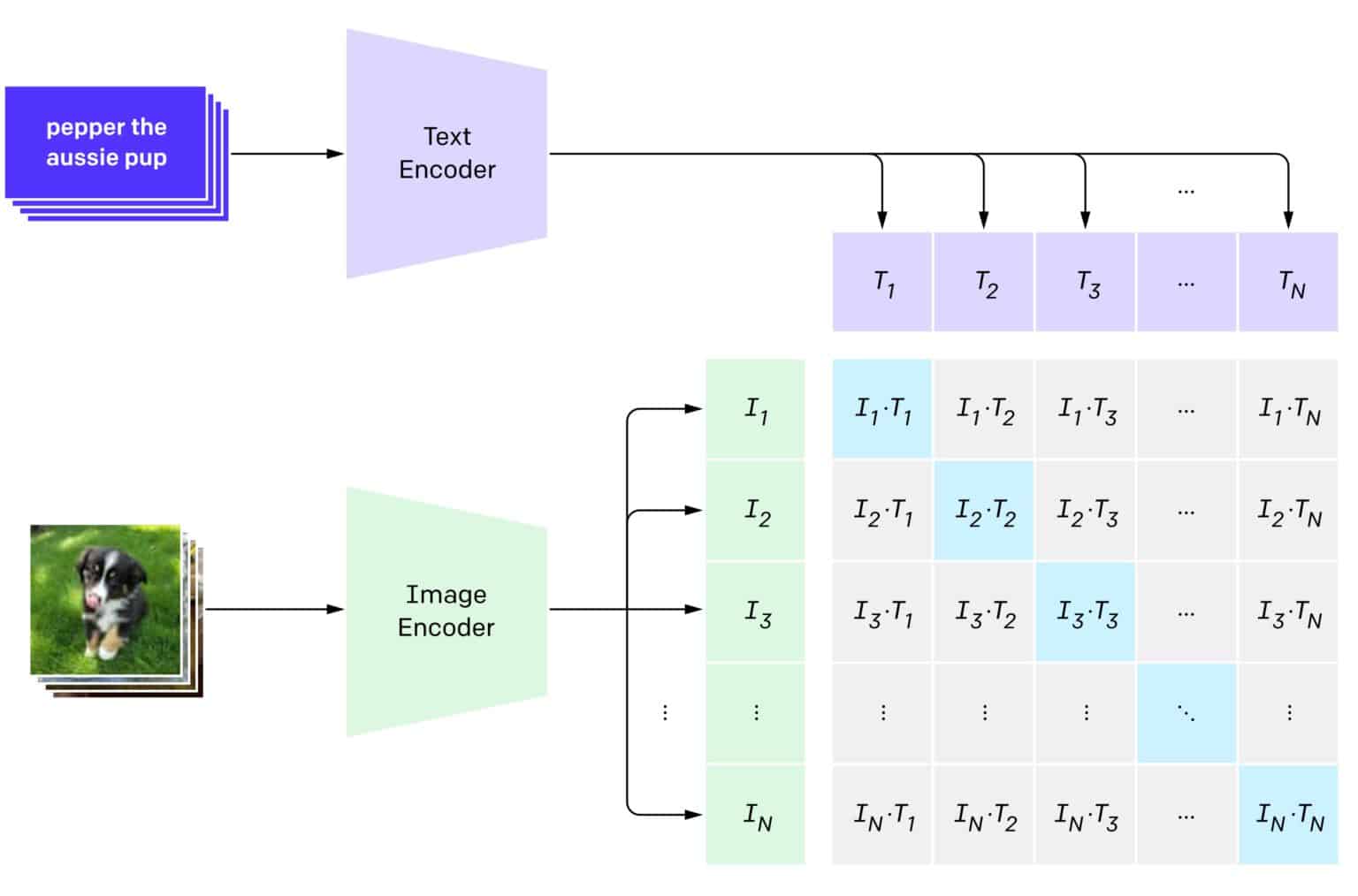


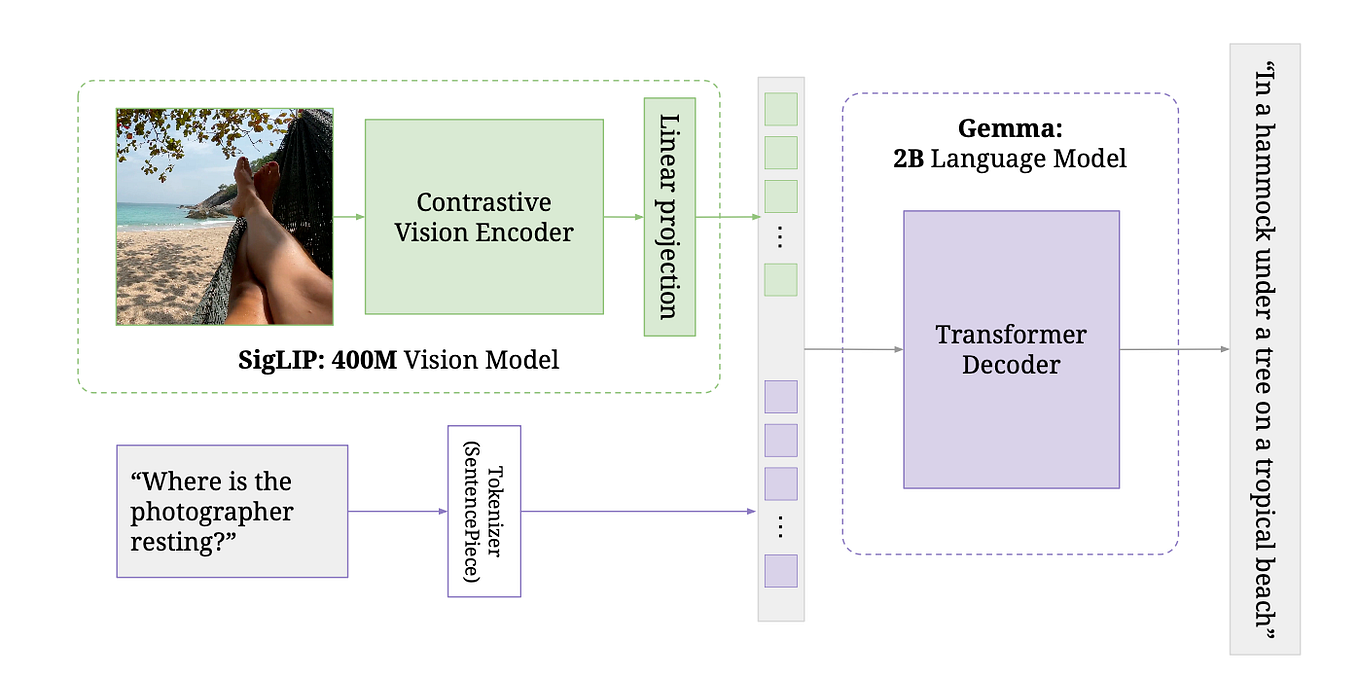

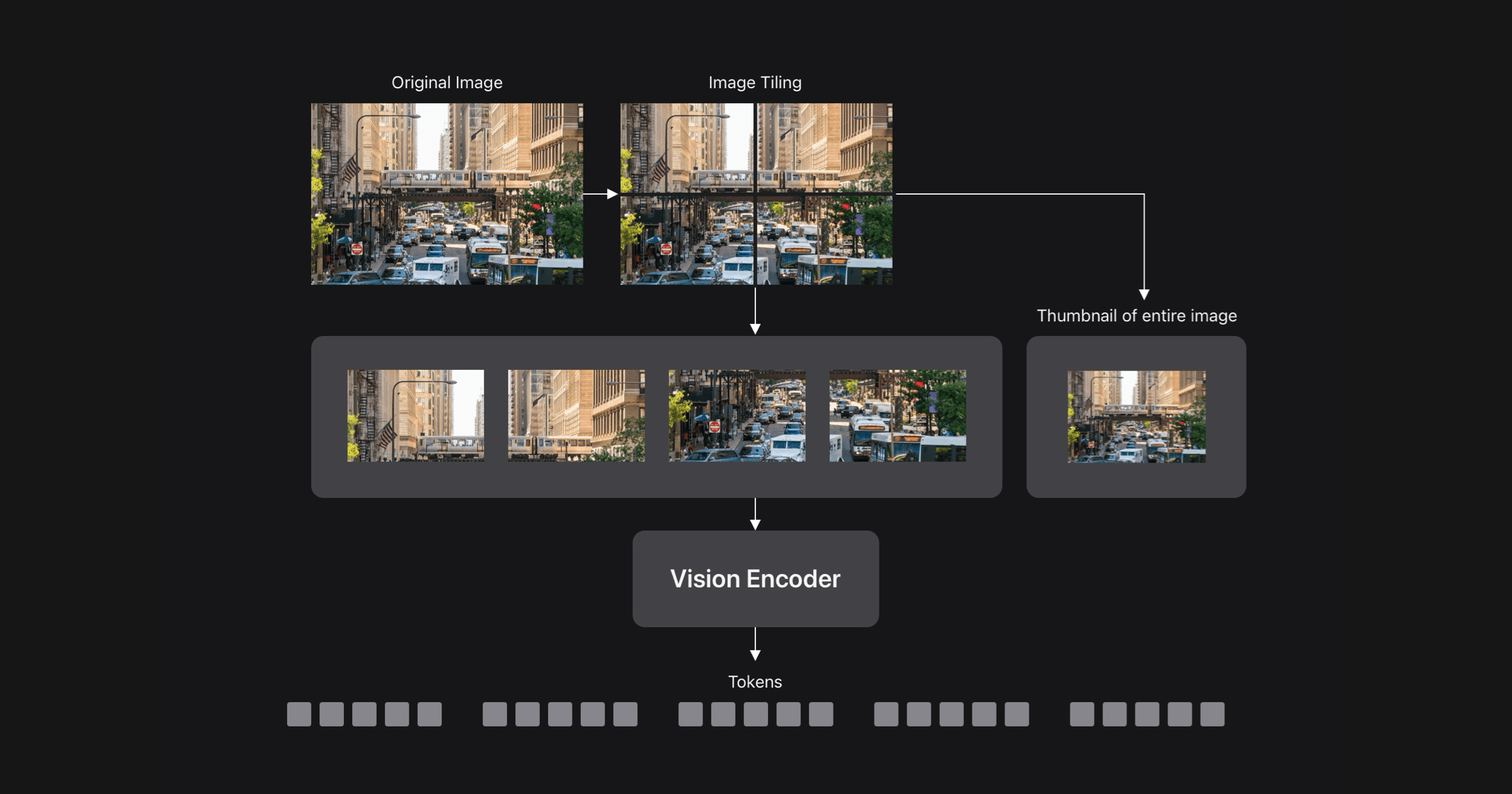

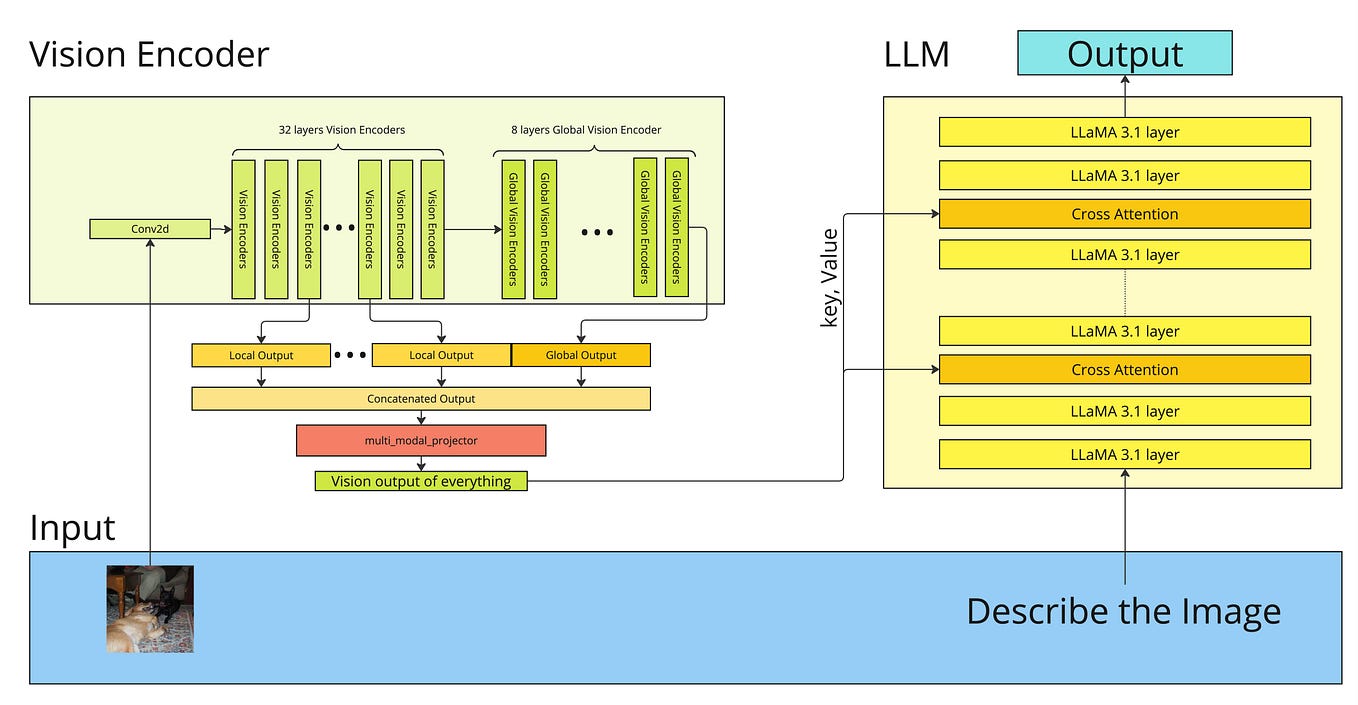
![[PDF] Qwen-VL: A Versatile Vision-Language Model for Understanding ...](https://d3i71xaburhd42.cloudfront.net/fc6a2f7478f68adefd69e2071f27e38aa1647f2f/500px/1-Figure1-1.png)





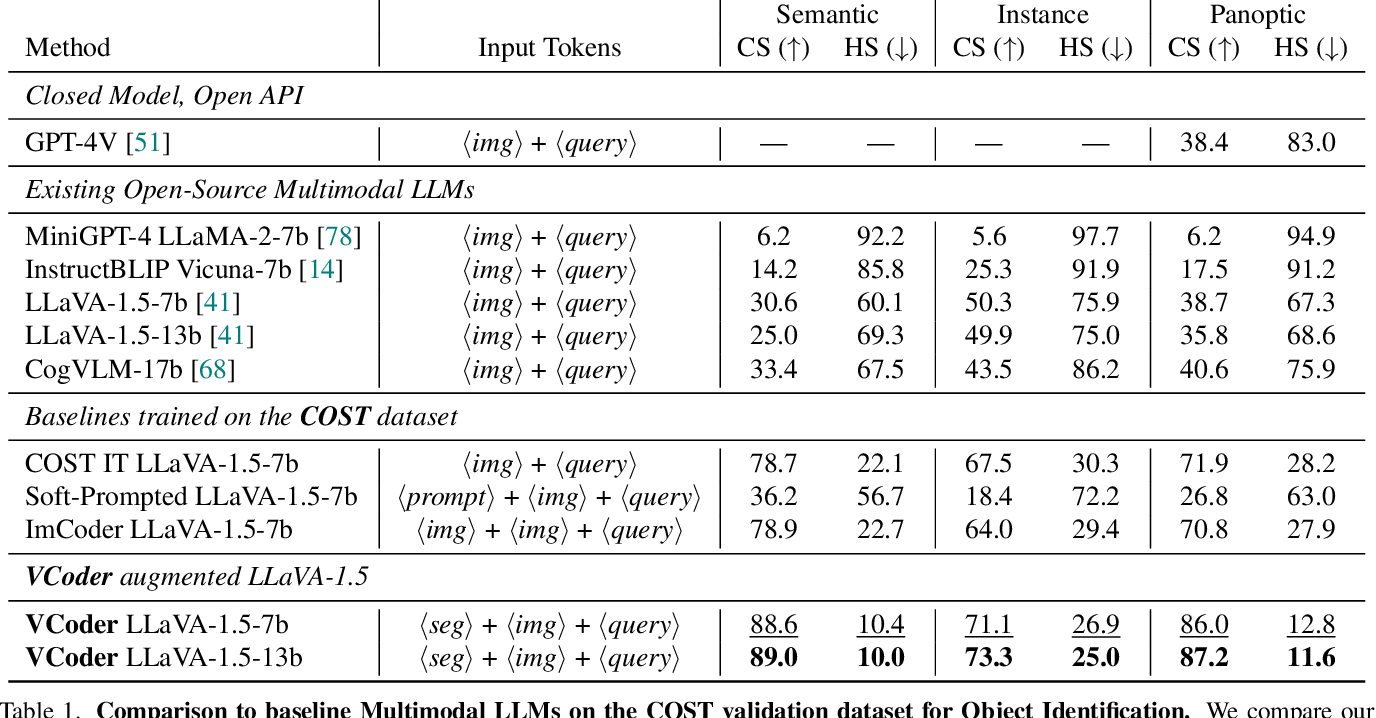
![[논문 리뷰] LEO: Boosting Mixture of Vision Encoders for Multimodal Large ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/leo-boosting-mixture-of-vision-encoders-for-multimodal-large-language-models-0.png)















![[MultiModal] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...](https://velog.velcdn.com/images/ji1kang/post/cad8b2c1-bbbb-451e-90a7-d8cfeef25eae/image.png)


![[2211.12402] X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks](https://ar5iv.labs.arxiv.org/html/2211.12402/assets/x2.png)


Enhance care with our medical vcoder: versatile vision encoders for multimodal large language models gallery of hundreds of therapeutic images. therapeutically illustrating photography, images, and pictures. designed to support medical professionals. Our vcoder: versatile vision encoders for multimodal large language models collection features high-quality images with excellent detail and clarity. Suitable for various applications including web design, social media, personal projects, and digital content creation All vcoder: versatile vision encoders for multimodal large language models images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Discover the perfect vcoder: versatile vision encoders for multimodal large language models images to enhance your visual communication needs. Multiple resolution options ensure optimal performance across different platforms and applications. Time-saving browsing features help users locate ideal vcoder: versatile vision encoders for multimodal large language models images quickly. Professional licensing options accommodate both commercial and educational usage requirements. Regular updates keep the vcoder: versatile vision encoders for multimodal large language models collection current with contemporary trends and styles. The vcoder: versatile vision encoders for multimodal large language models collection represents years of careful curation and professional standards. Diverse style options within the vcoder: versatile vision encoders for multimodal large language models collection suit various aesthetic preferences.