Please enter url.
Login
Logout
Please enter url.
Meet Video-LLaMA: A Multi-Modal Framework that Empowers Large Language ...
aiguido.com
source
Comments
Meet Video-LLaMA: A Multi-Modal Framework that Empowers Large Language ...
Unsupervised incremental adaptation of language models in speech ...
(PDF) Improving Distantly Supervised Relation Extraction using Word and ...
HYCEDIS architecture. (a) The Multi-modal Conformal Predictor (MCP ...
A classical early fusion multimodal approach. Figure 2: The late fusion ...
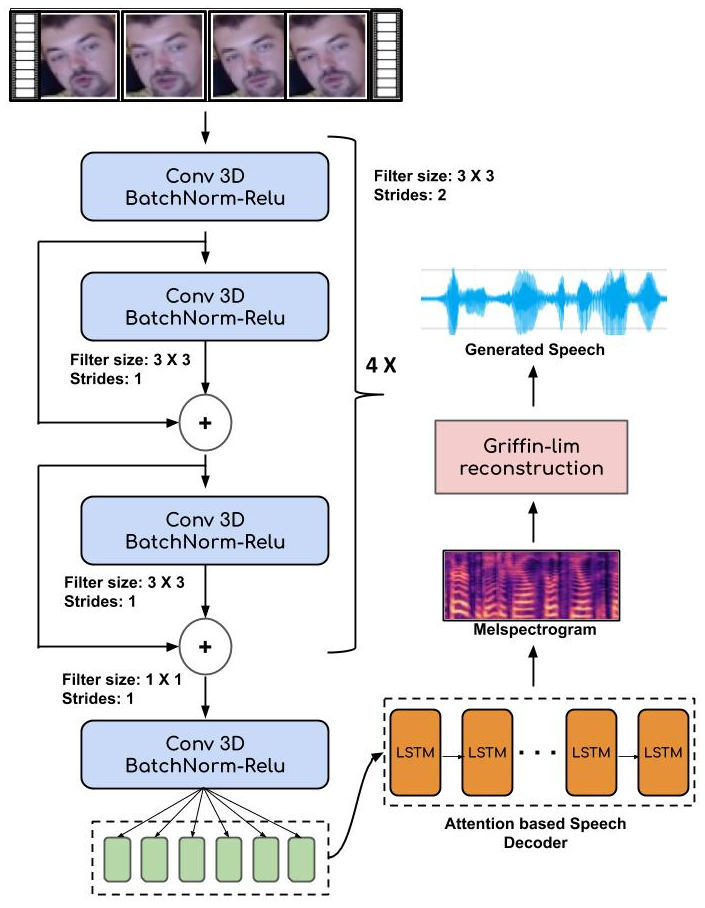
Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
Overview of the offline and online stages of the proposed many-to-one ...
Example HTA to borrow a library book | Download Scientific Diagram
Multimodal architecture for multi-speaker acoustic models with ...
Architecture of Our System | Download Scientific Diagram
Tianlang Chen
Figure 1 from Semi-supervised End-to-end Speech Recognition Using Text ...
(PDF) Sign Language Transformers: Joint End-to-End Sign Language ...
A block diagram of the proposed model | Download Scientific Diagram
The diagram of proposed multi-modal target speech separation framework ...
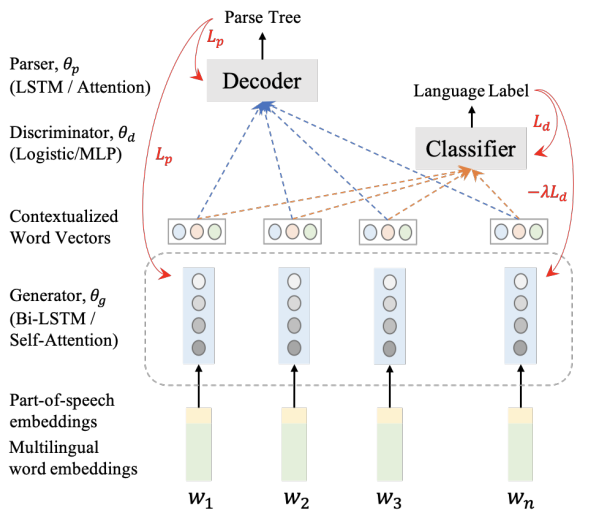
Cross-lingual Dependency Parsing with Unlabeled Auxiliary Languages
Figure 1 from Learning Alignment for Multimodal Emotion Recognition ...
An overview of the Transformer-based Encoder applied for LRE using ...
Figure 1 from MMG-Ego4D: Multi-Modal Generalization in Egocentric ...
ZeroEGGS: Zero‐shot Example‐based Gesture Generation from Speech ...
Proposed classifier architecture. Notation of convolutional layers ...
Our DNN structure for keyword mask estimation. The output of DNN is two ...
Figure 1 from Interpretable Multimodal Deception Detection in Videos ...
The applied deep learning models, which are the encoder-decoder ...
Publications
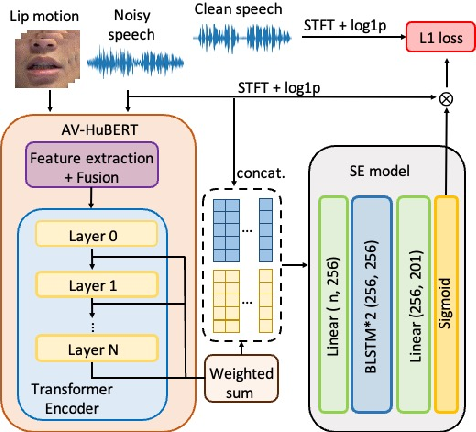
Figure 1 from Audio-Visual Speech Enhancement and Separation by ...
Graphical representation of the components and the respective ...
The overall structure of the proposed multi-level mesh mutual attention ...
The style-adaptive layer normalization. CLN represents "conditional ...
Visualizations of learned targeted communication in SHAPES. Figure best ...
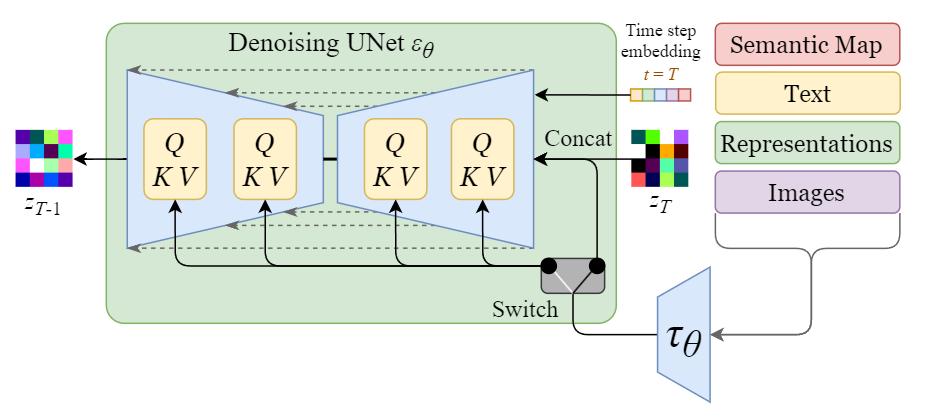
Stable Diffusion Clearly Explained! - CodoRaven
(PDF) MnTTS2: An Open-Source Multi-Speaker Mongolian Text-to-Speech ...
Proposed Conditonal GAN consists of a single Generator and ...
Schematic diagrams of the DNN architecture and signal processing ...
Examples of images in Flickr30K and MS-COCO datasets | Download ...