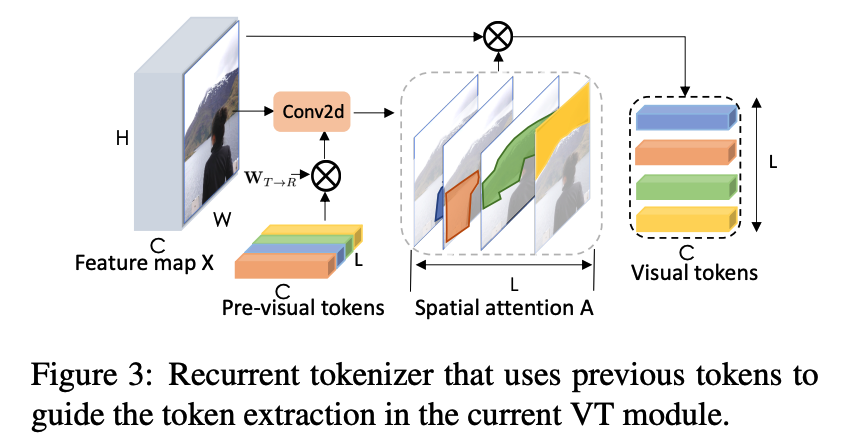
Vision R Tokenization Image





.jpg)




.jpg)









![[2307.02321] MSViT: Dynamic Mixed-scale Tokenization for Vision ...](https://ar5iv.labs.arxiv.org/html/2307.02321/assets/x2.png)



![[리뷰]Superpixel Tokenization for Vision Transformers: Preserving ...](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FCGv66%2FbtsMKiGgF8t%2F8iGGK28mb0cLkMjKn7zGgK%2Fimg.png)






![[논문 정리] Vision Transformers with Mixed-Resolution Tokenization](https://velog.velcdn.com/images/bluein/post/a15ffe7c-7eac-4254-b8e3-a7126d40e4cd/image.png)






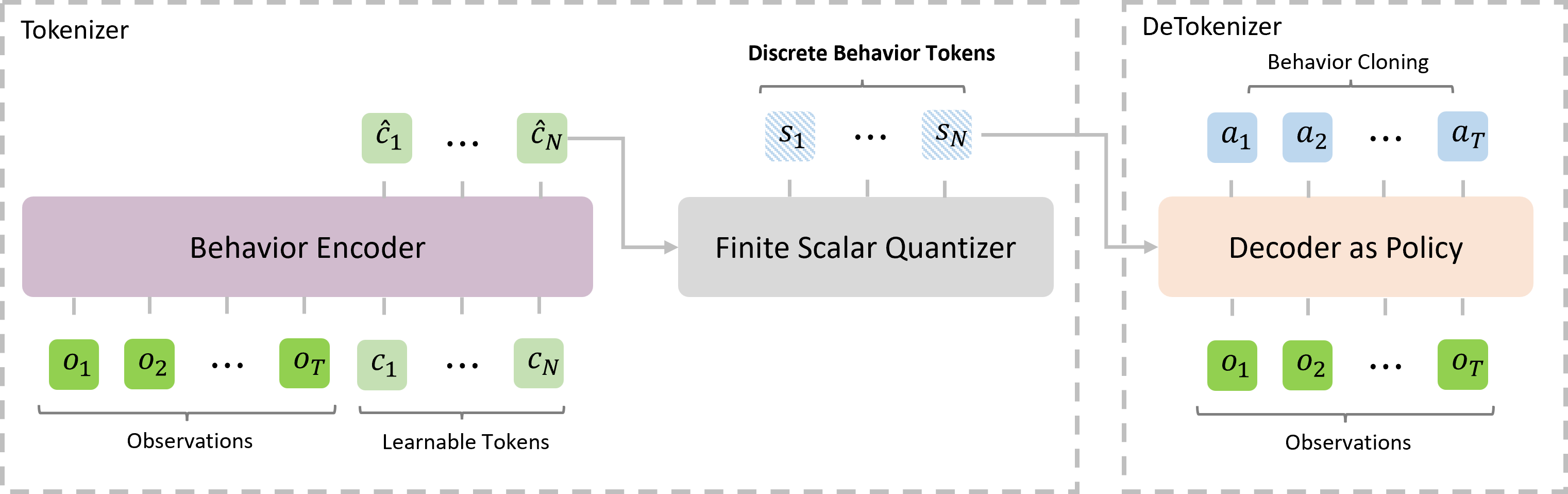

















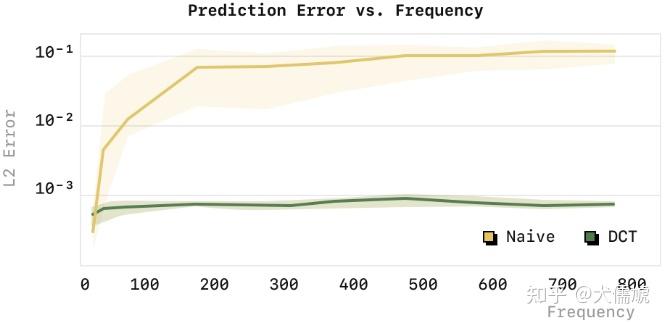
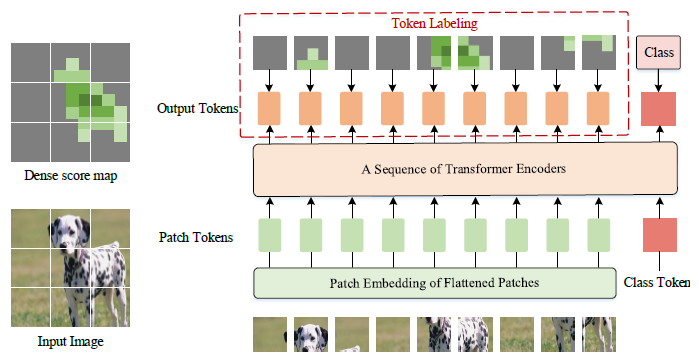







![[2212.11115] What Makes for Good Tokenizers in Vision Transformer?](https://ar5iv.labs.arxiv.org/html/2212.11115/assets/figures/structure.png)

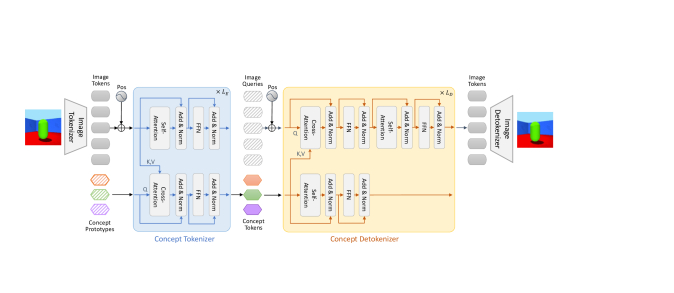
![[论文评述] Focusing on What Matters: Object-Agent-centric Tokenization for ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/focusing-on-what-matters-object-agent-centric-tokenization-for-vision-language-action-models-0.png)

















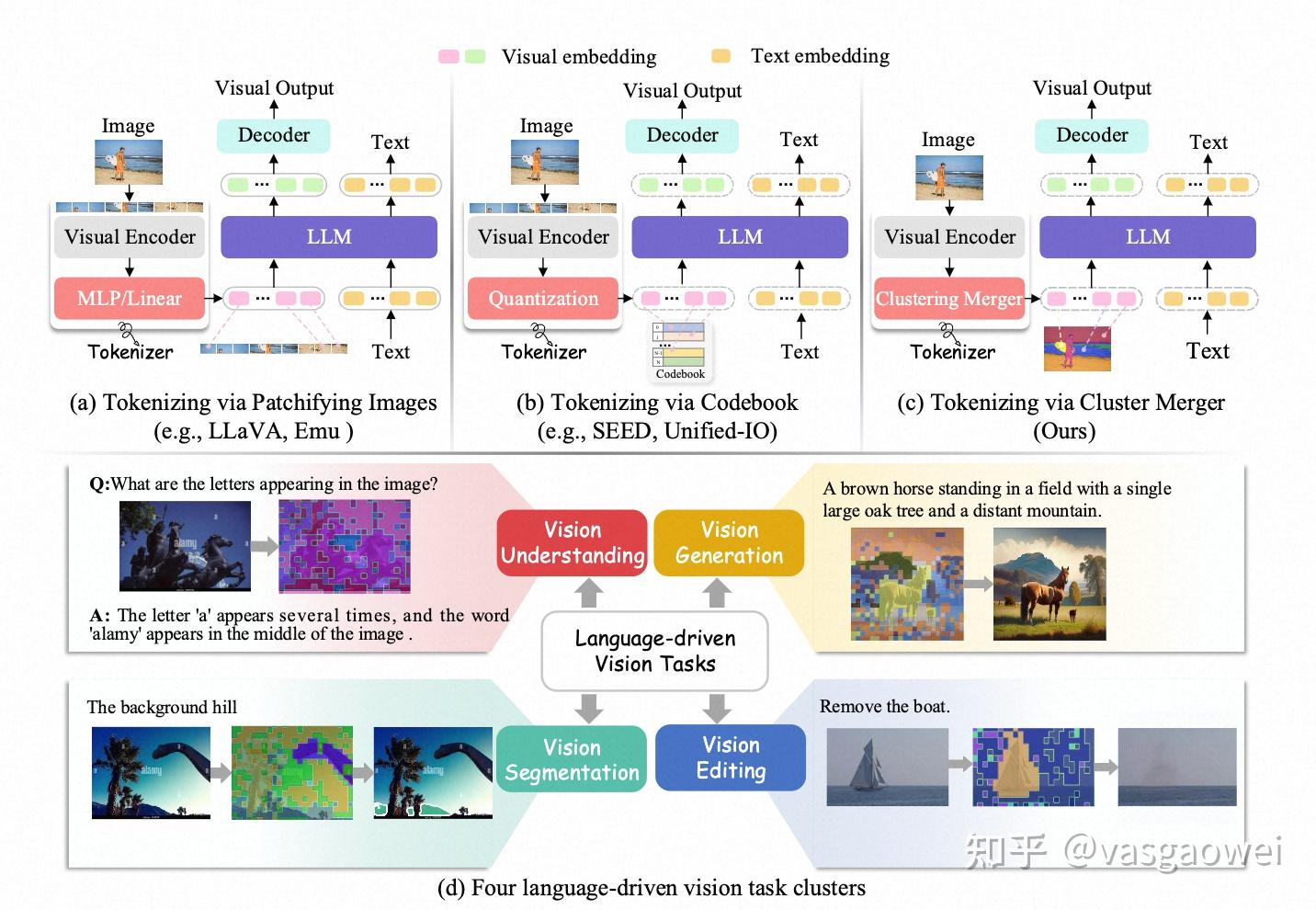


![[MM] LaViT: UNIFIED LANGUAGE-VISION PRETRAINING IN LLM WITH DYNAMIC ...](https://bloomberry.github.io/images/2024-08-28/image-20240828141800914.png)

Boost your marketing with countless commercial-grade Vision R Tokenization Image photographs. crafted for marketing purposes showcasing picture, photo, and photograph. ideal for corporate communications and branding. Each Vision R Tokenization Image is carefully selected for superior visual impact and professional quality. Suitable for various applications including web design, social media, personal projects, and digital content creation All Vision R Tokenization Image images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Explore the versatility of our Vision R Tokenization Image collection for various creative and professional projects. Reliable customer support ensures smooth experience throughout the Vision R Tokenization Image selection process. Each image in our Vision R Tokenization Image gallery undergoes rigorous quality assessment before inclusion. Advanced search capabilities make finding the perfect Vision R Tokenization Image image effortless and efficient. Regular updates keep the Vision R Tokenization Image collection current with contemporary trends and styles. Diverse style options within the Vision R Tokenization Image collection suit various aesthetic preferences. Cost-effective licensing makes professional Vision R Tokenization Image photography accessible to all budgets. Our Vision R Tokenization Image database continuously expands with fresh, relevant content from skilled photographers.