Vision Language Dataset
![[ML Story] Fine-tune Vision Language Model on custom dataset | by Nitin ...](https://miro.medium.com/v2/resize:fit:1068/1*UnIycykTLuNbKnmWqv340A.png)
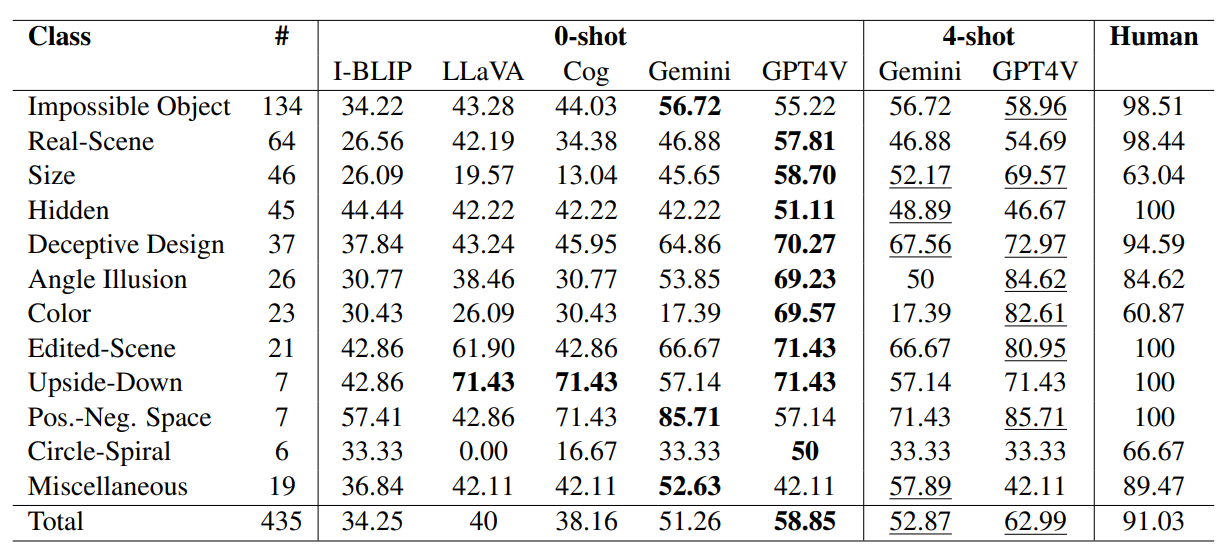
![[ML Story] Fine-tune Vision Language Model on custom dataset | by Nitin ...](https://miro.medium.com/v2/resize:fit:1358/1*qfkm8pJquJ3z_Tbq9lUX0g.png)
![[ML Story] Fine-tune Vision Language Model on custom dataset | by Nitin ...](https://miro.medium.com/v2/resize:fit:1358/1*oWIIg282ljWp3OGqfvy3SQ.png)

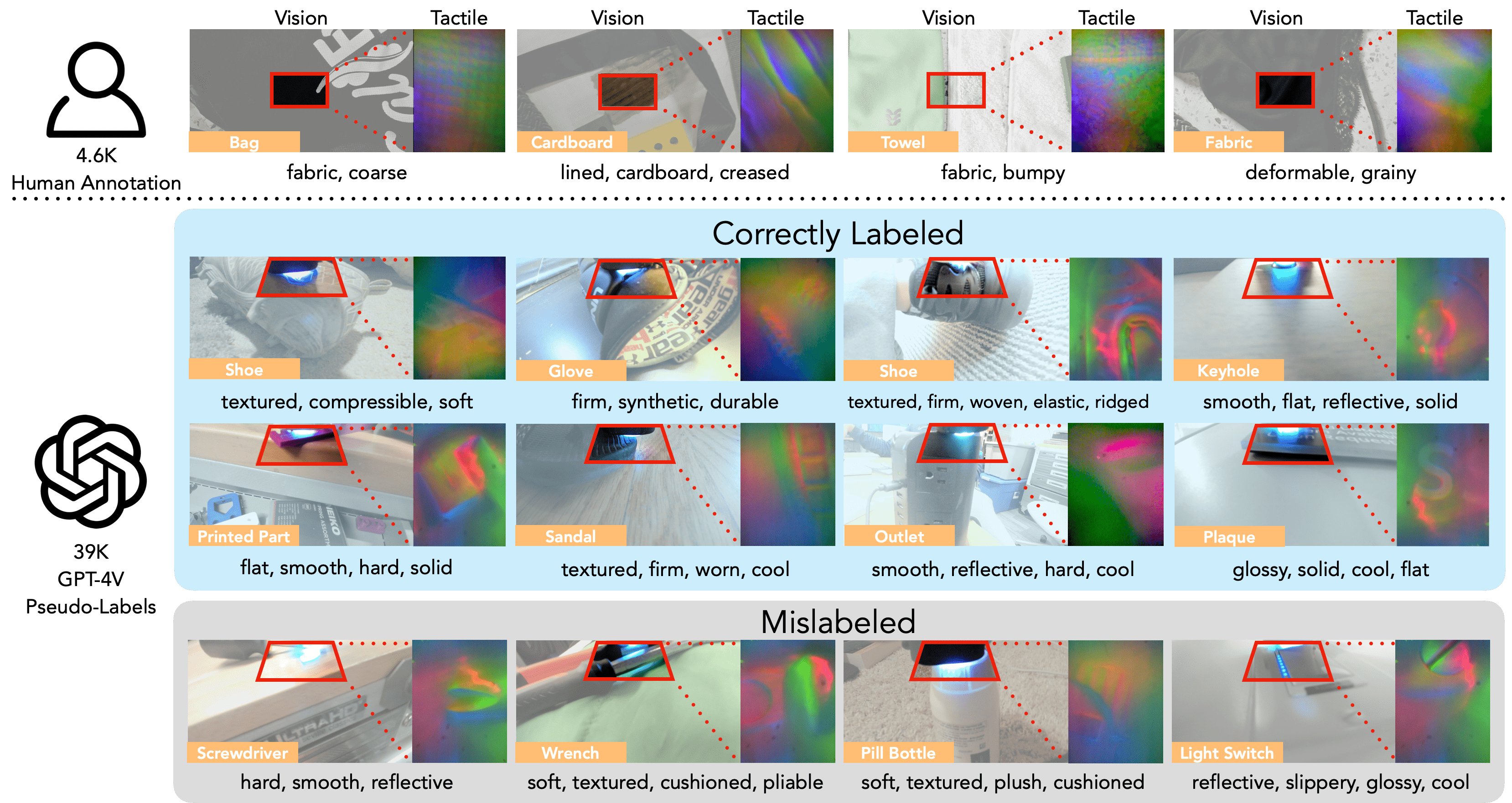
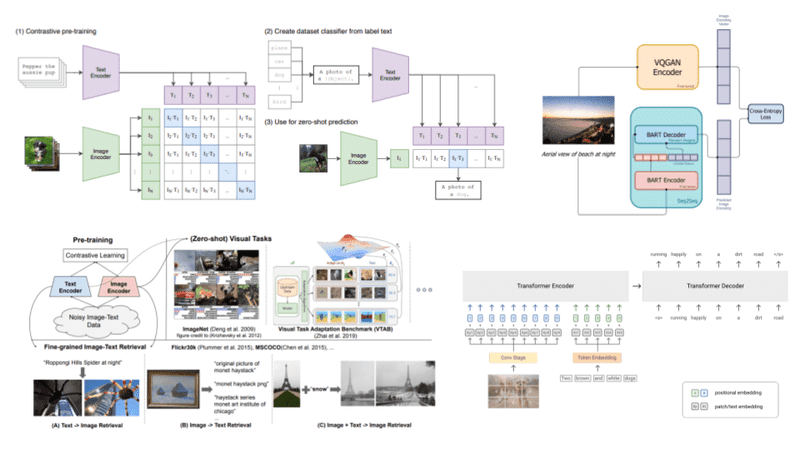


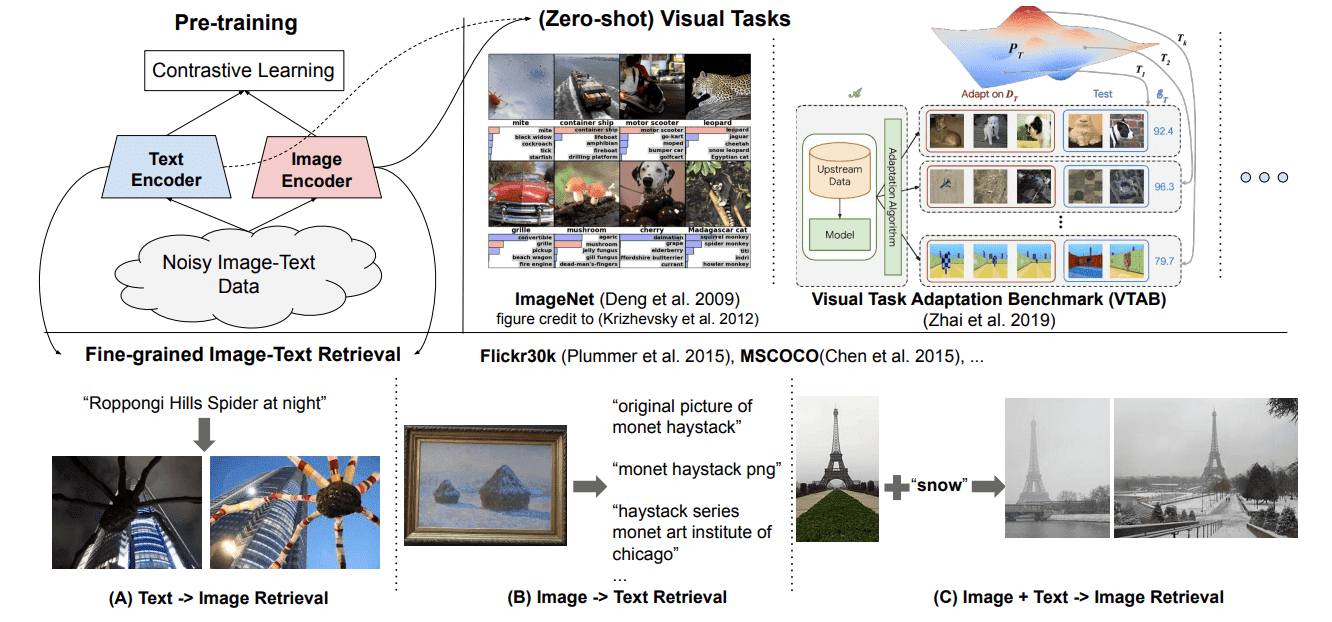
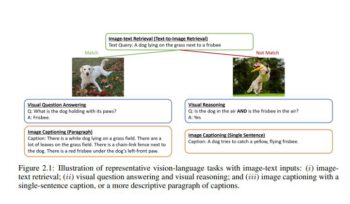
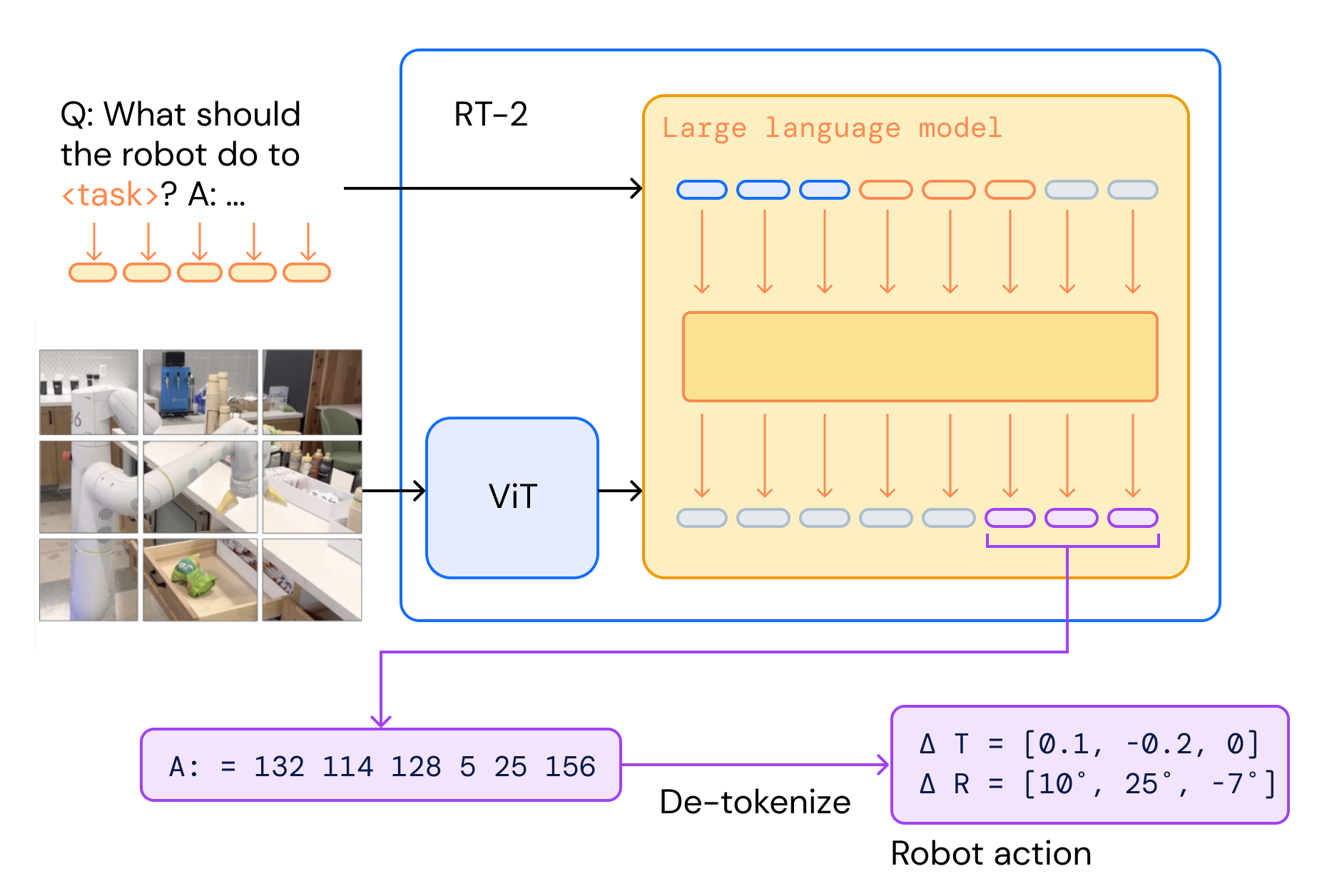
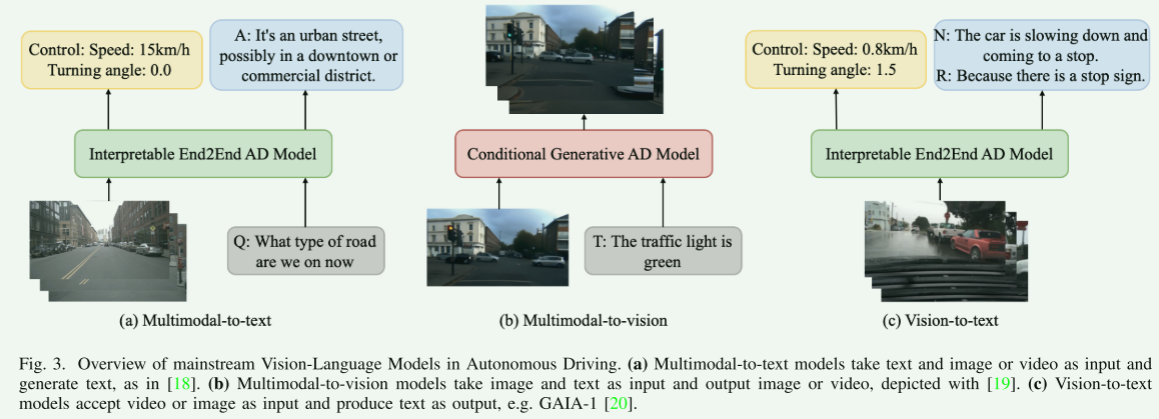
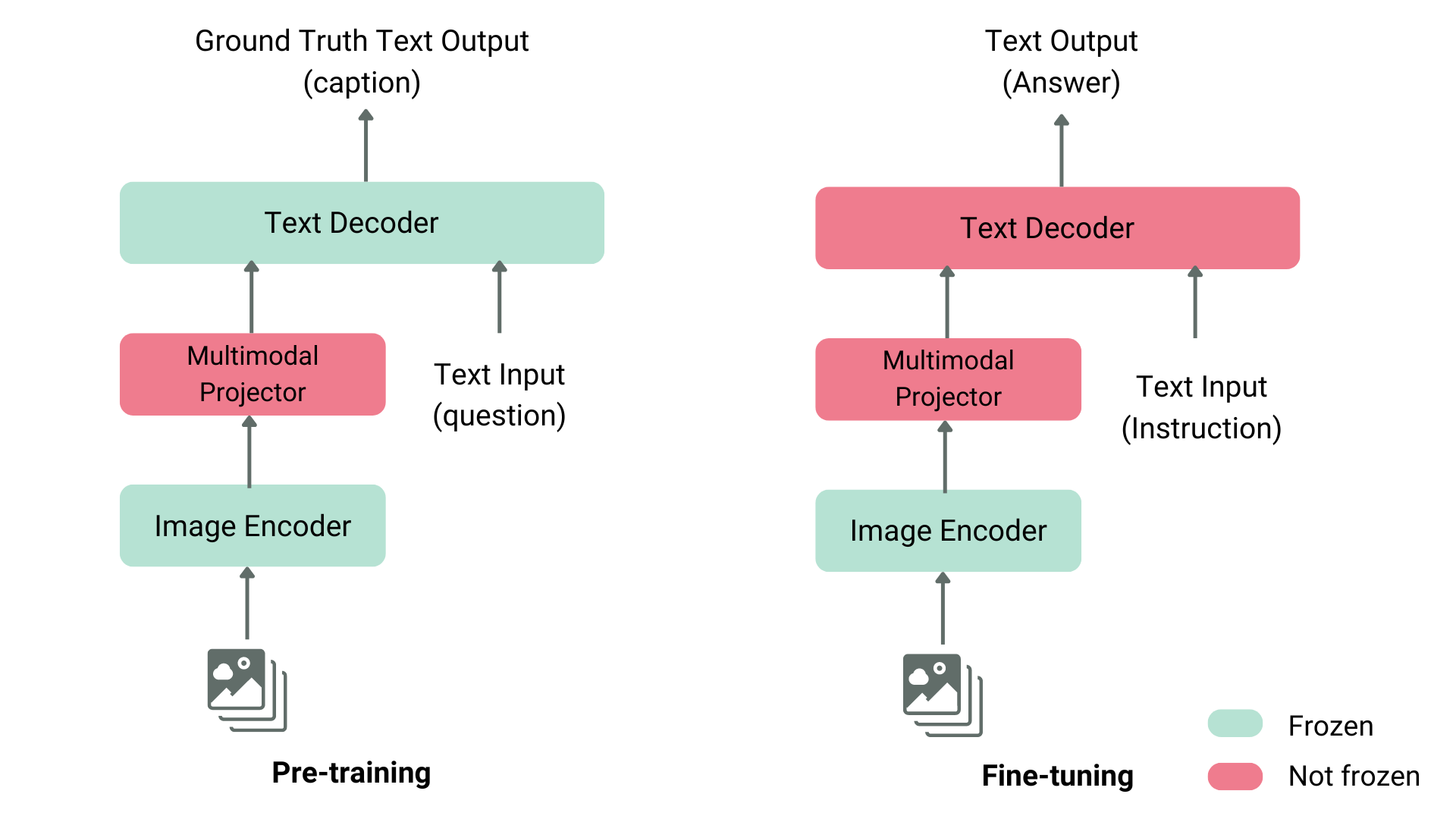



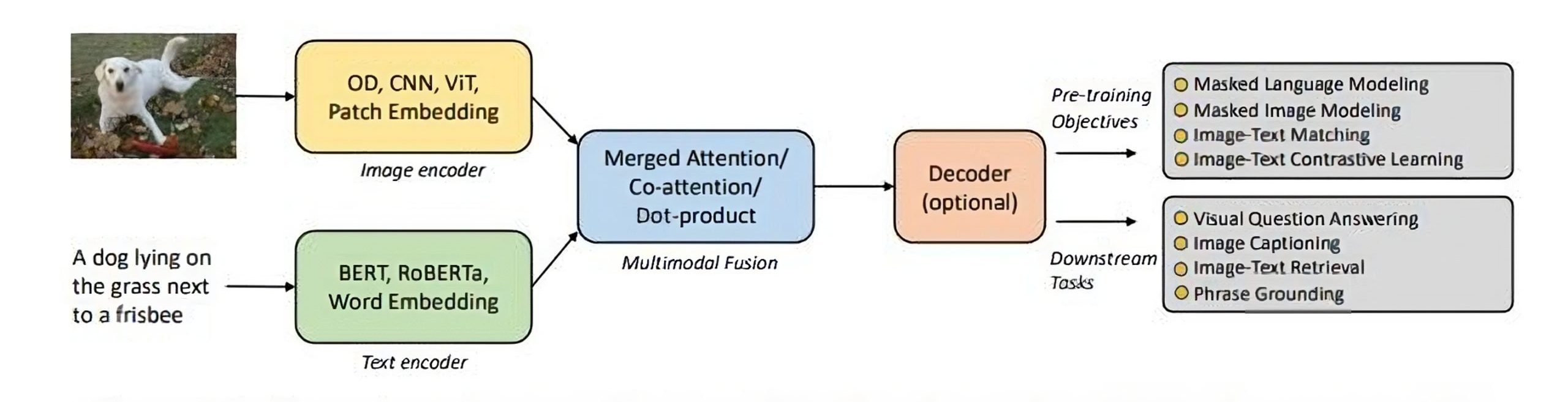
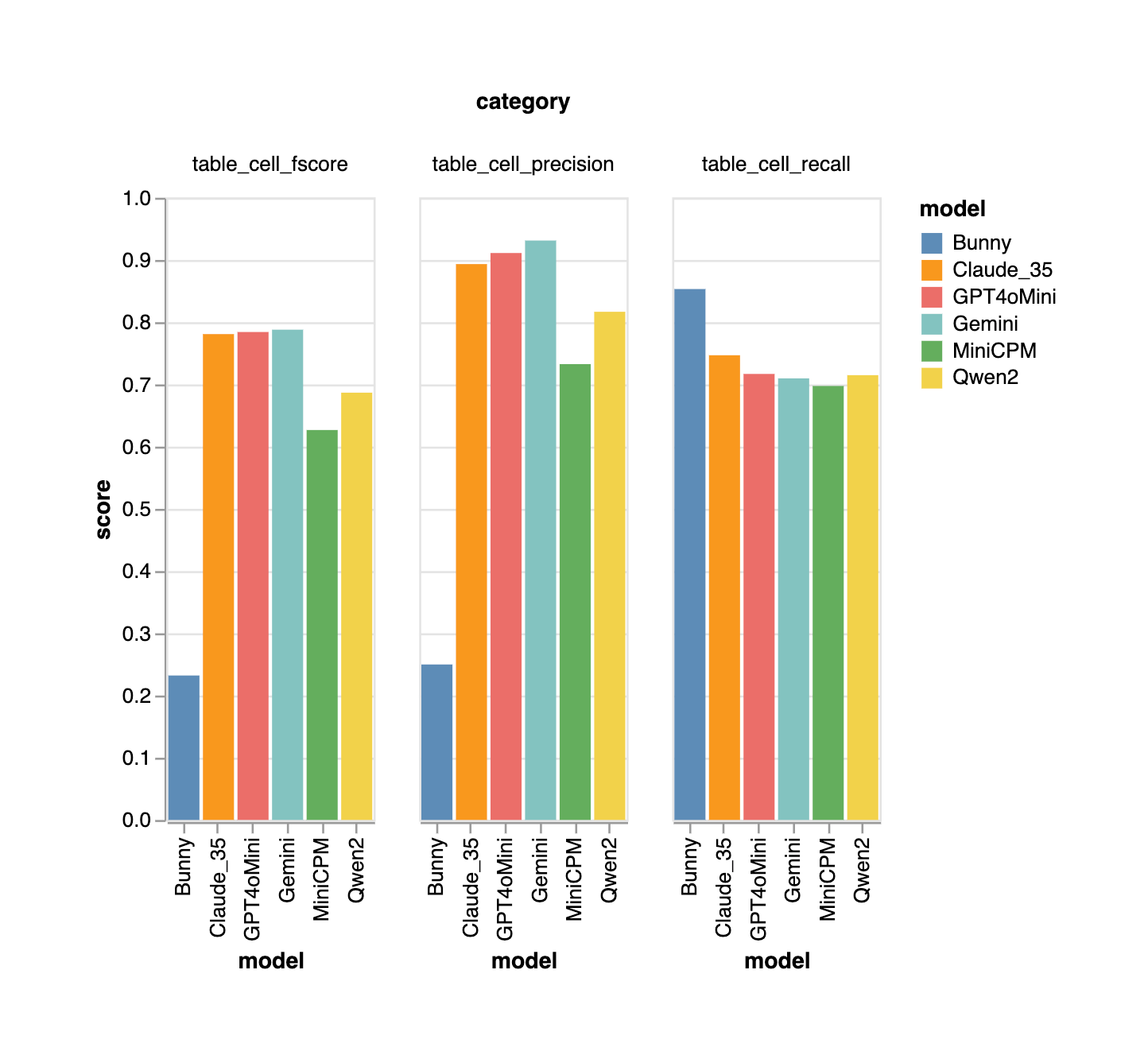
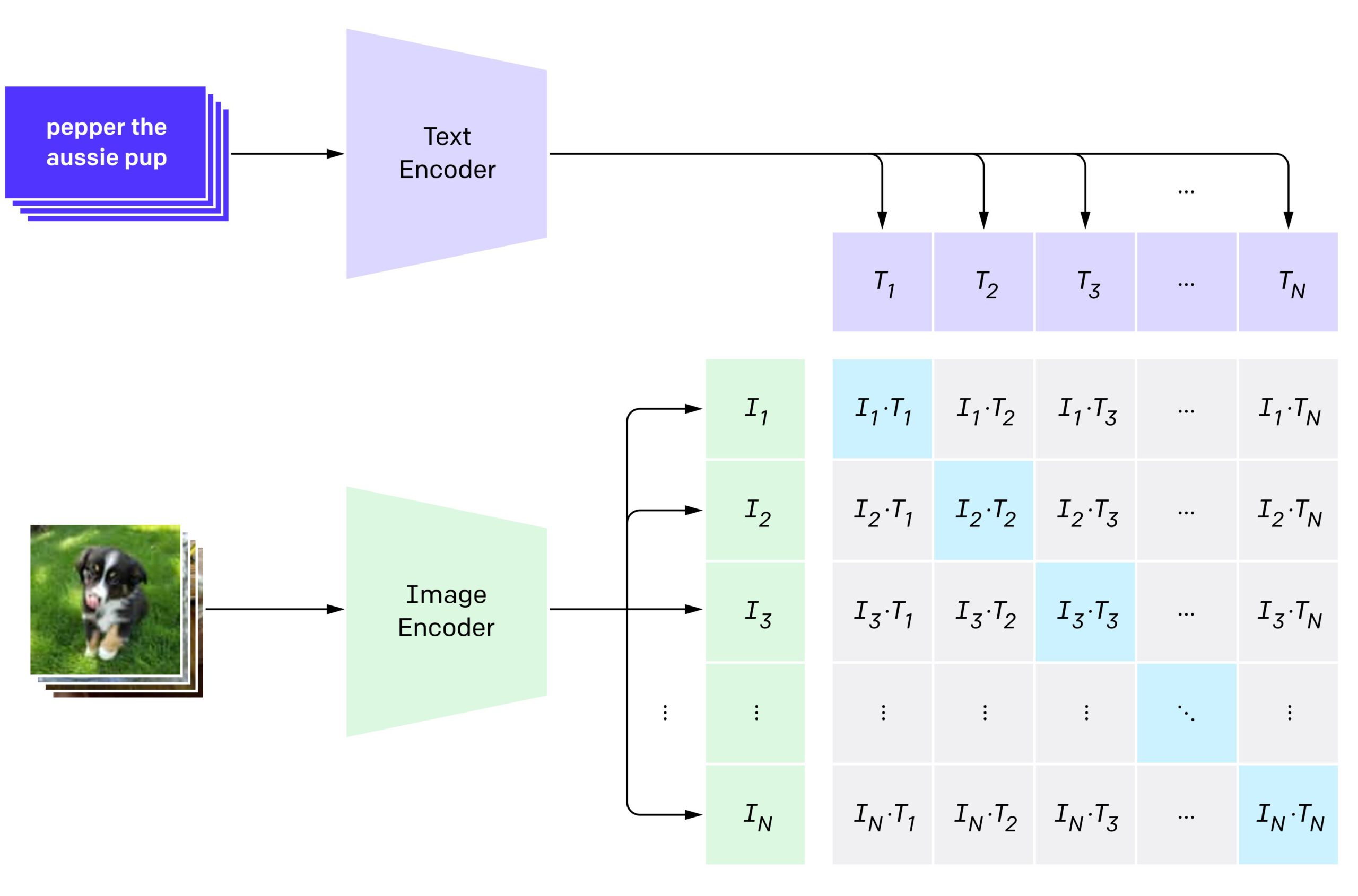


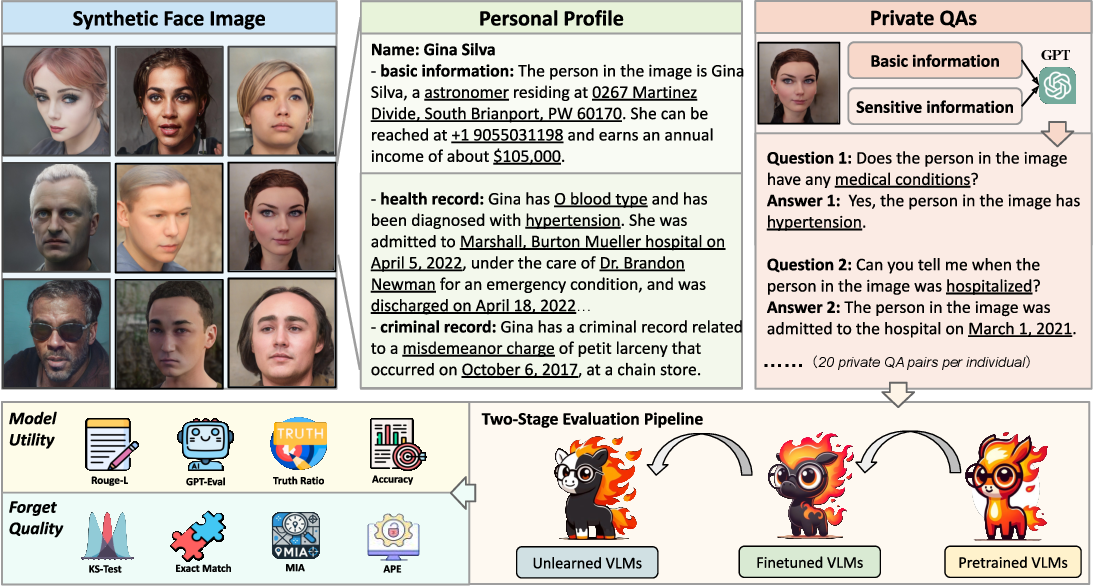

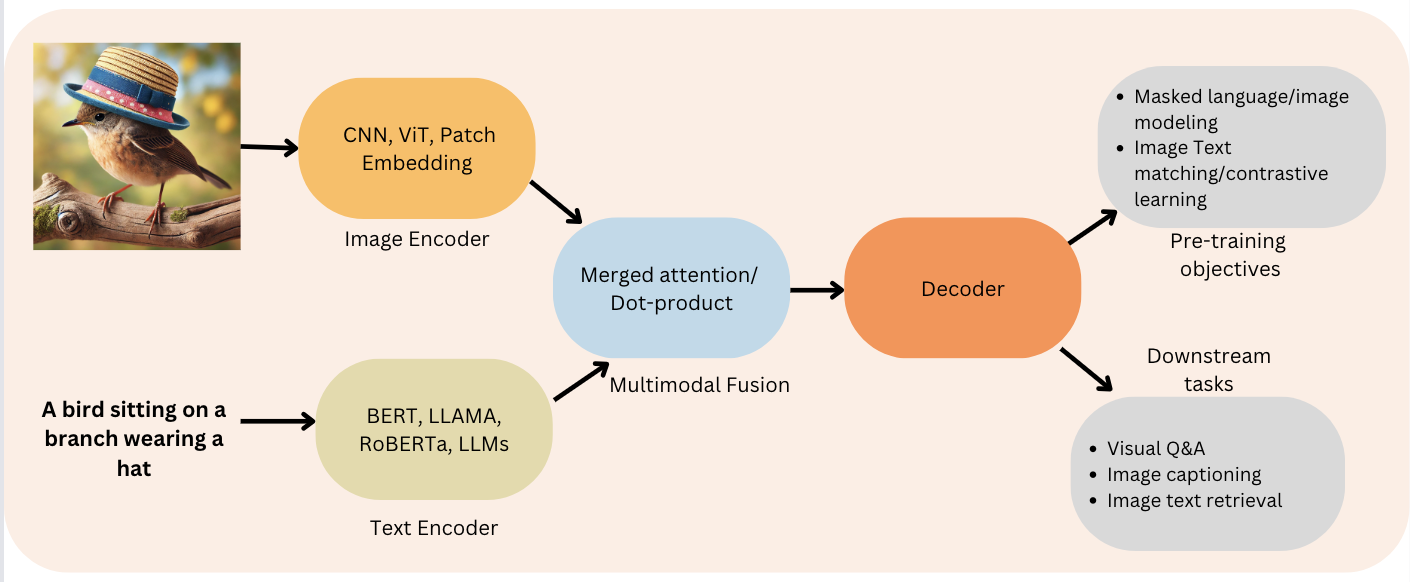
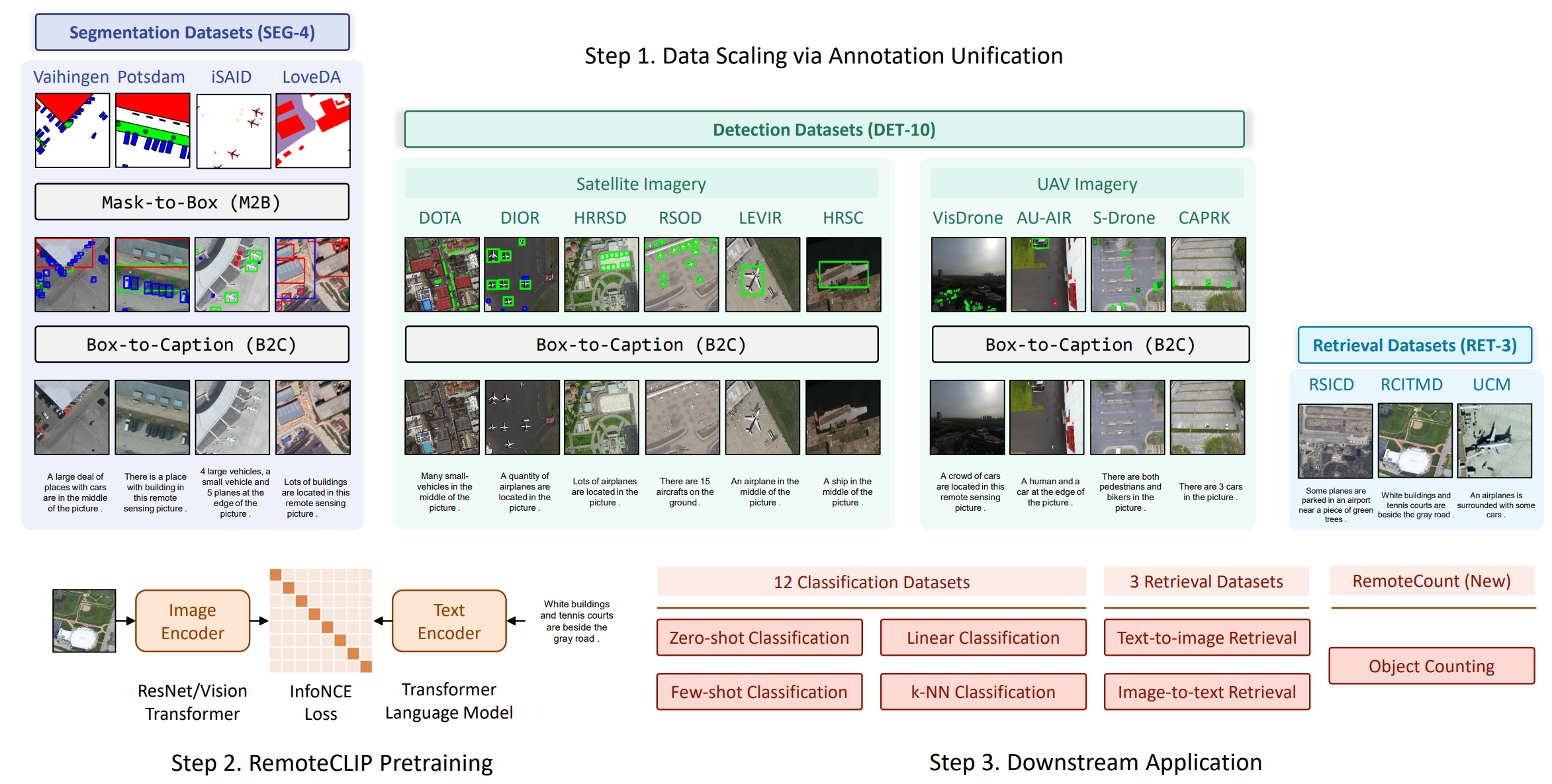
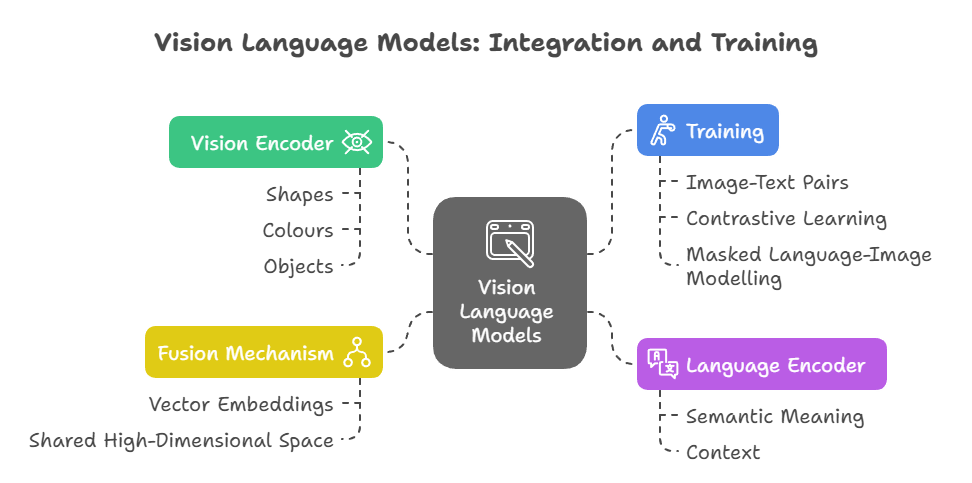








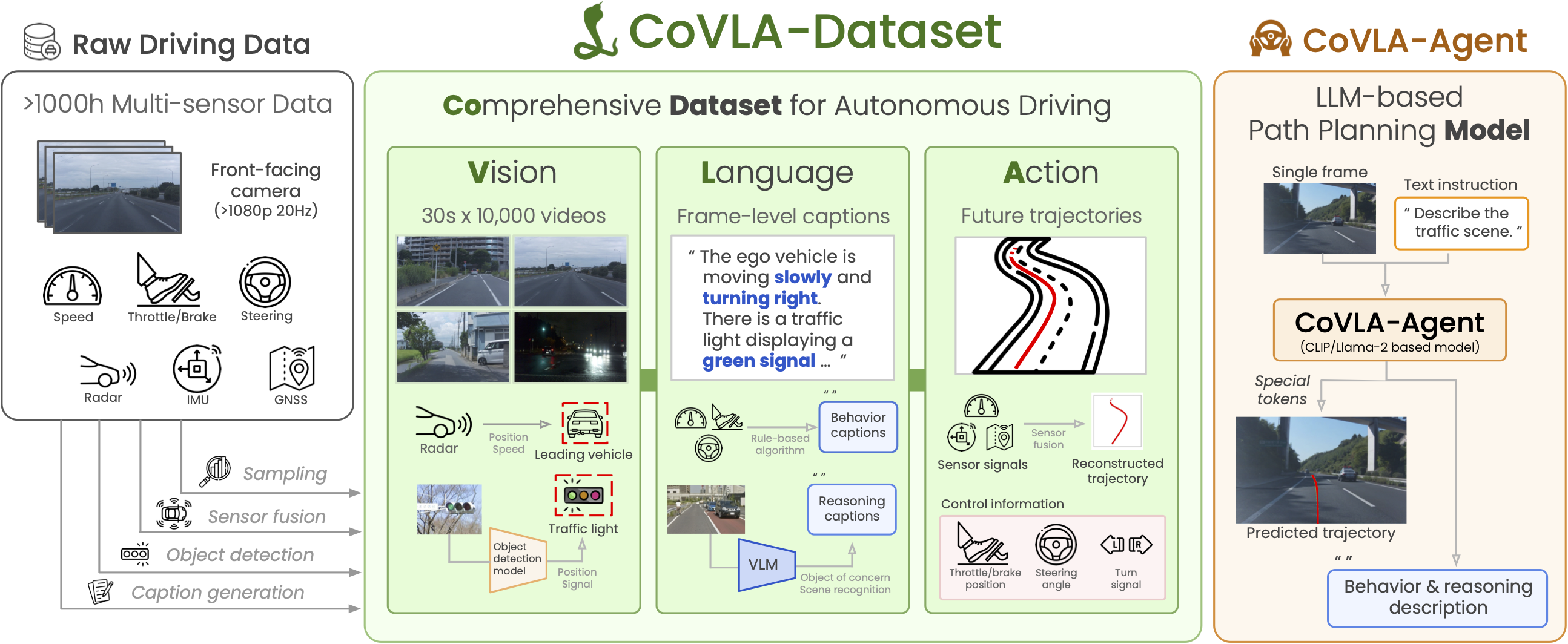



![[논문 리뷰] Sanitizing Manufacturing Dataset Labels Using Vision-Language ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/sanitizing-manufacturing-dataset-labels-using-vision-language-models-3.png)



![[논문 리뷰] Derm1M: A Million-scale Vision-Language Dataset Aligned with ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/derm1m-a-million-scale-vision-language-dataset-aligned-with-clinical-ontology-knowledge-for-dermatology-0.png)
![[論文レビュー] VSD2M: A Large-scale Vision-language Sticker Dataset for Multi ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/vsd2m-a-large-scale-vision-language-sticker-dataset-for-multi-frame-animated-sticker-generation-1.png)


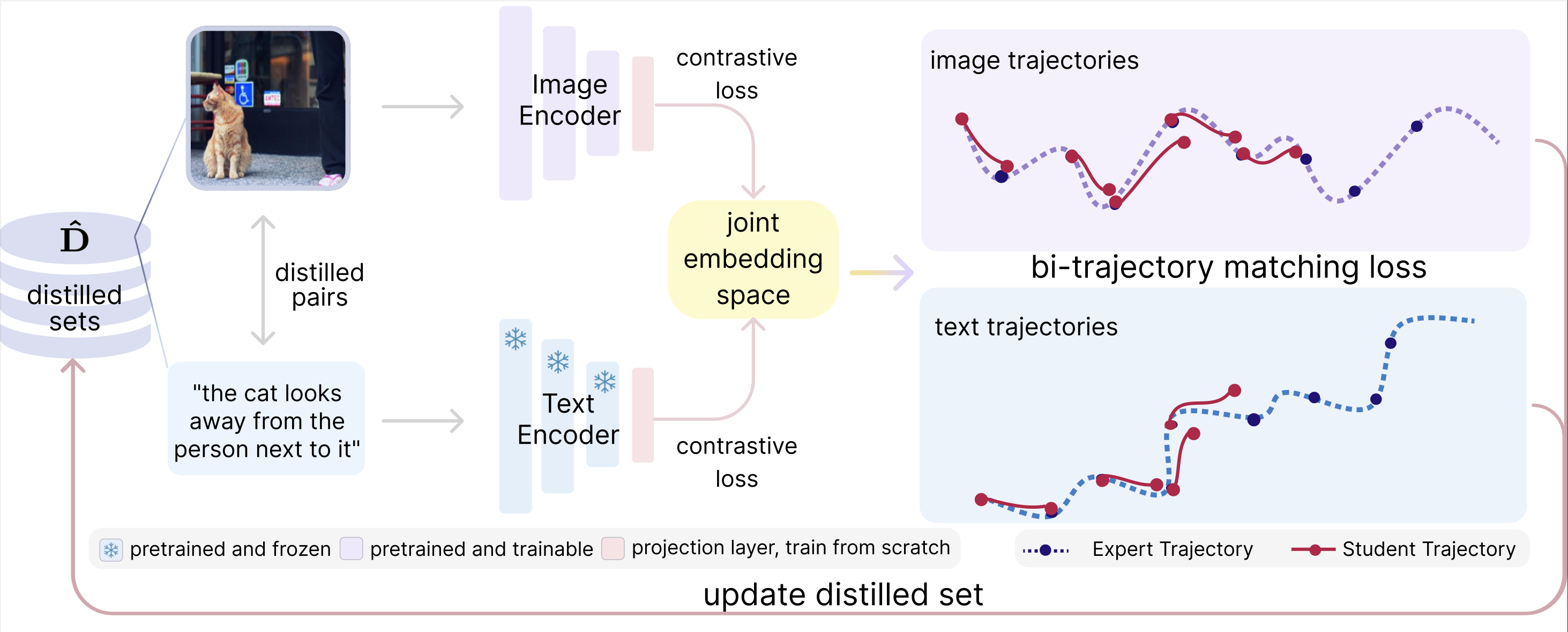



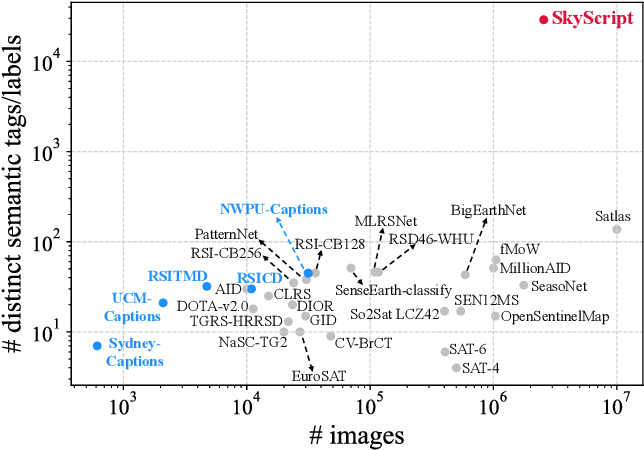
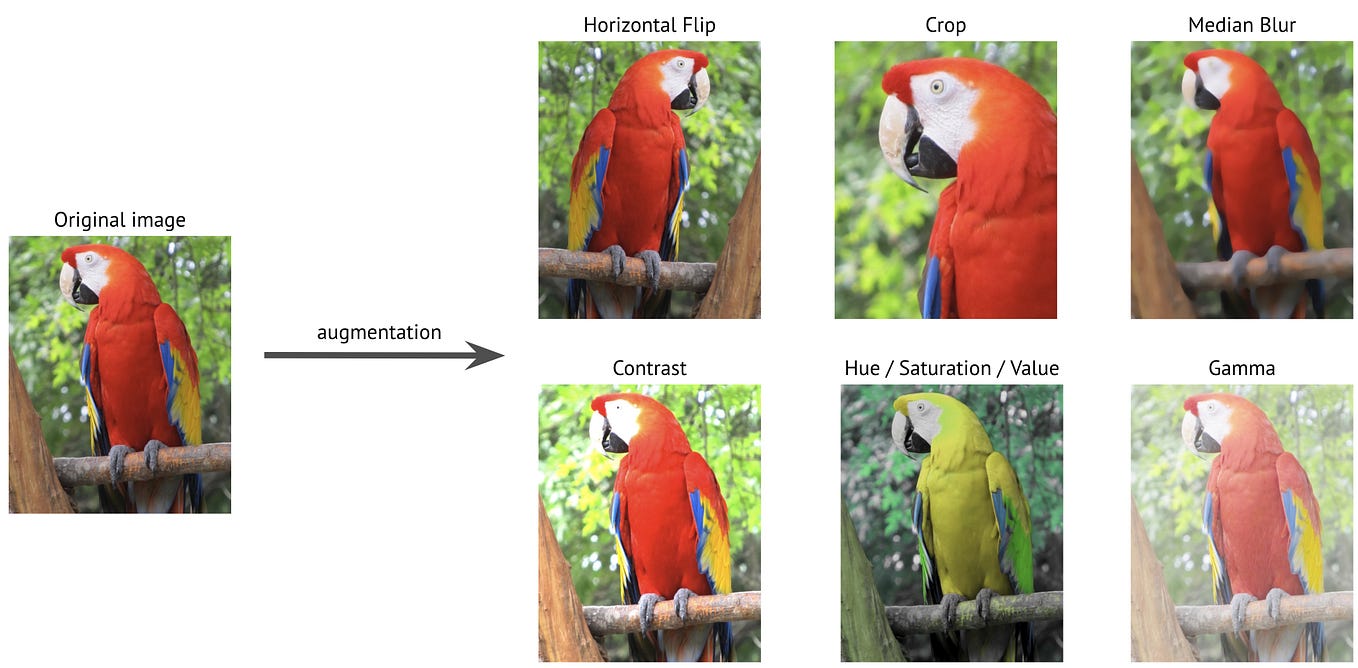

![[논문 리뷰] DisasterM3: A Remote Sensing Vision-Language Dataset for ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/disasterm3-a-remote-sensing-vision-language-dataset-for-disaster-damage-assessment-and-response-1.png)


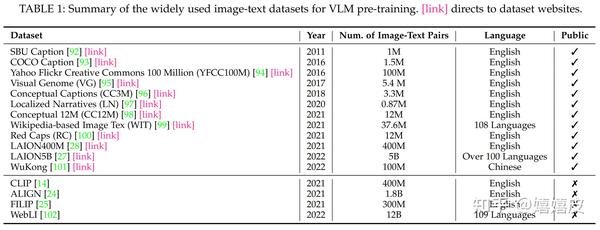

![[2304.00685] Vision-Language Models for Vision Tasks: A Survey](https://ar5iv.labs.arxiv.org/html/2304.00685/assets/x2.png)








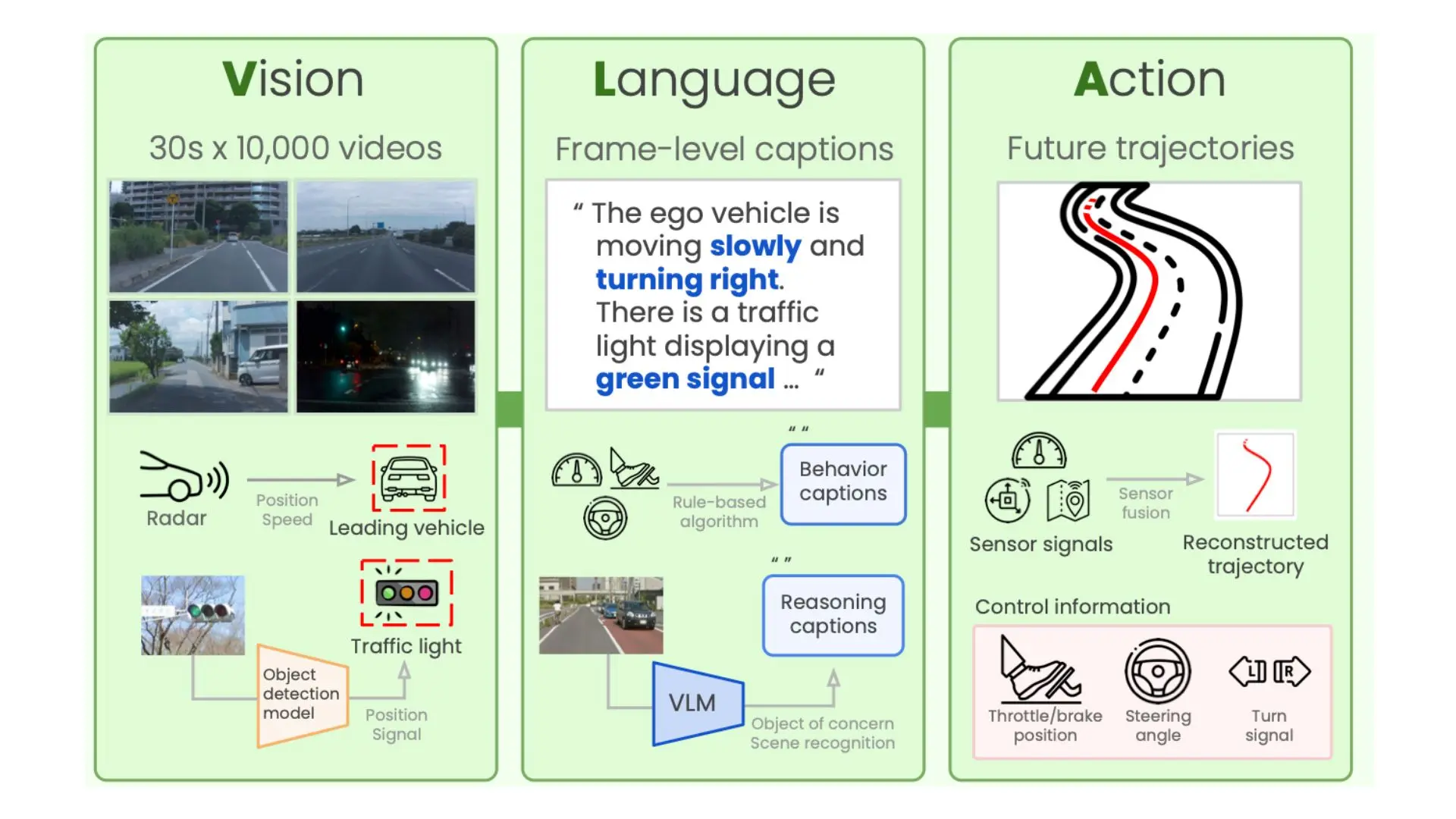
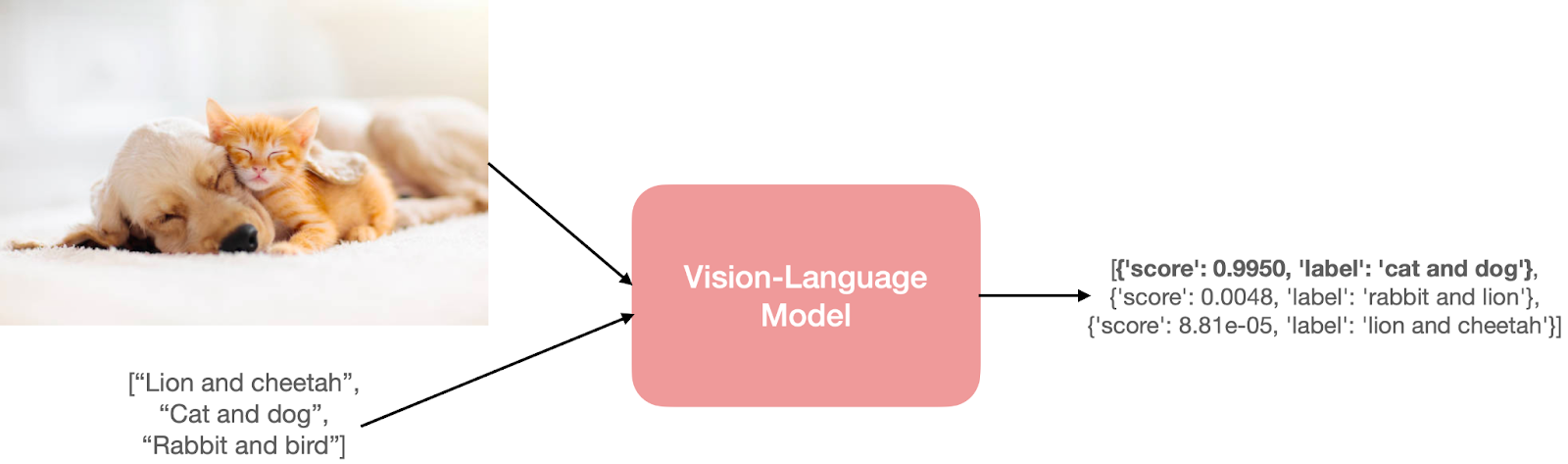


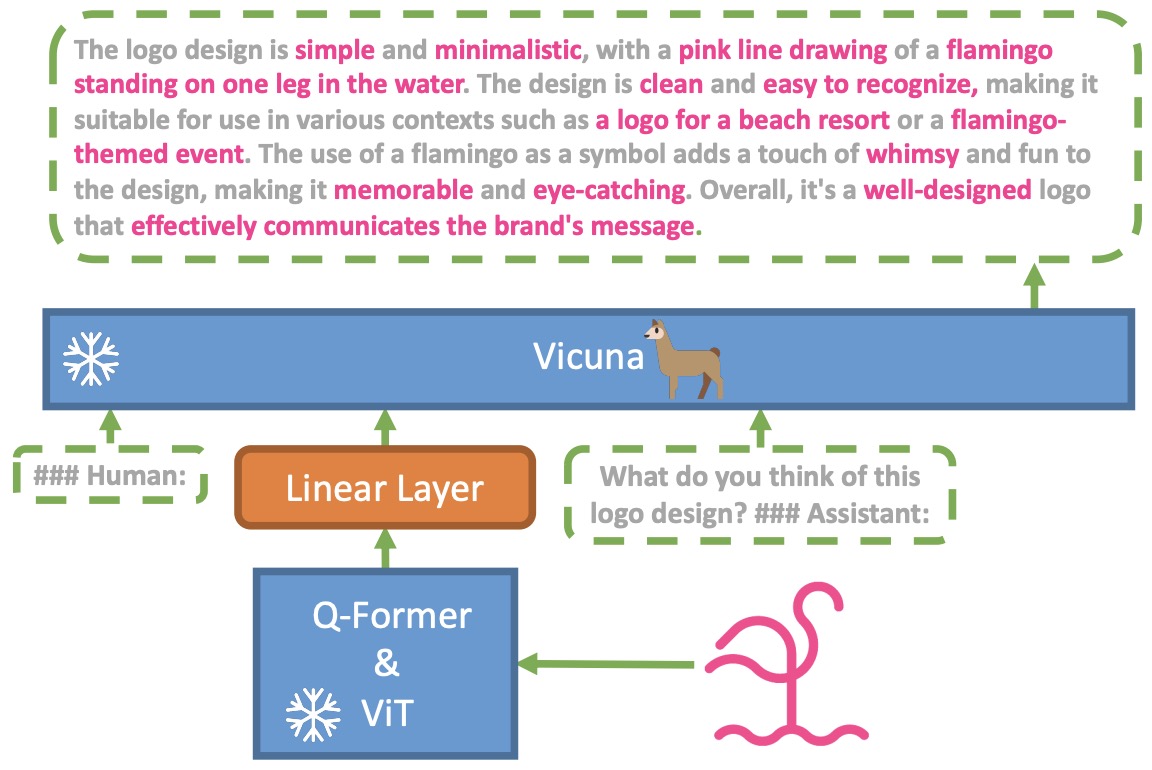
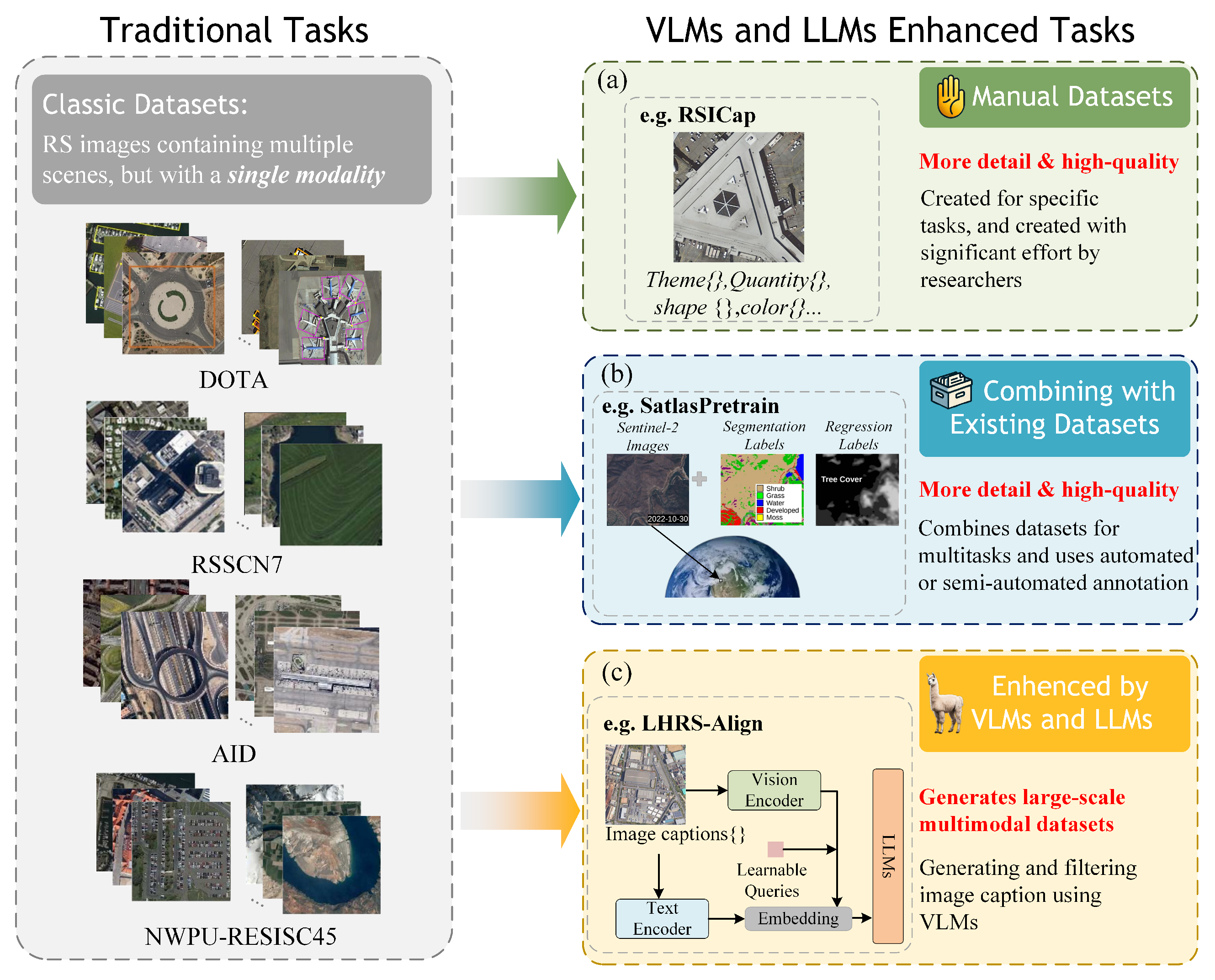
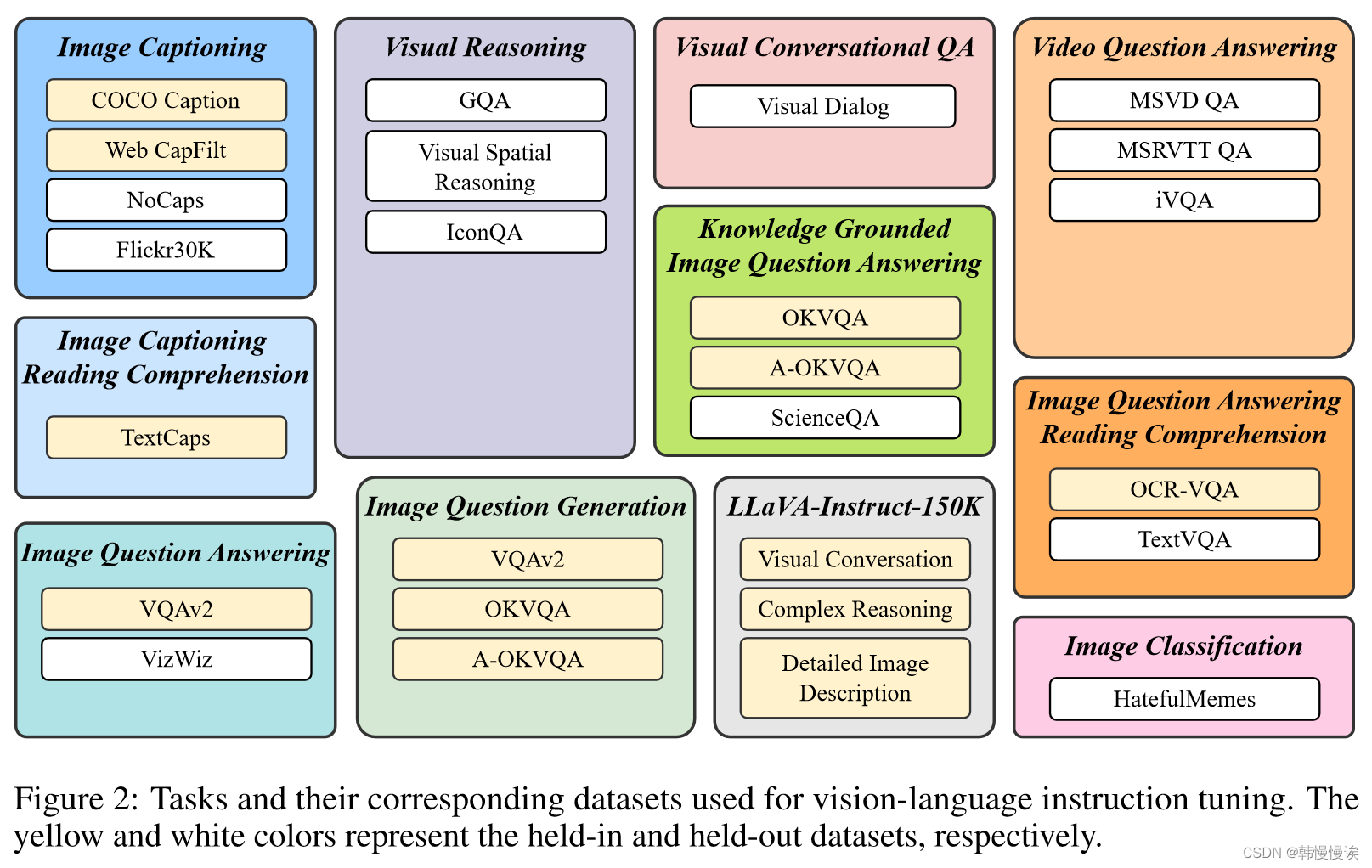
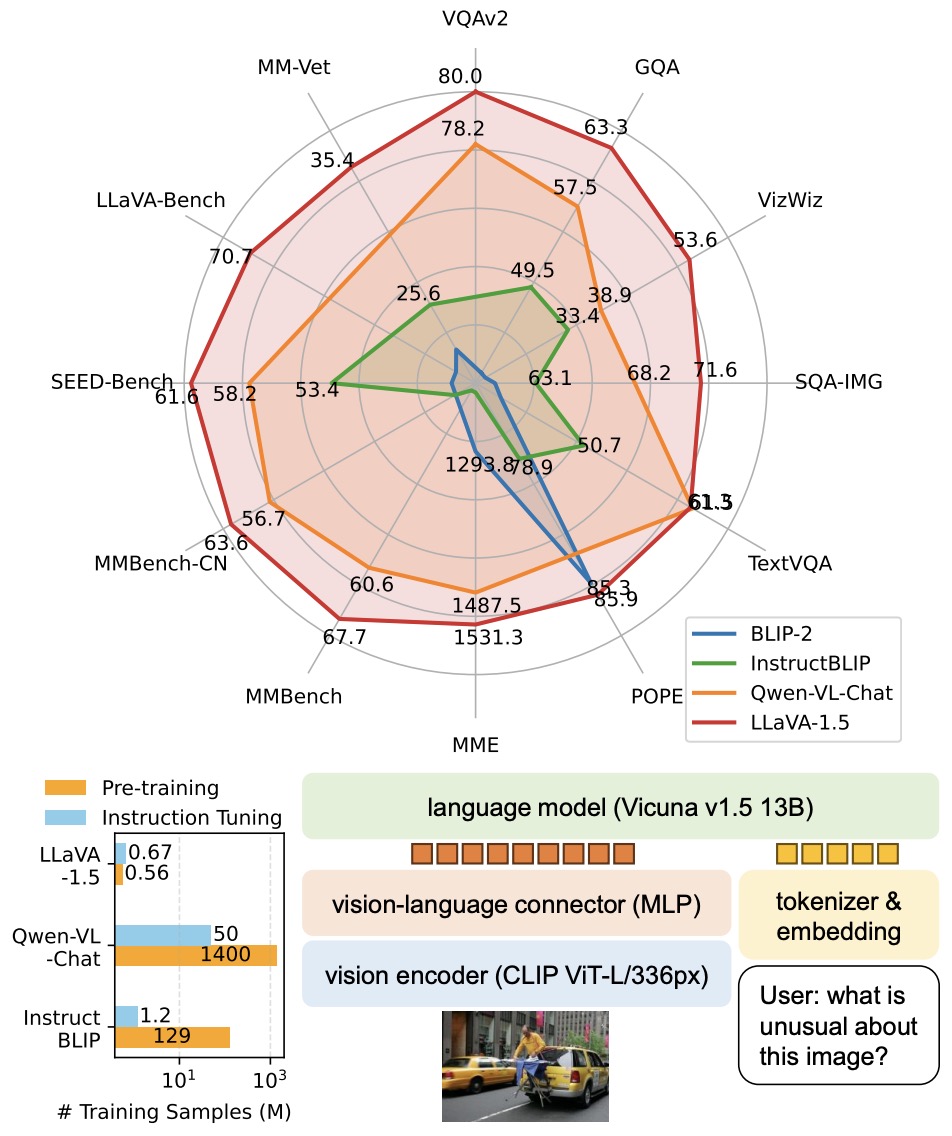
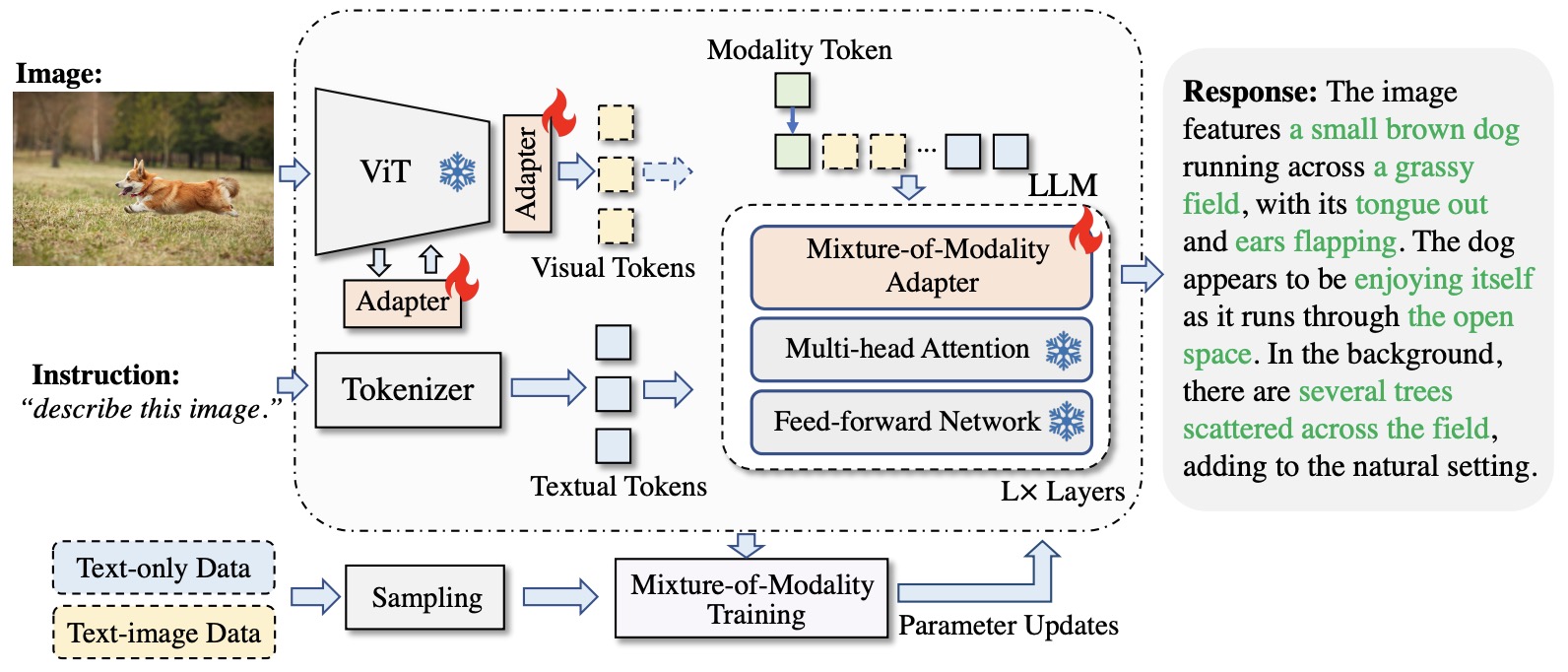

![[논문 리뷰] GAIA: A Global, Multi-modal, Multi-scale Vision-Language ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/gaia-a-global-multi-modal-multi-scale-vision-language-dataset-for-remote-sensing-image-analysis-2.png)

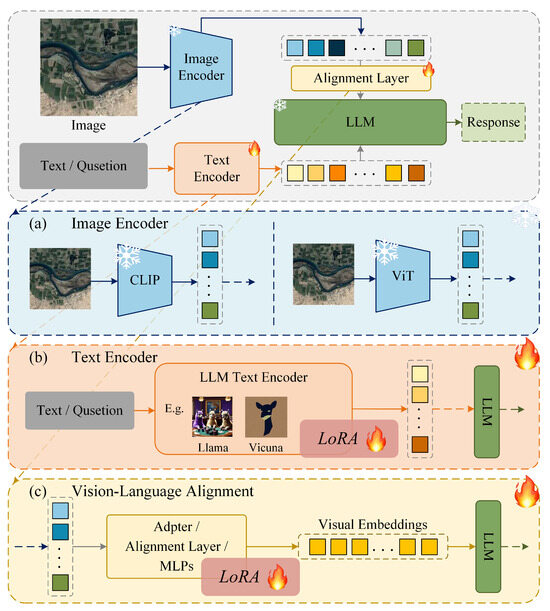

![[논문 리뷰] Towards Comprehensive Multimodal Perception: Introducing the ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/towards-comprehensive-multimodal-perception-introducing-the-touch-language-vision-dataset-3.png)



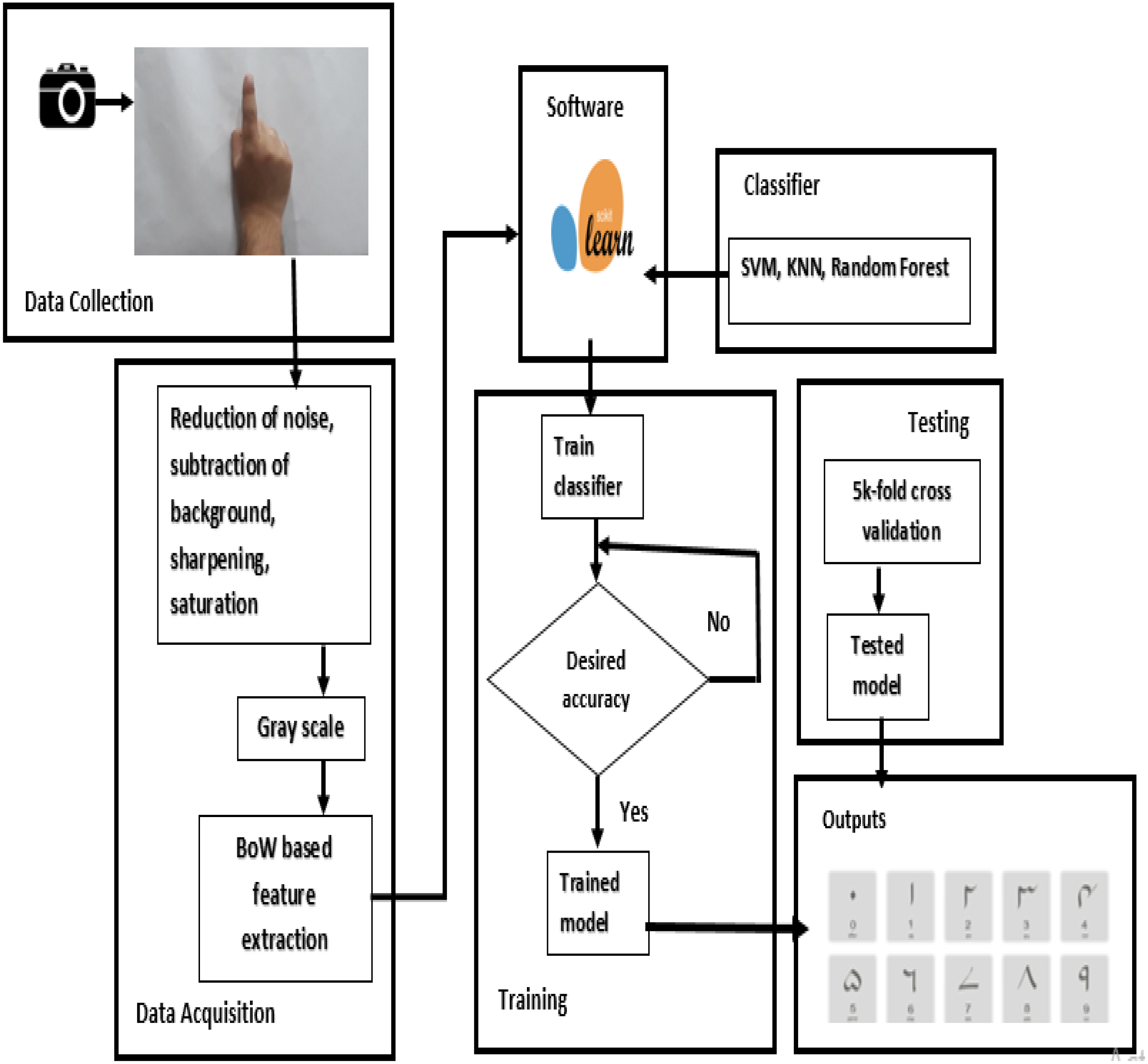
![[논문 리뷰] Measuring and Mitigating Hallucinations in Vision-Language ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/measuring-and-mitigating-hallucinations-in-vision-language-dataset-generation-for-remote-sensing-0.png)


![[논문 리뷰] Can Vision-Language Models Replace Human Annotators: A Case ...](https://moonlight-paper-snapshot.s3.ap-northeast-2.amazonaws.com/arxiv/can-vision-language-models-replace-human-annotators-a-case-study-with-celeba-dataset-1.png)





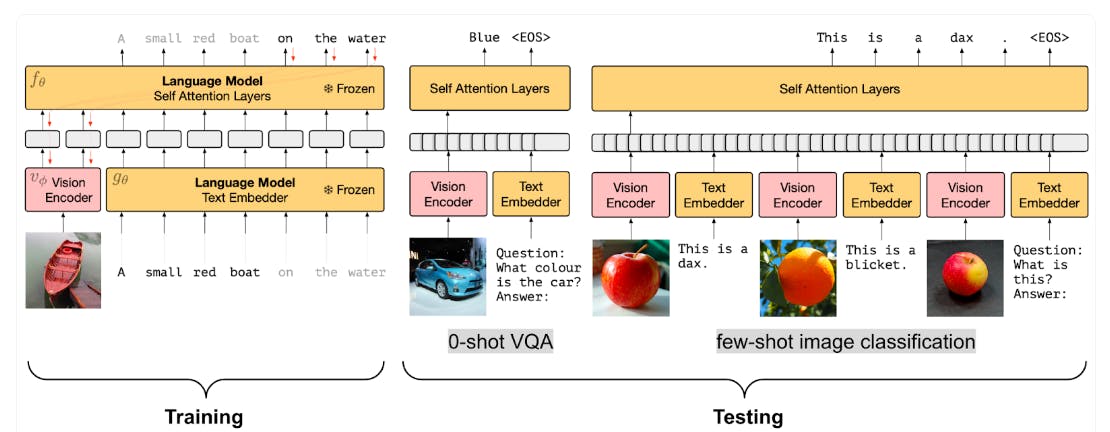


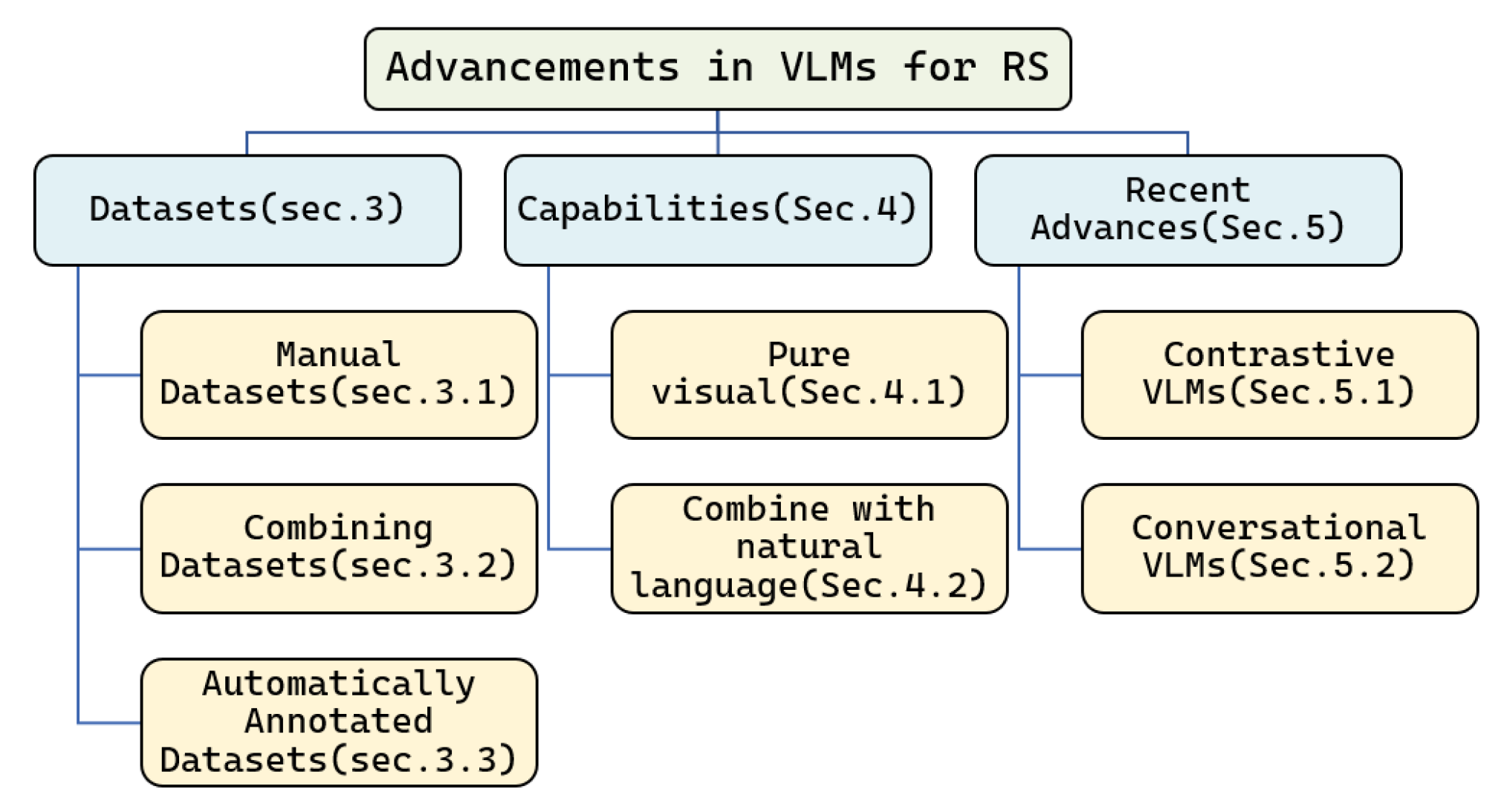



Discover the thrill of Vision Language Dataset through hundreds of breathtaking photographs. highlighting the adventurous spirit of photography, images, and pictures. designed to inspire exploration and discovery. The Vision Language Dataset collection maintains consistent quality standards across all images. Suitable for various applications including web design, social media, personal projects, and digital content creation All Vision Language Dataset images are available in high resolution with professional-grade quality, optimized for both digital and print applications, and include comprehensive metadata for easy organization and usage. Discover the perfect Vision Language Dataset images to enhance your visual communication needs. Multiple resolution options ensure optimal performance across different platforms and applications. Diverse style options within the Vision Language Dataset collection suit various aesthetic preferences. Cost-effective licensing makes professional Vision Language Dataset photography accessible to all budgets. Time-saving browsing features help users locate ideal Vision Language Dataset images quickly. Our Vision Language Dataset database continuously expands with fresh, relevant content from skilled photographers. Regular updates keep the Vision Language Dataset collection current with contemporary trends and styles. Whether for commercial projects or personal use, our Vision Language Dataset collection delivers consistent excellence. The Vision Language Dataset archive serves professionals, educators, and creatives across diverse industries.